语言不是通往智能世界的钥匙,语言就是智能本身。
——题记
词的本质
1882 年初,在美国南部的一个小镇上,不到两岁的婴儿海伦·凯勒饱受着一场莫名高烧的折磨。高烧持续不退,医生诊断是胃部和脑部急性充血,束手无策。家人们沉浸在绝望中,认为小海伦没救了。然而,一天清晨,高烧竟奇迹般消退,家人们都欣喜若狂,却没有意识到一个更大的灾难已经降临。
小海伦发现自己的世界变得一片寂静,自己什么都听不见了,眼前也是一片黑暗。这让小海伦惊恐不已。高烧使她完全失去了听觉和视觉,仿佛回到了刚出生时的状态。
小海伦靠着触觉、嗅觉和味觉探寻着这个世界,通过简单的动作表达自己,与别人沟通,比如靠拉别人表示来,靠推别人表示走。聋哑在很多时候是同时存在的,由于听不见,自然也学不会说话。可怜的小海伦成为一个全聋全哑全盲的人。岁月流转,小海伦的世界始终充满黑暗和寂寥,仿佛生活在浓雾中的海上。
6 岁那年,小海伦遇到了改写她命运的人——安妮·莎莉文老师。莎莉文老师通过在小海伦的手心写单词,帮助她学习语言。渐渐地,小海伦掌握了一些简单的词,例如针、坐、走等。有一次,小海伦始终分不清“杯子”和“水”这两个单词。莎莉文告诉她,杯是杯,水是水,但是小海伦认为杯是水,水是杯,因为她完全看不到水的形态,听不到水的声音,只能感受到湿润冰凉。焦躁的小海伦把洋娃娃扔在地上,非常受挫。莎莉文老师则把她带到按压式抽水机旁,将小海伦的手放进水里,然后一遍又一遍地在她的手心里写下“水”这个单词。突然间,一种触电般的感觉弥漫全身,海伦终于知道了,这清凉、流动的触感就是水。这仿佛是黑夜里燃起的火把,照亮了一切。
后来,海伦在自传中描述道:“这个单词好像一下子焕发了生命力,唤醒了我沉睡的灵魂。似乎从此以后,我的世界不再黑暗孤寂,我终于迎来了希望和光明、欢乐和自由……离开水房,我内心充满了对学习的渴望。原来世间万物都有自己的名字,而每个名字都会激发新的思想。再次回到房间,一切好像都不一样了,我曾经触碰过的所有东西,此刻似乎都有了生命。”
这次巨大的惊喜过后,海伦充满了学习的热情,不断央求莎莉文老师教她新词,而且一天就能学会几十个,如父亲、母亲、妹妹、老师等。
一天清晨,海伦在花园里摘了几朵紫罗兰花送给了莎莉文老师。莎莉文非常高兴,想吻海伦。但是她知道海伦和她还没有那么亲近,于是,莎莉文用胳膊轻轻地搂着海伦,在她手上拼写出了“我爱海伦”几个字。
“爱是什么?”海伦问。
莎莉文更紧地搂着海伦,用手指放在她心脏的位置说:“爱在这里。”
海伦感受到了心脏的跳动,但她仍感到困惑。心跳就是爱吗?拥抱就代表爱吗?
作为一个全聋全哑全盲的人,小海伦接触到的世界非常有限,只能依靠触觉去一点点地了解周围的一切。
海伦继续用手语询问:“爱就是花的香味吗?”
“不是。”莎莉文老师说。
阳光正温暖地照下来,海伦又问道:“爱是不是太阳?”
“也不是。”
那天,海伦始终没有理解到底什么是爱。
一两天后,海伦正在用线穿珠子,穿到最后才意识到自己有一大段穿错了,于是就想着到底怎样调整。莎莉文老师轻触了一下海伦的额头,然后拼出了“想”这个单词。海伦突然明白了,“想”就是脑袋里进行的一种过程。这是海伦第一次理解一个抽象的概念,原来这个世界上存在无法触摸的词。
海伦沉思良久,仍然不断地去想,那“爱”到底是什么呢?
接着,海伦又问:“爱是不是太阳?”
