你好,我是孔令飞。
在 Go 项目开发中,我们经常需要处理一些数据,例如:从数据库中获取一条任务记录,根据这条任务记录创建资源,进行数据处理或者其他操作。同时,这些数据需要串行处理(最多只能有一个进程在处理这条数据),否则会导致数据被重复处理或者造成一些状态紊乱,以及其他不可预知的问题。
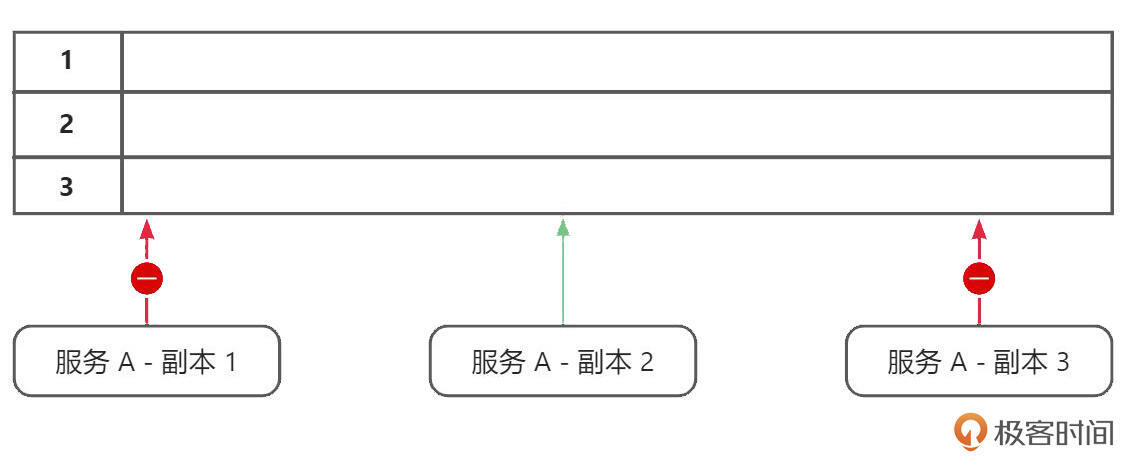
假设,我们部署了组件 A,A 组件启动后会串行地处理这些数据,并且在 A 组件进程内,我们控制同一时刻只有一个进程在处理数据 DataA。但同时,我们为了实现组件容灾部署了多副本,另外一个副本 B 也会处理这条数据,这时候就带来了同一条数据同时被多个进程处理的问题。那该如何解决呢?通常的解决办法是采用多副本实例抢锁的机制,也就是说谁抢到锁,谁执行,抢不到锁就一直阻塞,直到抢锁成功。锁的存在可以确保同时只有一个副本实例在处理数据,从而规避了多实例同时处理同一条数据的问题。
Kubernetes 中,如:Pod 的调度、Deployment 的创建、Pod 的创建等,几乎所有的 Kubernetes 资源处理都需要被串行执行。Kubernetes 使用了 Leader Election(领导者选举)机制,来确保多副本实例同时只有一个实例在处理资源。
本节课,我就来介绍下 Kubernetes 中 Leader Election 机制的原理。
什么是 Leader Election?
