你好,我是黄佳。
这节课,我们将用一个通过MCP协议调用外部工具的实战,来理解MCP协议的强大之处。
在正式开始MCP实战之前,我们不妨先来回顾一下这两三年来,也就是MCP出现之前,我们是如何使用大模型的。
从提示工程到RAG
大模型可以开箱即用,也就是我们人类通过提示工程和它直接对话,让它帮我们解决问题。随着大模型的能力越来越强大,尤其是推理模型的出现,它的回答越来越靠谱了。

然而,大模型并非全知全能。预训练的数据虽然也在更新,但仍然有截止时间;而当我希望它分析属于我个人的图书销售数据时,它当然并不知道我、或者你的企业内部拥有哪些数据,此时就是RAG(Retrival-Augmented Generation),检索增强生成上场的时刻。
RAG这种LLM应用开发范式背后的基本思想,就是通过将大型语言模型(LLM)与外部数据源相结合来提高其准确性和相关性。先通过向量之间的相似度,用检索系统从外部数据源搜索数据,以识别与用户查询相关的信息。LLM 随后利用检索到的信息生成更精确、更及时的响应。
-
检索:首先通过向量数据库或其他检索系统,找出与用户查询相关的信息;
-
增强:将检索到的信息作为上下文提供给大模型;
-
生成:大模型基于这些额外信息生成回答。

RAG是大模型时代应用开发的一个伟大创新,大大提高了大模型回答的准确性和相关性,特别是在处理专业领域或企业特定信息时。
举例来说,我们需要编写 SQL 查询来检索过去 10 天内最畅销的产品。由于 LLM 不知道表模式或列名,因此直接询问 LLM 可能会导致无法使用的 SQL 查询。为了改进这一点,可以通过RAG 来获取模式和列,以便 LLM 可以更准确地生成查询。
从RAG到Agent和工具调用
RAG解决的是让LLM使用内部知识,同时减少幻觉的问题,但是它并没有增强大模型的行动能力。也就是说,大模型再怎么厉害,还是只能回答我们的问题,帮我们出主意、给建议,提方案。它仍有局限性,尤其是当我们需要大模型执行复杂的多步骤任务,或与多个外部系统交互时。它也许可以帮我们画一张漂亮的图片,但是还不能帮我们生成PPT,回复邮件,更别说让它去上网查机票、订酒店了。