莎莉文老师回答:“爱,有点儿像天上遮住太阳的云朵。你触摸不到云朵,但能触摸到雨水,你知道经历了一日暴晒,干瘪的花朵和干涸的大地是多么渴望雨水的滋润。同理,你无法触摸到爱,但能感受到爱心滋养的幸福甜蜜。没有爱,生活就不会快乐,甚至连玩耍都无法让我们提起兴趣。”
刹那间,“我明白了其中的道理——我感觉到有无数无形的线条正穿梭在我和其他人的心灵中间”。海伦顿悟了,这就是爱!她豁然开朗,对这个世界有了更深的理解。
顽强好胜的海伦在黑暗、寂静的世界里,凭借着坚定的毅力和不懈的努力,走过了比常人艰难得多的学习之路。她逐渐成长起来,学会了阅读和写作,奇迹般地考进了哈佛大学,成为第一位获得文学学士学位的聋盲人。她一生出版了 14 本书,做过数百场演讲。
伟大的莎莉文老师陪伴海伦走过了 50 年,她成为海伦和世界沟通的桥梁。二人之间感人至深的故事后来被搬上了荧幕。海伦的自传也传入了中国,深深打动了无数读者。海伦的一生都在和语言学习做斗争,她曾说:“将我囚禁在黑暗寂寞世界中的并不是失明和失聪,而是无法用正常语言交流,这才让我陷入深深的失落。”
我阅读过 100 多本育儿方面的书,给我印象最深的就是海伦·凯勒的自传。全聋全哑全盲的极端案例,可以说深刻揭示了学习的本质。当读到海伦·凯勒所写的“我感觉到有无数无形的线条正穿梭在我和其他人的心灵中间”这句话时,我感到一种震颤,同样感受到有无数无形的线条穿梭在心中,这种感觉至今令我记忆犹新。当你读到这里时,可能同样有无数无形的线条穿梭在你的心中。
多年后,想起海伦学习“水”和“爱”的过程,我更加深刻地理解了 ChatGPT 的智能学习过程及词的本质。现在,让我们快进一下,从 100 多年前海伦的故事迅速回到如今的 ChatGPT 世界。
我们在不需要教导的情况下也能感觉到,苹果和香蕉之间的距离要比苹果和火车近得多。这是因为,我们知道苹果和香蕉的很多特性是更相近的。
人工智能也能够对词汇的特性进行分析。比如,苹果拥有的特性——水果、甜、红、圆——都会有一个概率。在分析时,这些概率数字会形成一个高维空间向量。人工智能中的词向量是文本在 n 维空间中的分布式表示,它可以有几百个到几千个维度。这些维度可以用几百到几千个数字表达,这样就可以被用于计算了。
如图 8-1 所示,向量空间的夹角越小,词的相似度就越高。如果两个词的夹角小到近乎重叠,那么这两个词就互为近义词,例如汤圆和元宵。相似的词不仅在向量空间中离得近,在大脑中也离得近。举个例子,有一个人没听清一位师傅说自己姓什么,于是,这位师傅着急地回答:“我是红绿灯的黄师傅。”虽然师傅没有说黄瓜的“黄”,但我们还是能理解他的意思。
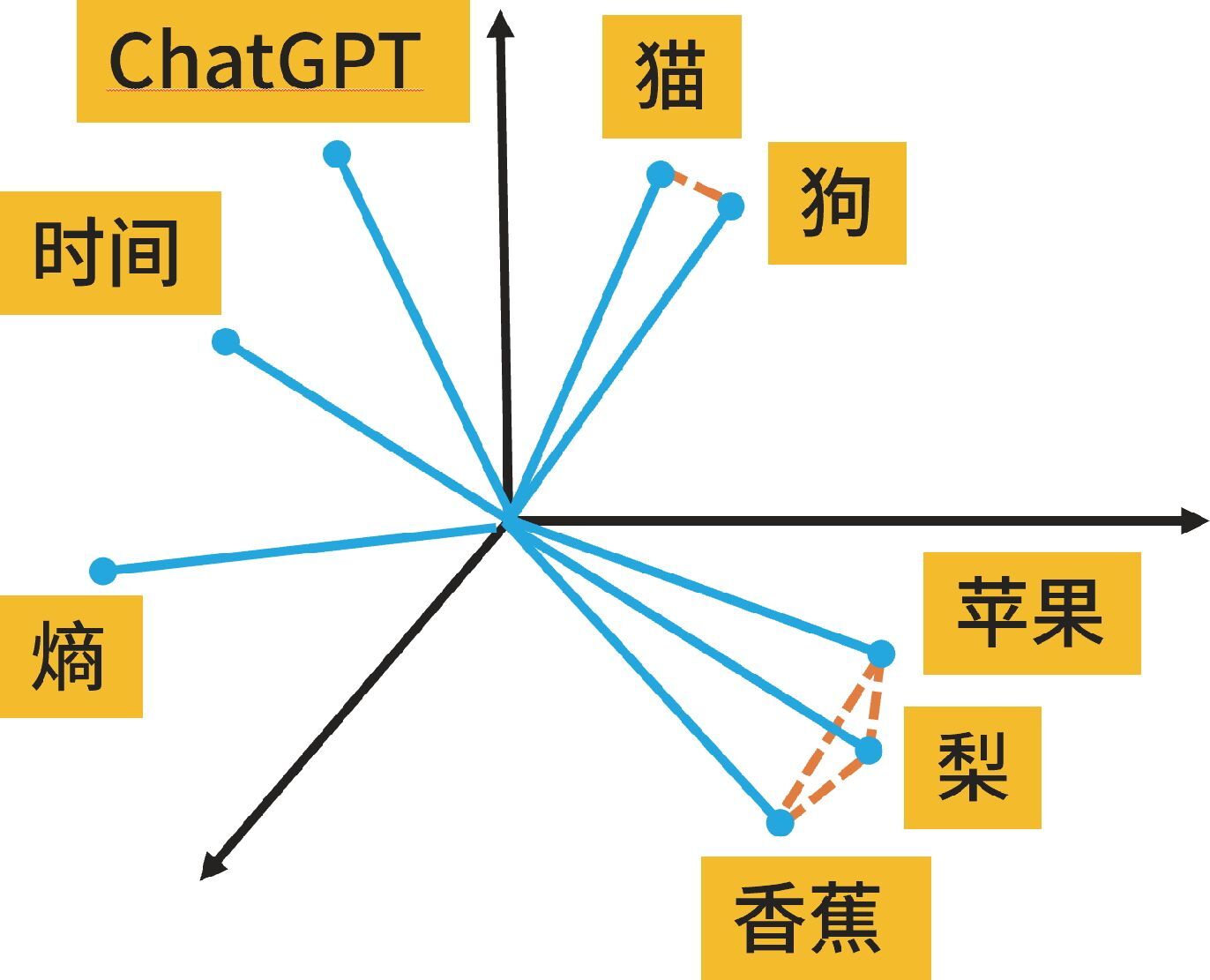
图 8-1 词向量是文本在 n 维空间中的分布式表示
论文查重和抄袭鉴别靠的就是计算向量夹角。即便抄袭中打乱原文次序,但还是可以通过快速计算向量相似度识别抄袭。这就像是在吃自助餐时,一个人“抄袭”你拿的自助餐,即便他拿的次序和你不一样,他餐盘中的食物和你餐盘中的食物本质是一样的。如果用向量表示,这两份自助餐是完全相同的。人工智能可以通过复杂的计算,识别不同语言的向量,并最终得出同一个词的不同语言表达方式的向量是一致的。