Leader Election(领导者选举)是一种分布式系统中的算法,用于在多个节点(或进程)中通过投票选出一个节点作为“领导者”或“主节点”,如果选举失败,则其余节点会自动重新运行选举过程以选择新的 Leader,确保系统连续性和容错性。选举出来的领导者负责协调其他节点的活动,确保系统的一致性和高可用性。领导者选举在许多分布式系统中是一个重要的组成部分,尤其是在需要一致性和故障恢复的场景中。
当前业界有多种 Leader Election 算法,常见的有以下 3 种:
-
Bully Algorithm:在这个算法中,节点通过发送消息来宣布自己是领导者。具有最高标识符的节点会成为领导者。如果一个节点发现当前领导者失效,它会发起新的选举。
-
Raft:Raft 是一种用于管理分布式系统一致性的协议,其中包括领导者选举的机制。Raft 确保在网络分区或节点故障时能够快速选举出新的领导者。
-
Paxos:Paxos 是一种经典的分布式一致性算法,其中也包含领导者选举的过程。Paxos 通过提议和投票的方式来达成一致。
Leader Election 机制实现的复杂性
Leader Election 机制是分布式事务中很好的选举算法,但是实现起来也有一定的复杂度。
在一个节点组中达成所有节点对 Leader 的共识,对于实现 Leader 选举至关重要。基本的实现可以利用锁服务来确定领导权。
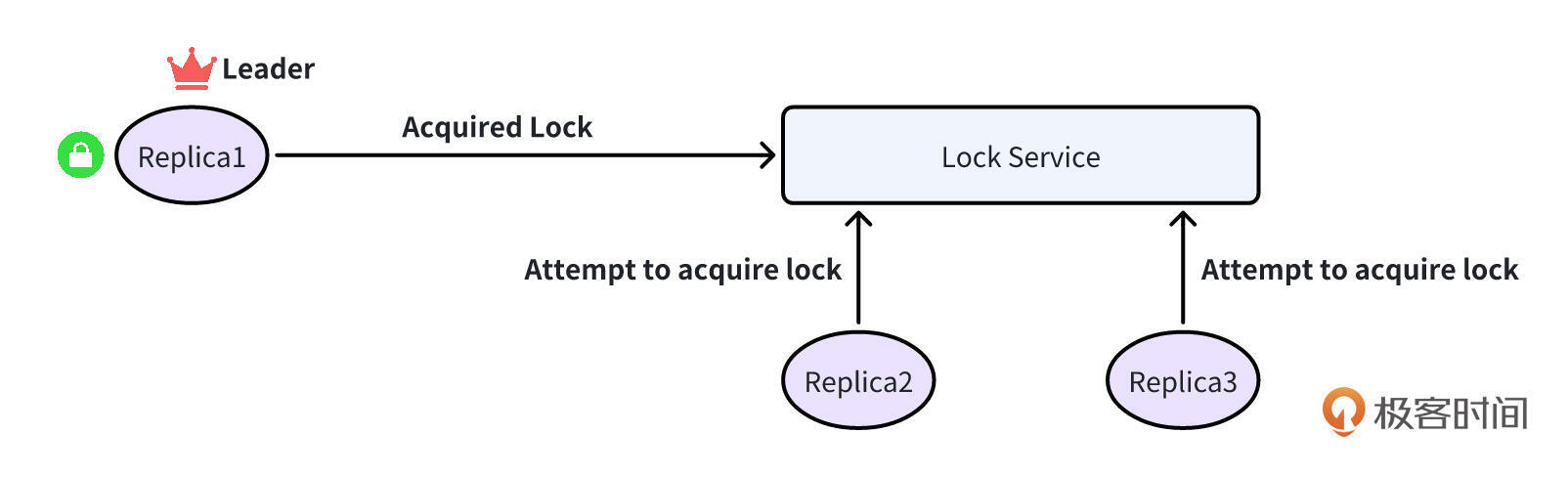
在这种情况下,每个实例都尝试获取一个共享锁。锁服务确保只有一个实例在任何给定时间持有该锁,有效地使该实例成为 Leader。其他副本不断尝试获取锁,从而准备好进行无缝故障转移,以防当前的 Leader 变得不可用。
然而,Leader Election 也会遇到挑战,比如:
-
领导节点异常,但不释放锁。
-
网络分区带来的脑裂。