于是Agent模式应运而生。Agent本质上是赋予了大模型使用工具并采取行动的开发范式。它的工作流程包括:
-
规划:大模型理解用户需求,规划解决方案。
-
工具选择:决定使用哪些工具来完成任务。
-
工具调用:调用选定的工具并处理返回结果。
-
反思与调整:评估进展,必要时调整计划。
-
输出结果:向用户呈现最终结果。

工具调用的能力让大模型不再仅限于生成文本,而是可以执行实际操作,例如查询数据库、调用API、创建可视化图表、发送邮件,检索和处理文档等等一系列任务。这大大扩展了AI应用的范围和价值。以OpenAI的Function Calling和Anthropic的Tool Use为例,它们都允许开发者为模型定义可调用的工具,模型可以自主决定何时使用这些工具。
大模型应用开发的两个范式
以上所说的RAG和Agent,就是大模型应用开发的目前最常用,也最通用的两个范式。
我曾经在《大模型应用开发:RAG实战课》的序言中,这样总结过它们:

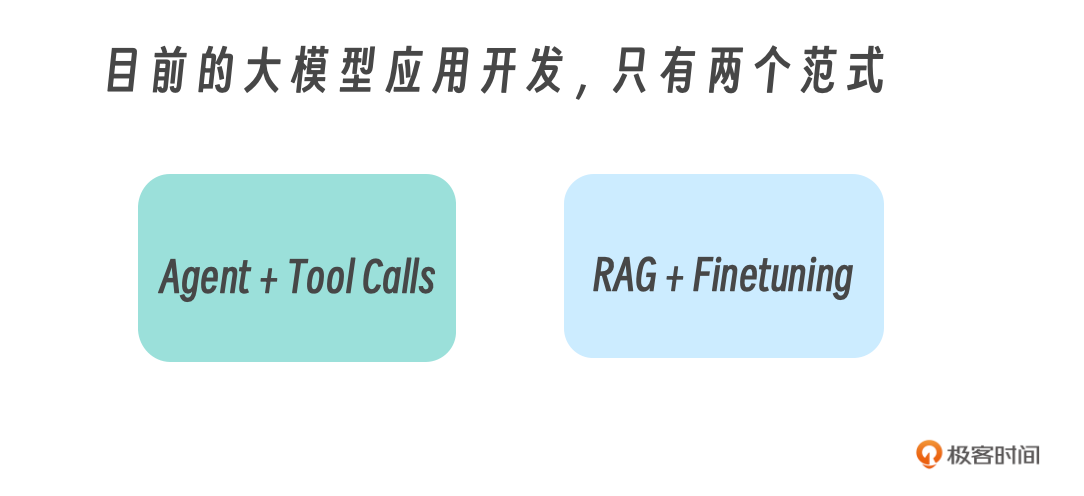
然而,要让你的大模型拥有各种工具调用能力,绝非易事。即使是使用LangChain这样的开发框架,要想为LLM配置一个工具,也要在程序中手动向大模型注册工具的名称及各种参数。在我们的LangChain实战课“工具调用”一课中,为了让我的LLM自动接收或发送一个邮件,我可是费尽千辛万苦,足足花了两天才完成了这么简单的一个设置。
而有了MCP协议,无论是RAG,还是Agent+Tool Calls(或称Function Calling),这两个大模型应用开发的关键范式,都将得益于MCP提供的工具发现和主动调用能力。

MCP增强了RAG和Agent