挑战 1:领导节点异常,但不释放锁
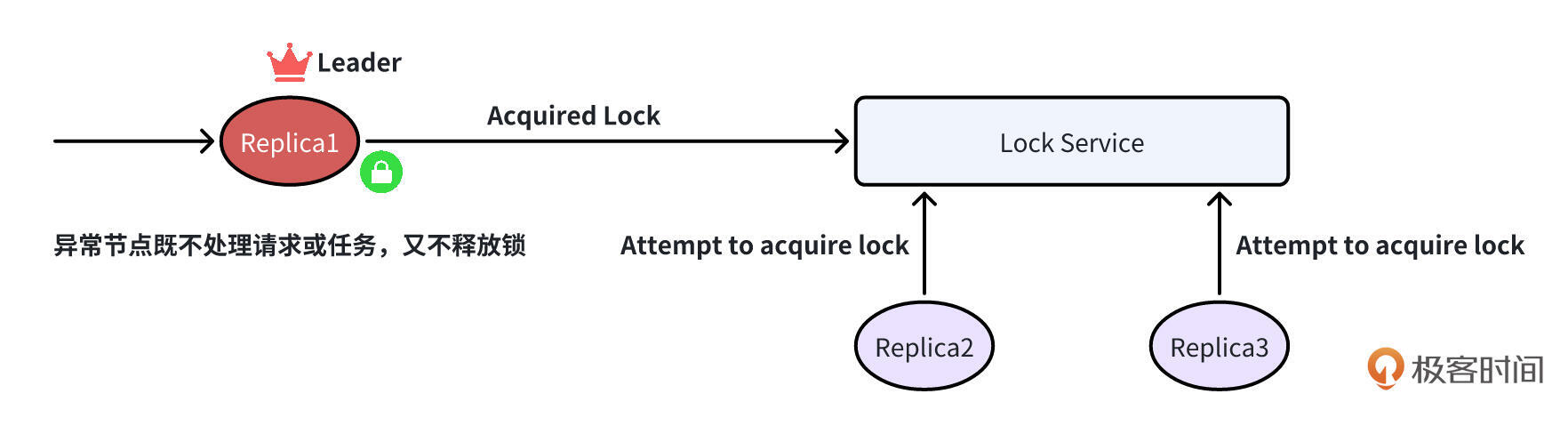
这种情况其实很常见,Leader 节点因为部署节点异常、网络抖动等原因造成服务异常。这种异常可能会带来多种结果,例如:
-
不能正确处理请求,导致请求超时
-
副本内处理任务的进程被销毁无法启动以处理任务
-
副本 Panic,导致服务被重启
-
…
总之,在 Leader 节点异常时,我们不能预期它能正常工作。这种情况下,就需要 Leader 能够释放锁,其他副本才能抢锁,并继续处理请求或任务。
为了缓解这个问题,通常的处理方法是给锁设置一个过期时间,一般称为基于 TTL 的租约。Leader 存活时,在 TTL 到期之前续约。Leader 异常时,由于无法正常续约,锁会在 TTL 过期后自动释放,随后被其他副本抢夺,以继续服务。
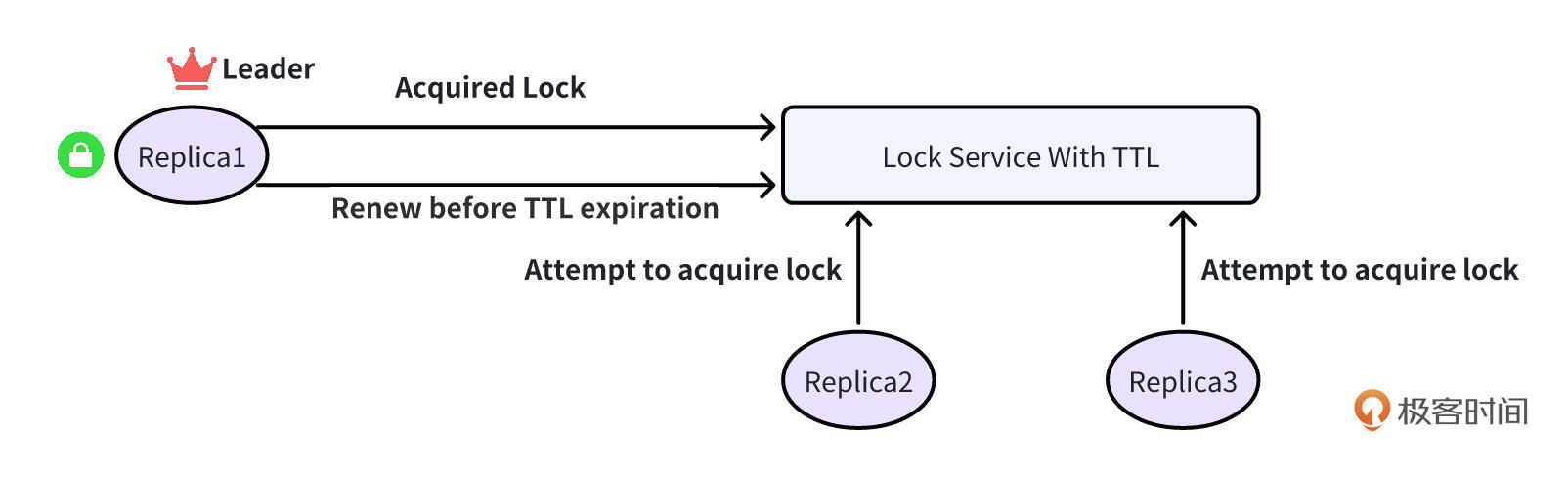
挑战 2:网络分区带来的脑裂问题
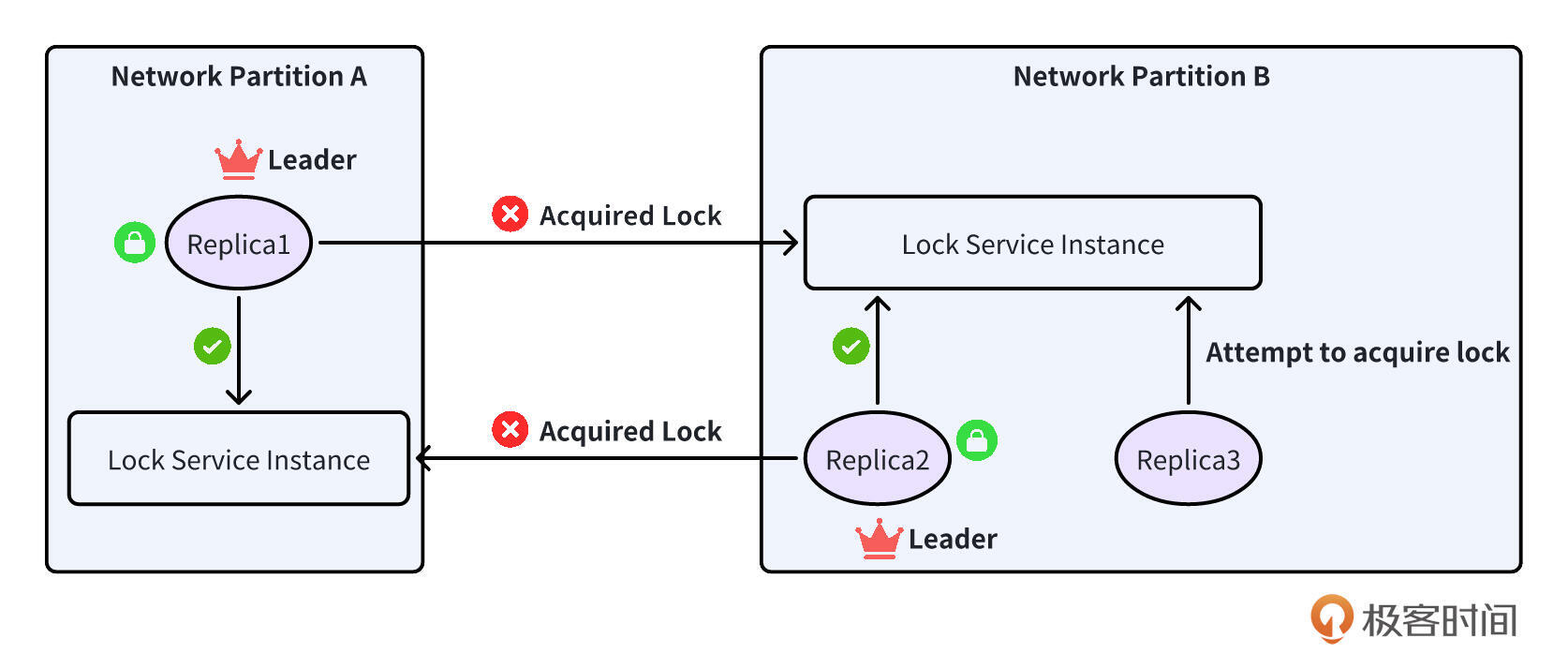
基于锁的 Leader Election 依赖锁服务,因此需要确保锁服务是稳定的,这就要求锁服务不能单实例运行,因为单实例必然会有单点故障。
因此,锁服务必须多实例运行,以实现高可用。锁服务的高可用必须能够解决网络分区的问题,否则可能导致一个棘手的情况发生:在不同网络分区中的两个副本都认为自己已经获得了锁,并因此承担领导者角色。
提示:网络分区问题(Network Partitioning)指的是在分布式系统中,由于网络故障或延迟,导致系统中的某些节点无法与其他节点进行通信的情况。这种情况会导致系统的不同部分之间无法交换信息,从而影响系统的一致性和可用性。
为了解决网络分区的核心问题,像 ZooKeeper(被 Kafka 使用)和 etcd(被 Kubernetes 利用)这种基于仲裁的系统,通过内置的 TTL 功能应运而生,成为将自己确立为领导者选举的最佳解决方案。ZooKeeper 原子广播(ZAB)协议和 etcd 采用的 Raft 协议都确保只有在大多数节点认可时才会考虑任何操作是有效的。在发生网络分区时,只有一个分区可以包含大多数节点,有效防止了出现多个领导者的可能性。
然而,无论是 ZooKeeper 还是 etcd 都不具备成本效益。分布式系统固有复杂性带来了运维挑战,为小规模服务部署这样的集群可能太重,并且额外开销可能超过应用程序本身的运维成本。
基于 Kubernetes 的 Leader Election 实现
上面,我介绍了实现 Leader Election 机制时面临的 2 个核心挑战。挑战 1 比较好解决,只需要给锁添加一个 TTL 过期时间,并给 Leader 添加一个定时续约的功能即可。
但是要解决挑战 2,需要锁服务实例之间能够有一些机制去规避网络分区问题。要规避网络分区问题,锁服务就需要去实现这些功能,也因此会带来一些实现上的复杂度、额外的开销和运维成本。在 Go 项目开发中,我们从 0 到 1 去实现这么一个锁服务工作量很大,而且也没必要。
如果你正在使用 Kubernetes 作为基础设施,那么一个最便捷、高效的方法便是通过使用 Kubernetes Lease 来实现 etcd 级别的 Leader Election 机制,而无需直接与 etcd API 进行交互。
Kubernetes Lease 介绍
Lease 是 Kubernetes 的内置资源,用于实现分布式系统中的领导者选举和协调。它们是基于 Kubernetes 的 API 对象,允许多个客户端(如 Pods 或节点)在集群中竞争领导权,并通过租约机制来管理领导者的状态。
Lease 资源实现的主要功能有3个,分别是领导者选举、分布式锁和资源管理。我们一一来看。