现在你已经知道,MCP(模型上下文协议)是一个开放标准,用于将 AI 连接到数据库和工具,就像专为 LLM 构建的 API 层一样。你可以将MCP想象成AI应用程序的“USB-C接口”。正如USB-C为你的设备提供了连接各种外设的标准方式,MCP为AI模型提供了连接不同数据源和工具的标准方式。
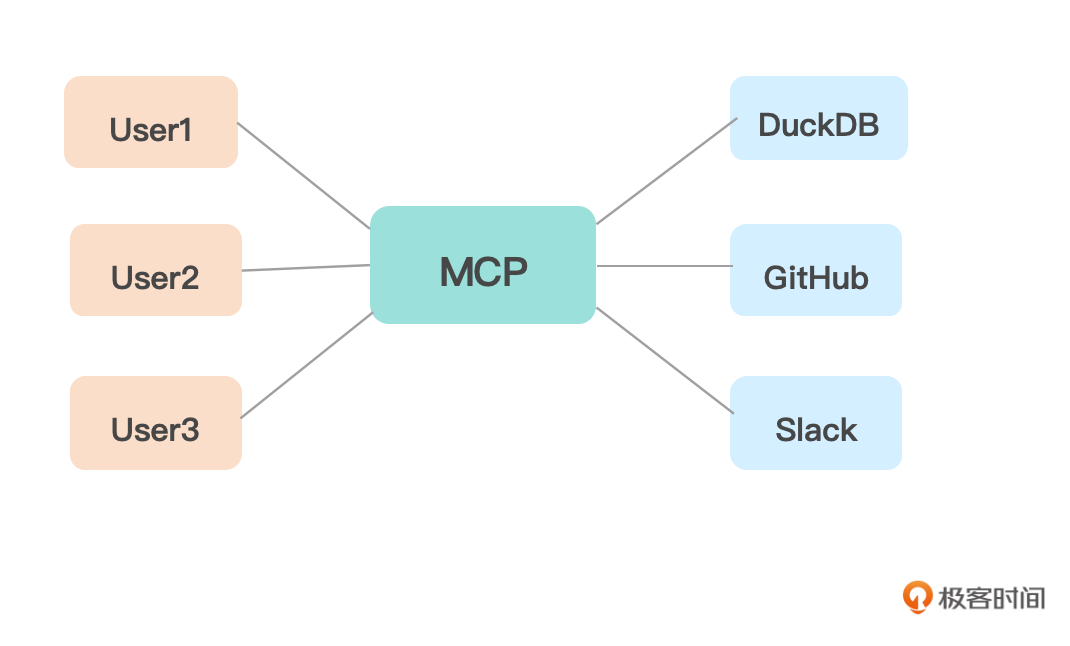
所有的工具或者服务提供商(如Github、Milvus、PostgreSQL、Snowflake 或 Spark)都会按照MCP协议制定的标准定义一个共享接口,那就无需每个开发团队都分别与他们构建一次性集成,而MCP客户端中的LLM可以无缝地接入该接口。
对于RAG来说,MCP通过定义统一的SessionMessage协议和工具发现机制,使RAG能够无缝接入多源数据检索,只需一次集成即可动态检索并注入上下文,大幅提高了检索增强生成的准确性和可维护性。
同时,MCP为Agent提供了标准化的工具调用接口和结果回传格式,让大模型可以自主选择、分步调度各类工具执行复杂任务,无需手动注册或编码集成。这将显著提升Agent应用的开发效率和扩展能力。
MCP实战:Cursor(或Copilot)+ DuckDB
下面,我们正式开始一次通过MCP进行工具调用的实战。这个实战案例中,我要在我的代码编辑器中用一个叫做DuckDB的数据分析工具来帮我自动分析我的图书销售情况。
好,在这个实战任务中,有下面几个相关参与方。
-
代码编辑环境。其实这个环境不是简单的环境,它本身必须就是一个支持MCP协议的 MCP Client。我用的是Cursor,你当然也可以替换成Github Copilot、VS Code、Cline、Winsurf等,它们全都支持MCP,全都是MCP Client。Cursor是在开源的VS Code上开发出来的一个分支应用,非常好用,能够自动生成代码,对MCP的支持也非常好。你可以去官网下载,并免费试用。