首先是领导者选举。在分布式系统中,通常需要选举一个领导者来协调其他节点的工作。通过使用 Lease,节点可以尝试获取租约,成功获取租约的节点成为领导者。Lease 实现的领导者选举功能,还具有以下功能:
-
状态管理:通过租约,Kubernetes 可以跟踪哪个实例是当前的领导者,以及领导者的健康状态。如果领导者失效,其他实例可以通过检查租约的状态来决定是否需要重新选举领导者。
-
过期机制:租约具有过期时间(TTL),如果领导者在指定的时间内未续约,租约将被视为失效,其他实例可以尝试获取领导权。这种机制确保了系统的高可用性和容错能力。
其次是分布式锁。在多个实例需要访问共享资源时,Lease 可以用作分布式锁,确保同一时间只有一个实例可以访问该资源。例如:Kubernetes 中的 kube-scheduler、kube-controller-manager 就是使用了 Lease 的分布式锁功能,来实现组件多副本容灾能力的。
最后是资源管理。Lease 还可以用于管理资源的使用情况,例如,确保某个资源在特定时间内被某个实例占用。
提示:在 Kubernetes 中,你可以理解为 Lease 就是一个锁,一个锁资源。
通过 Lease 的功能,我们知道 Kubernetes 中 Lease 资源可以用在以下场景中:
-
控制器管理:在 Kubernetes 控制器中,Lease 可以用于确保只有一个控制器实例在特定时间内处理某些资源,避免竞争条件。
-
分布式任务调度:在需要协调多个工作负载的场景中,Lease 可以帮助确保只有一个工作负载在执行特定任务。
-
高可用性服务:在微服务架构中,Lease 可以用于管理服务的领导者,确保在服务实例故障时能够快速选举新的领导者。
Kubernetes 中 Lease 资源定义如下:
// Lease defines a lease concept.