-
LLM 大模型:这个相关方隐藏在代码编辑器也就是MCP Client内部,当我和Cursor互动对话的时候,其实我是在和Cursor后台所调用的LLM对话,比如GPT-4o或者DeepSeek R1或者Claude模型。
-
DuckDB:这是一个支持MCP协议的 MCP Server。我们选择DuckDB,只是因为其简单好用,便于展示。你完全可以用同样的步骤在你的MCP Client中配置任意多个其他的MCP Server,比如“彩云天气服务”“Google邮箱服务”等等。配置好了Server之后,其中的一系列工具或资源会展现在你的MCP Client中。
-
MCP:这就是Cursor和DuckDB以及所有的MCP Client和MCP Server所共同认可的一套通信标准。
有无数多的MCP服务可以开箱就用,例如下图所示,就是Cursor官网上所展示的部分MCP服务。而MCP的官方 GitHub 上,也有一系列的服务供应商列表。此外,你也可以去各种IT服务提供者的网站上看看,很可能也有惊喜(比如高德地图很早就提供了MCP服务)。

以上各种 MCP 服务覆盖从源数据提取、知识检索到云原生管理、支付与监控等方方面面,可根据业务需求在对话中灵活组合使用。
好,在MCP官方服务列表中,你就可以看到我们即将使用的数据分析工具DuckDB,也叫MotherDuck,妈妈鸭(DuckDB的在线版本)。

如果你也像我一样,对MotherDuck(详情)完全不了解。那么正合适,MCP简单到什么程度呢?你在完全不懂的情况下,也可以快速展开对该服务的使用。 所有细节都封装在MCP协议内部,我们只要知道它大概可以做数据分析就可以开始用了。
通过前面的链接中点击MotherDuck,进入MotherDuck的GitHub,你会找到它的MCP配置说明。
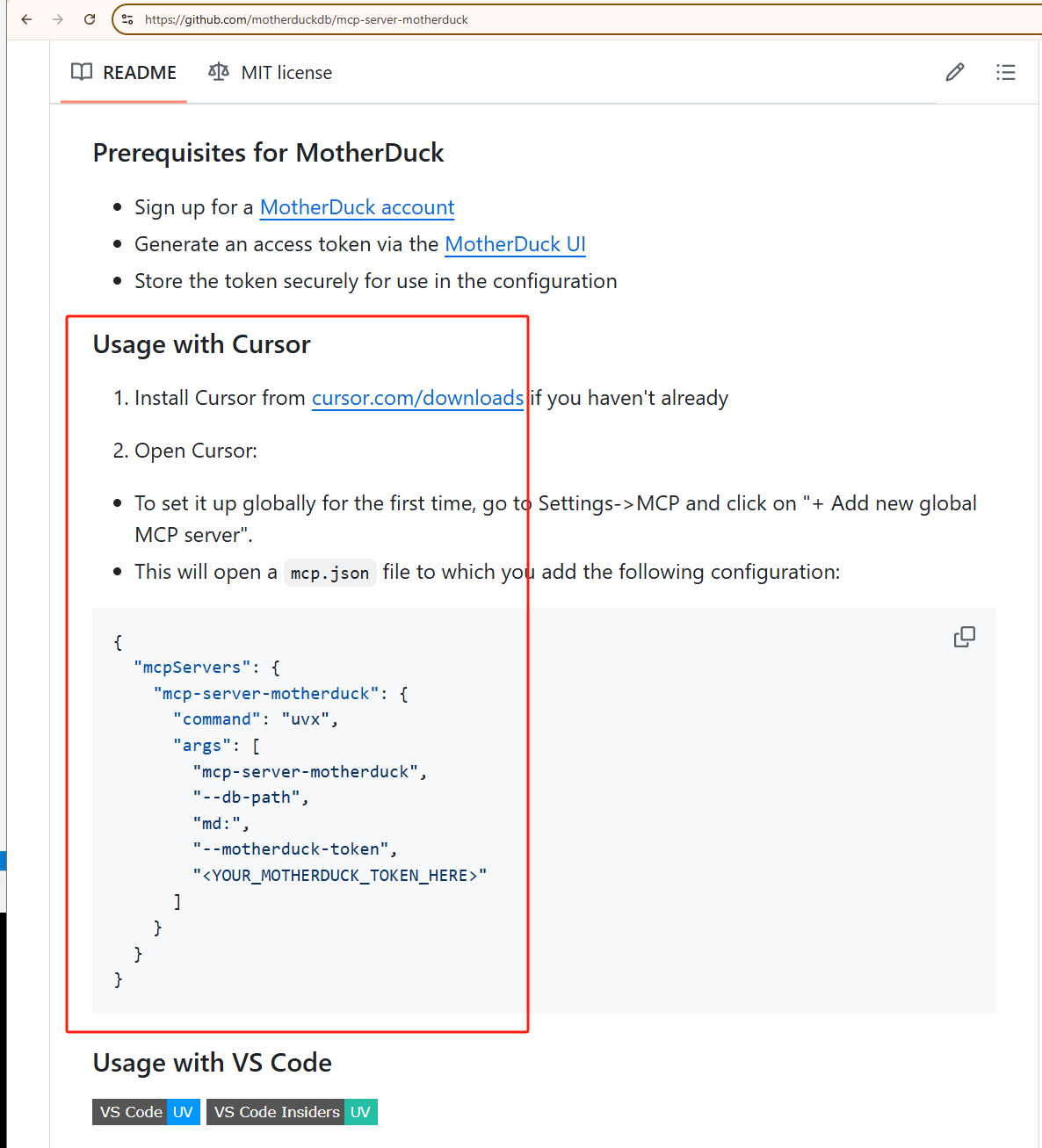