type Lease struct {
metav1.TypeMeta `json:",inline"`
// More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata
// +optional
metav1.ObjectMeta `json:"metadata,omitempty" protobuf:"bytes,1,opt,name=metadata"`
// spec contains the specification of the Lease.
// More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status
// +optional
Spec LeaseSpec `json:"spec,omitempty" protobuf:"bytes,2,opt,name=spec"`
}
// LeaseSpec is a specification of a Lease.
type LeaseSpec struct {
// holderIdentity 值为当前持有锁的身份标识。
// +optional
HolderIdentity *string `json:"holderIdentity,omitempty" protobuf:"bytes,1,opt,name=holderIdentity"`
// leaseDurationSeconds Leader 节点持有锁的时间,也是候选节点获得租约前需要等待的时间,单位为秒。
// 该时间是基于最后观察到的续租时间来计算的。
// +optional
LeaseDurationSeconds *int32 `json:"leaseDurationSeconds,omitempty" protobuf:"varint,2,opt,name=leaseDurationSeconds"`
// acquireTime 是当前租约被获得的时间。
// +optional
AcquireTime *metav1.MicroTime `json:"acquireTime,omitempty" protobuf:"bytes,3,opt,name=acquireTime"`
// renewTime 是当前持有租约的节点上次更新租约的时间。
// +optional
RenewTime *metav1.MicroTime `json:"renewTime,omitempty" protobuf:"bytes,4,opt,name=renewTime"`
// leaseTransitions 是租约在持有者之间转换的次数。其实,也就是该 Lease 资源经历过的选举次数。
// +optional
LeaseTransitions *int32 `json:"leaseTransitions,omitempty" protobuf:"varint,5,opt,name=leaseTransitions"`
}
上述 Lease 资源定义中,包含了分布式锁需要的关键字段:谁(HolderIdentity)在什么时候(AcquireTime)获得了锁,在什么时候续(RenewTime)租了锁。Lease 资源还给获得锁的节点一定的异常缓冲时间,用来防止因为网络抖动、节点续租时的短暂延时和异常等导致的频繁抢锁。Lease 实现方式也很简单,就是当 Leader 节点续租之后,超过一定时间(LeaseDurationSeconds)才允许候选节点抢锁成为 Leader。另外,Lease 资源定义中,还包括了一些额外的信息,例如:Lease 选举的次数(LeaseTransitions)。通过 Lease 资源定义,聪明的你应该能猜出 Kubernetes 具体是如何实现领导者选举机制的。Kubernetes 实现领导者选举机制的功能由 k8s.io/client-go/tools/leaderelection 包提供。
Kubernetes Lease 之所以强大,部分原因在于 Kubernetes 本身将 etcd 作为其所有 API 对象(包括租约)的存储。这意味着 etcd 的高可用性、一致性和容错特性自然地可用于 Kubernetes Lease。但是,Kubernetes API 添加了额外的功能层,比如通过资源版本控制实现乐观并发控制,这也有助于使租约成为在 Kubernetes 环境中进行领导者选举时一个强大的选择。
关于
k8s.io/client-go/tools/leaderelection包具体是如何基于 Lease 实现领导者选举功能的,我会在后面的课程中详细介绍。
Kubernetes Lease 工作原理
在 Kubernetes 中,可以使用 Lease 对象实现领导者选举。竞争领导权的候选人要么创建,要么更新 Lease 对象,并将其标识符设置在 holderIdentity 字段中。领导者持续“续订”该 Lease 以保持其角色。如果领导者未能在 Lease 到期前续订,则其他候选人会尝试获取它。首个成功更新 Lease 的候选人将成为新领导者,所有候选人都会监视 Lease 对象以跟踪 Leader 变更。另外,为了避免因为网络抖动、延时等带来的频繁选举问题,候选节点在续约前需要等待一定时间。如果 Leader 节点能在这段时间重新续约,那么候选节点仍然会续约失败。如下图所示:
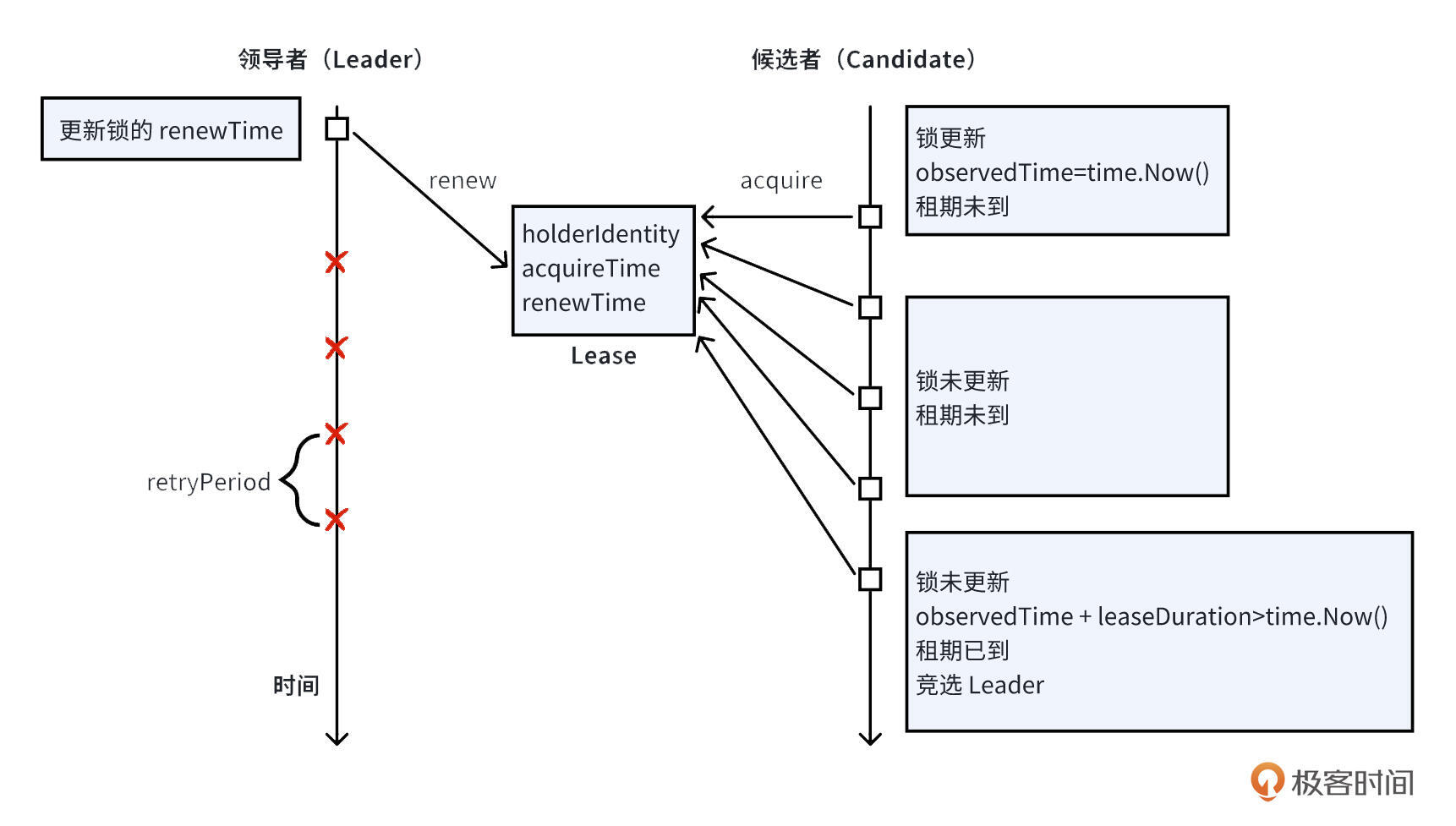
在抢锁的过程中,势必会存在同时更新 Lease 的操作,Kubernetes 是通过版本号(ResourceVersion)的乐观锁来解决这种竞争的。它对比了 resourceVersion,而 resourceVersion 的取值最终又来源于 etcd 的 modifiedindex,当 key 对应的 val 改变时,modifiedindex 的值发生改变。