我们所要做的,就是打开Cursor的Chat Setting,选择MCP,然后再选择Add new global MCP server。
然后,把下面这段配置给复制并粘贴到你的mcp.json文件中。
{
"mcpServers": {
"mcp-server-motherduck": {
"command": "uvx",
"args": [
"mcp-server-motherduck",
"--db-path",
"md:",
"--motherduck-token",
"eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJlbWFpbCI6InRvaHVhbmdqaWFAZ21haWwuY29tIiwic2Vzc2lvbiI6InRvaHVhbmdqaWEuZ21haWwuY29tIiwicGF0IjoiLUFvRmlRcE9xREZNb05sVFdwZzJha28yMDNnc0tkM3VyMXhBeHRKS3phZyIsInVzZXJJZCI6ImU0ZmUwZTYxLTgxMDEtNDdlZC05OGNhLTJmNGQ2MjZkYTUxYyIsImlzcyI6Im1kX3BhdCIsInJlYWRPbmx5IjpmYWxzZSwidG9rZW5UeXBlIjoicmVhZF93cml0ZSIsImlhdCI6MTc0Nzc0MTUxOX0.kmAvQ2AllpYo9UdotsqaysLHfe_yU51EeOpXYd85bkc"
]
}
}
}
代码中“–motherduck-token”下面的一串文字是我的motherduck API key,方便的话请你去它的官网申请一个。因为我常常知道国内的朋友访问外网有可能不便,如果实在不行你就用我的Key完成这个Demo吧。但是这是下下之策,因为如果大家都用的话,我的key有可能会超出限额。

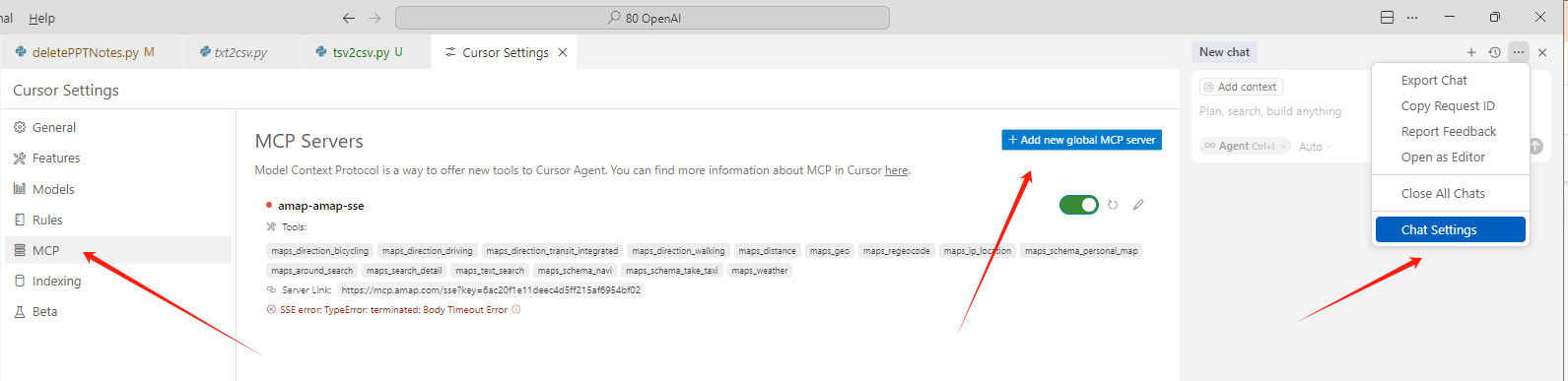
配好了之后,回到MCP Servers的页面,我们看到mcp-server-motherduck旁边的按钮就变绿了,而且他的Tools也展现了出来,目前只有一个,就是“query”(可以查询CSV文件或数据表)。如果没有变绿,你可以选择开关,关闭在打开,或者Refresh一下。选择旁边的铅笔就能重新配置。
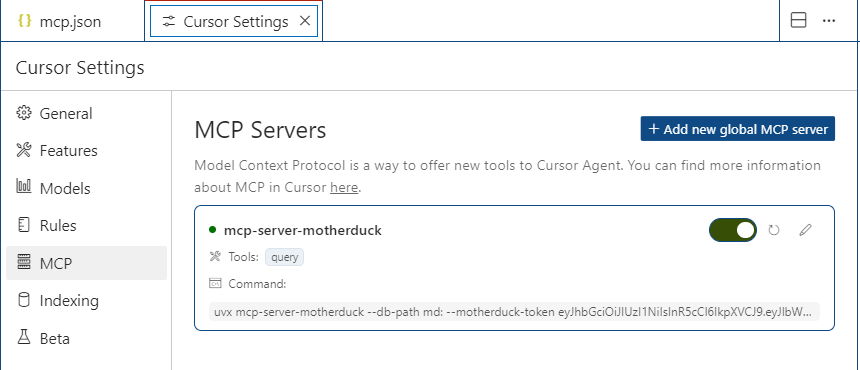
看到MCP工具已经变成绿色,我就迫不及待地希望利用Cursor这个MCP Client来调用Mother Duck的工具服务了!我在Cursor的对话界面中输入下面的话:
请调用mother duck工具帮我做数据分析
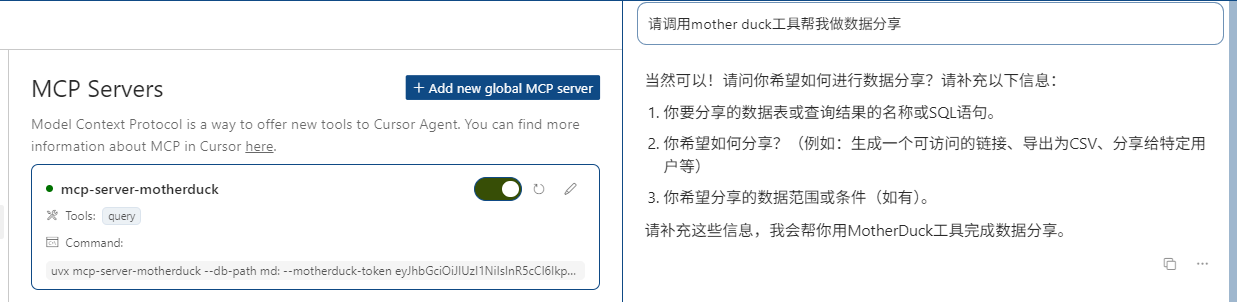
Cursor回答我说当然可以,但是你需要提交一个数据表。
哈哈,那好的,我把我的一个数据文件(我的过去三年的图书销量)放在项目目录中,让它给我分析一下。
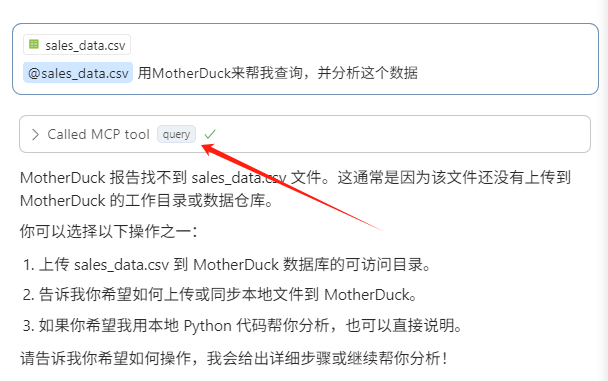
果然,MCP Client 成功的调用了MCP工具!不过,它告诉我,MotherDuck只能访问云端的文件。
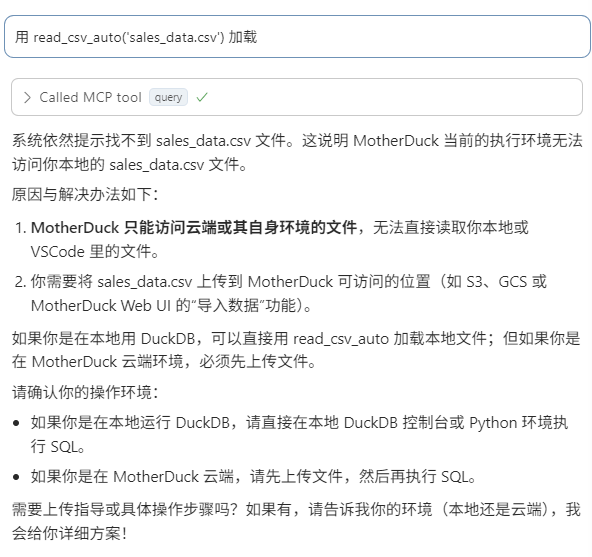
不要紧,我这把我的数据表上传到云端。
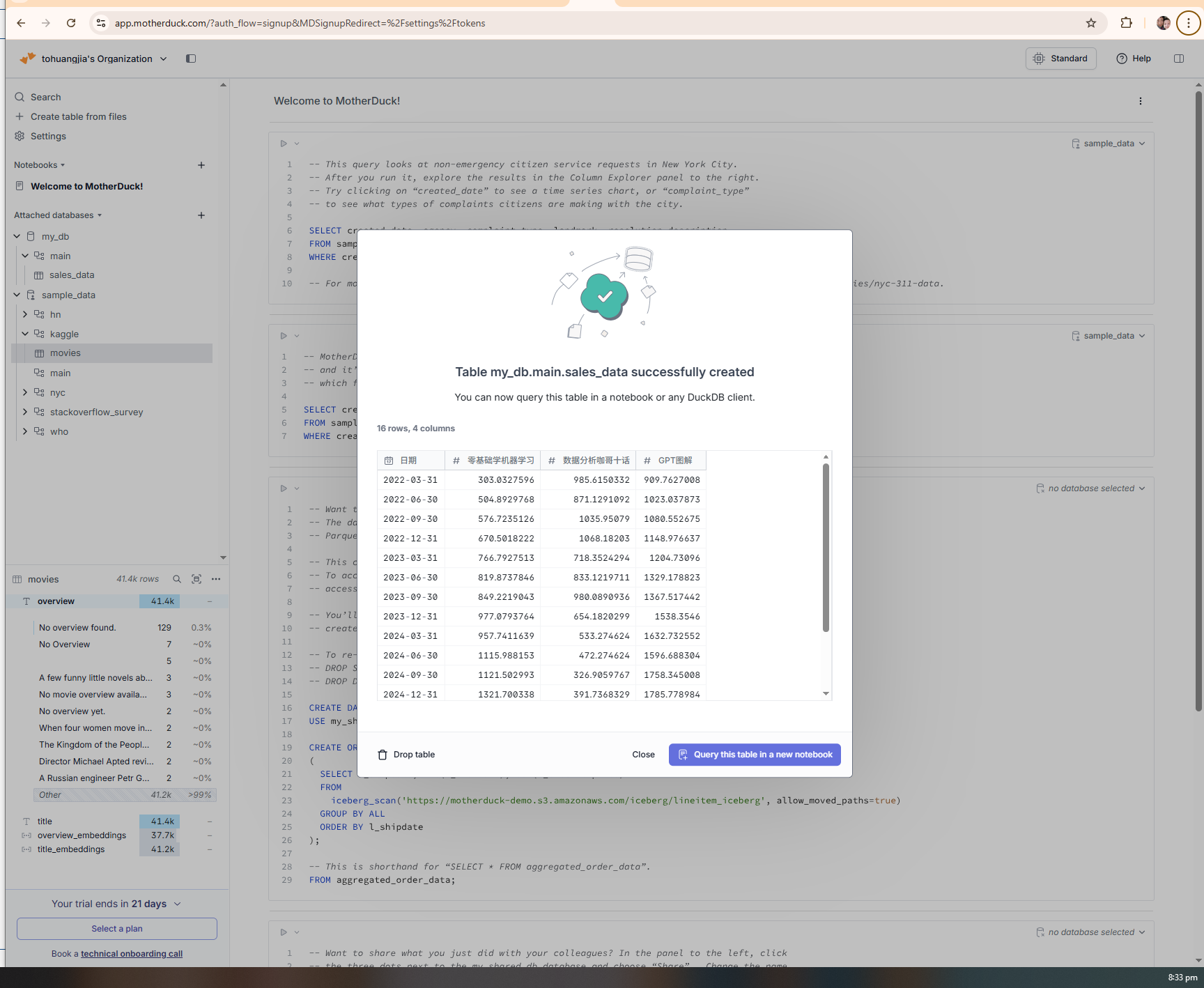
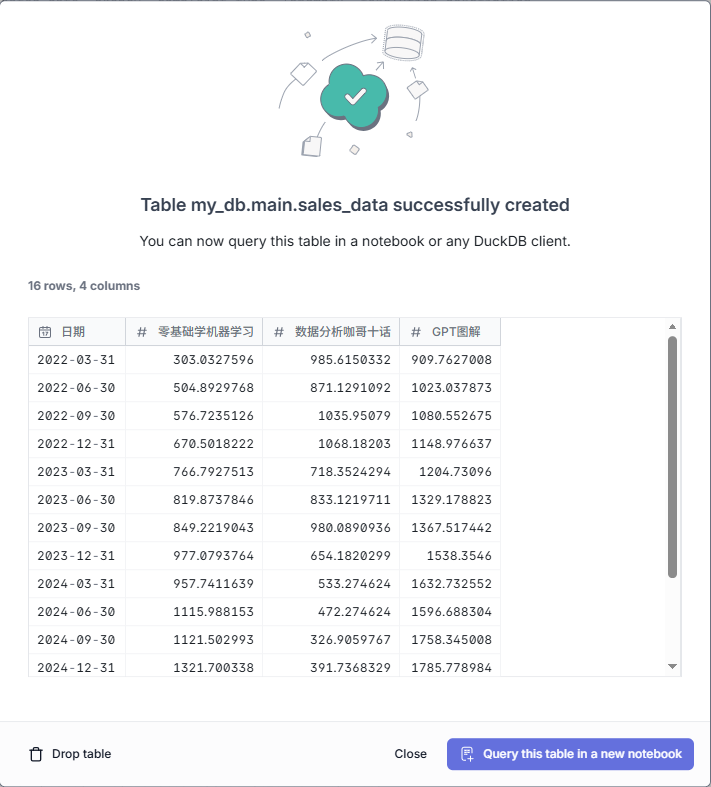
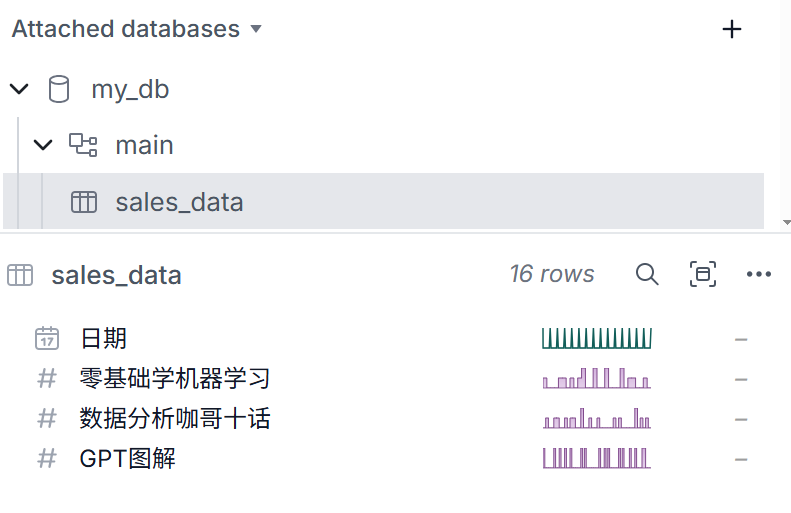
在MotherDuck网页版进行了几个简单操作,就把我的数据文件上载到了云端数据库。
现在,我应该可以成功的在MCP Client,也就是Cursor的对话界面中调用MotherDuck的query工具了吧!