Kubernetes 的 Update 是原子的、安全的,通过 resourceVersion 字段判断对象是否已经被修改。当包含 ResourceVersion 的更新请求到达 kube-apiserver 后,kube-apiserver 将对比请求数据与服务器中数据的资源版本号。如果不一致,则表明在本次更新提交时,服务端对象已被修改。此时,kube-apiserver 将返回冲突错误(409),客户端需重新获取服务端数据,重新修改后再次提交到服务器端。
提示:ResourceVersion 字段在 Kubernetes 中除了用在更新的并发控制机制外,还用在 Kubernetes 的 list-watch 机制中。Client 端的 list-watch 分为两个步骤,先 list 取回所有对象,再以增量的方式 watch 后续对象。Client 端在 list 取回所有对象后,将会把最新对象的 ResourceVersion 作为下一步 watch 操作的起点参数,也即 kube-apiserver 以收到的 ResourceVersion 为起始点返回后续数据,保证了 list-watch 中数据的连续性与完整性。
课程总结
本节课,我们围绕 Leader Election 机制展开,重点讲解了 Kubernetes 中的实现。
首先,我们解释了为何需要 Leader Election 机制:在多副本部署场景中,为避免同一条数据被多个进程同时处理导致重复处理、状态紊乱等问题,需要通过选举机制确保同一时刻只有一个节点负责处理资源,其余节点作为候选者等待接管。
随后,我们明确了 Leader Election 的定义:它是分布式系统中通过投票从多个节点中选出一个领导者的算法,领导者负责协调其他节点活动,保障系统一致性和高可用性;同时介绍了业界常见的三种算法 ——Bully Algorithm、Raft、Paxos。
接着,我们分析了实现 Leader Election 的两大核心挑战:一是领导者节点异常时不释放锁;二是网络分区导致的 “脑裂” 问题。
最后,我们重点讲解了 Kubernetes 中 Leader Election 的设计与实现:借助内置的 Lease 资源,通过 holderIdentity、leaseDurationSeconds等字段管理领导权;依托 etcd 的高可用性和一致性存储,结合 ResourceVersion 实现乐观并发控制,避免多节点抢锁冲突;领导者需定期更新 renewTime 续约,超时后候选节点可竞争成为新领导者,既满足分布式场景需求,又降低了独立部署锁服务的运维成本。
课后练习
请你思考下实现分布式锁的原理是什么,并用自己的话总结 Kubernetes Lease 的工作原理。
欢迎你在留言区与我交流讨论,如果今天的内容让你有所收获,也欢迎转发给有需要的朋友,我们下节课再见!
精选留言