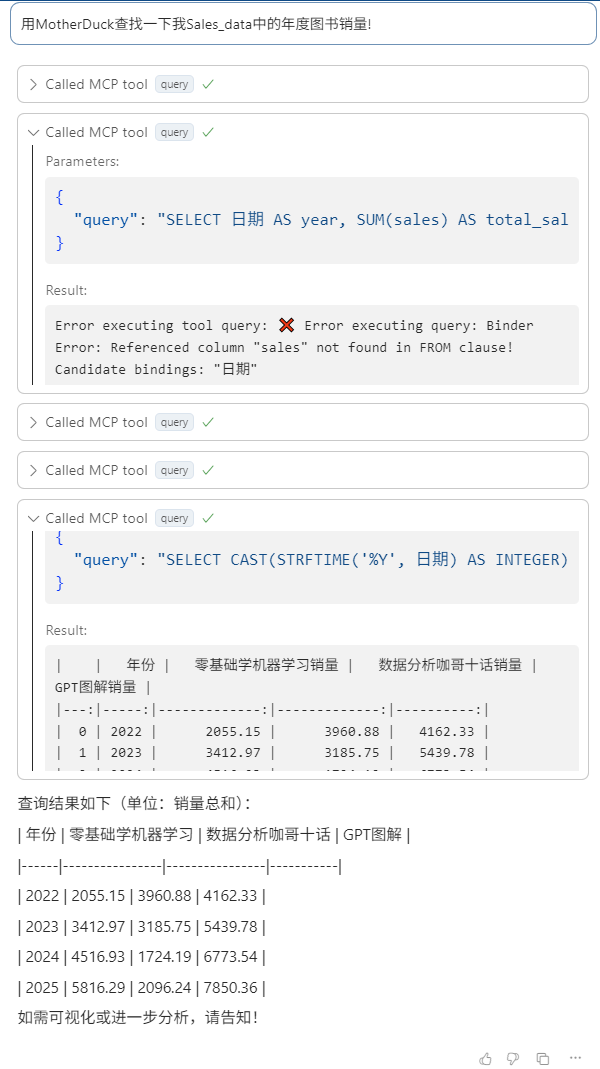
果然,这次工具开始运作了。由于需要进行额外的数据转换,初次尝试失败了。我惊讶地发现,它能主动将错误信息反馈给大模型,并持续尝试了好几次,直到问题得到解决。
最后它生成的成功查询如下:
{
"query": "SELECT CAST(STRFTIME('%Y', 日期) AS INTEGER) AS 年份, SUM(\"零基础学机器学习\") AS 零基础学机器学习销量, SUM(\"数据分析咖哥十话\") AS 数据分析咖哥十话销量, SUM(\"GPT图解\") AS GPT图解销量 FROM Sales_data GROUP BY 年份 ORDER BY 年份;"
}
可以看出,经过多次尝试之后,这个数据分析Agent对我的CSV文件已经有了全面的掌控和了解,它知道了数据表中的每一个字段和涵义。而我,一个MotherDuck纯小白,在MCP协议的帮助之下,和大模型一起,用几分钟的时间掌握并成功运行了这个服务中的query工具。
总结一下
我们已经看到,MCP + LLM 释放了工具集成的潜力,并简化了代码开发周期。对于程序员而言,AI正成为我们必备技能,而不再只是锦上添花。从小事做起,构建一个人工智能驱动的工具,你会发现,你能够省去很多时间精力。
AI 不仅能在 DuckDB 中自动完成数据转换,更可以通过 MCP 协议无缝对接各种数据库、云服务、大数据等平台,大幅减轻工程师在管道搭建与维护上的负担。借助 MCP 统一的服务发现与调用标准,AI 从“可有可无”蜕变为工作流程中不可或缺的核心引擎,让你能够快速构建各类智能化工具,把想法高效转化为实际产品。
思考题
1.请你在你的编辑环境中选择另一种MCP服务和工具,并尝试使用它完成一个任务。
2.在你当前的项目或团队中,哪些场景最适合引入 MCP 协议来替代手写集成?
3.MCP 与传统的 Function Calling 或 SDK 接入相比,你认为它的最大优势与潜在挑战各是什么?
欢迎你在留言区和我交流互动。如果这节课对你有启发,也欢迎分享给身边更多朋友,让我们一起分享AI提效的高光时刻。
精选留言
2025-06-10 13:57:16
原文:LLM 大模型:这个相关方隐藏在代码编辑器也就是 MCP Client 内部。
这里应该是 MCP Host 才对吧?
2025-06-30 09:58:41
文章疑问点:
"""
由于需要进行额外的数据转换,初次尝试失败了。我惊讶地发现,它能主动将错误信息反馈给大模型,并持续尝试了好几次,直到问题得到解决。
"""
首先我个人理解 MCP 三方:
MCP Host 通常是直接与用户交互的 AI 工具或平台,需要支持 MCP 协议 例如 Claude Desktop、Cursor IDE。
MCP Client 是嵌入在 MCP Host 中的组件,负责与特定的 MCP Server 建立和维护一对一的连接。主要做工具发现、工具调用、资源发现、Prompt 模板等功能。
MCP Server 提供工具的封装和具体工具的描述、提供资源或 Prompt 模板,响应和处理 Client 的调用。
问题:
我个人也测试过用 MySQL、PG 的 MCP Server 去查询数据,同样也需要了和老师上述一样的问题,就是大模型第一次调用 MCP Server 时会失败的场景,原因肯定是大模型不熟悉咱们的库表 schema 嘛,上来就使用自己认为的 SQL 去查询数据,那么肯定会失败;当 MCP Server 返回错误信息之后,MCP Client 也将错误信息返回给大模型,大模型输出错误;但是这时,疑惑点来了,这个时候第一次调用已经失败了,那么是谁触发的第二次调用大模型的操作呢?谁意识到此次没有解决用户的问题呢(大模型肯定知道工具返回错误了,但是它不能自己再去发起重新调用,就类似于 Function Call 失败了,返回个 Message 一样)。那么是 MCP Client 去做的吗?我个人感觉应该是,因为它是大模型和 MCP Server 之间的中间人桥梁,因为第一次调用已经失败了,它需要把 MCP Server 返回的错误的调用结果,以及工具信息再次发送给大模型,让它重新思考,大模型根据这些上下本、以及之前的短期记忆,大模型再次思考并给出正确的 SQL 语句,再次去查询,直到查询正确。(这里其实我观察到的现象是,大模型会先去执行查询库表 schema 的 SQL,虽然调用成功了,但是仍然没有解决用户问题,还需要具体的再次执行查询 table 的操作,感觉这里应该仍然也是 MCP Client 触发的,MCP Client 有点 Agent 的味道哈哈)
不知道我的疑问是否有些奇怪,或者还没有理解 MCP 组件的核心本质而想的太多了哈哈。希望能得到老师的解答。
2025-06-10 10:06:00
2025-06-22 17:28:06
2. 关于MotherDuck,如果是国内环境,然后又是在wsl2上运行,科学上网可能还是下载不了插件,这个时候可以选择手动下载依赖到/root/.duckdb/extensions/v1.3.0/linux_amd64路径下,需要下载motherduck.duckdb_extension、motherduck.v1.3.0-2025-06-121.duckdb_extension 这两个文件,下载链接分别是: http://extensions.duckdb.org/v1.3.0/linux_amd64/motherduck.duckdb_extension.gz,http://ext.motherduck.com/v1.3.0/linux_amd64/motherduck.v1.3.0-2025-06-121.duckdb_extension.gz;
3. cursor上试了试motherDuck,同时,也在vscode上了,试了下motherDuck、fetch、mcp-caiyun-weather,确实调用通用服务特别方便。
4. 同理,在项目上,还是需要考虑网络环境,如果是可以部署在互联网的项目,那么通过MCP方式来调用一些已经开源的或者已经部署好的通用服务,那么将是一个非常便捷的事情;
5.MCP 与传统的 Function Calling 或 SDK 接入相比,你认为它的最大优势与潜在挑战各是什么?
1)如果仅是调用,那么不用关心API的参数、调用方式,MCP提供了极大的便利性,能够快速集成到Agent的工具中
2)如果即是调用者,也是服务提供者,那么如何快速开发和维护好MCP、设计良好的开发规范等,应该是一个需要去考虑的问题
2025-06-09 01:27:39
3、MCP协议对接成本低,降低重复开发。但SDK和function可能在具体场景的适配上会更有针对性,接口对接复杂但表达能力更强,最终可能有更好的效果。
2025-08-14 21:37:41
2025-07-24 10:54:26
2025-07-09 16:47:07
优势
标准化协议:统一 JSON-RPC 2.0 格式,适配多工具或数据源,降低集成成本
动态上下文管理:多轮交互中整合工具输出,增强推理连贯性
开放跨模型兼容:不绑定特定 LLM 或厂商,支持生态互通
挑战
标准化与定制化冲突:复杂工具需额外适配,难以覆盖所有场景特殊需求
上下文一致性风险:多轮工具调用可能导致信息丢失或冗余
安全权限复杂度:跨平台调用需额外解决认证、数据加密等安全问题
生态适配成本:当前垂直领域工具支持有限,自研系统封装需投入资源
2025-07-08 22:59:39
2025-07-07 13:59:28
2025-07-06 20:09:55
"mcpServers": {
"mcp-server-motherduck": {
"command": "uvx",
"args": [
"mcp-server-motherduck",
"--db-path",
"md:",
"--motherduck-token",
"<YOUR_MOTHERDUCK_TOKEN_HERE>"
]
}
}
} 。win11环境。先用 uv --version , uvx --version 命令验证当前环境是否有 uv 。如果没有,需要进行安装,powershell -c "irm https://astral.sh/uv/install.ps1 | iex" , 设置环境变量 $env:Path = "C:\Users\${user}\.local\bin;$env:Path" 。重启 cursor。切换mother duck mcp 按钮,就可以加载出tool了。
2025-06-22 00:46:18
2025-06-11 22:21:45
2025-06-11 17:35:34
2025-06-11 17:26:24
2025-06-11 17:21:06
2025-06-11 12:58:05