再来举个例子。假设我们看到一个外星人跑到地球上来说,“我看到,rugrugrug 会抓老鼠,狗和 rugrugrug 打架,rugrugrug 也爱吃鱼”。那么,rugrugrug 是猫的概率可能就是 99%,不过不可能是 100%,因为它还可能是狗或者其他动物。当加入更多的数据时,比如 rugrugrug 的眼睛会变成一条线,rugrugrug 会喵喵叫,rugrugrug 拉屎时要找沙坑,rugrugrug 有些像老虎……那么在这种情况下,rugrugrug 是猫的概率就接近 100% 了。
这像不像猜谜语?猜谜语就是向量求解。例如,“麻屋子,红帐子,里面住着白胖子”,这个谜语的答案是花生。
ChatGPT 第一版是一个纯文本模型,它就像是从小在图书馆长大的孩子,没有看见过老鼠和大象,没有体验过鸟语花香,没有经历过大自然的风光和生命的多彩,但只要它计算得足够多、足够深,那么 ChatGPT 所理解的字符与符号,其实就是我们所理解的世间万物。
有人说,ChatGPT 不过就是一个概率模型,它只是根据输入向外“吐”字符串。但通过理解这个学习过程,我们至少可以说,ChatGPT 应该知道自己在说什么。它可能存在“胡说八道”的情况,但它所说的香蕉就是我们所看到的香蕉;它表达的事物和概念与我们理解的是一样的。虽然传统的自然语言处理路线也是研究自然语言的,但是目前新的大语言模型对自然语言的学习深度和广度有了极大的提升。
再举一个例子。
大学刚毕业时,我是一个在社交上相当自卑的人,当人一多时我便不敢讲太多话,更不敢开玩笑。当我逐渐理解一切技能都是可以通过刻意学习获得的时候,我花了很多时间反复地去听相声和脱口秀,甚至有些段子我听了几十遍。我还参加了脱口秀培训。最终有一天,我突然理解了幽默的本质,相声、小品、脱口秀的所有幽默段子中都包含一些共同特征。
我总结了幽默的数学定义——这也太不幽默了,也显得非常“民科”。幽默的数学逻辑,就是从逻辑 A 跳到了逻辑 B 上,或者从故事线 A 跳到了故事线 B 上。举个例子,有个女生在朋友圈发了个段子。
“圣诞节的晚上,有个帅哥抱着一大捧玫瑰花,向我走来。
对我说——”
点开“全文”,显示的是:“请让一让。”
这条朋友圈不仅完美地展示了有趣和幽默感,还暗示了自己是单身,增加了被追求的概率。
这个段子中有两条概率逻辑线。
故事线 A:圣诞节帅哥抱花向我走来,要向我送花。这是我们所预期的故事线,是个浪漫场景——情侣秀恩爱。
但是实际上,情况出人意料地跳到故事线 B:请让一让。这条故事线说明女生是单身,人们对她的认识突然发生了 180 度的反转,结果意外又滑稽。这种反转让人感到了幽默。
让我们再问一下 GPT-3.5 版 ChatGPT,图 8-2 所示的这个段子为什么好笑。

图 8-2 GPT-3.5 版 ChatGPT 对一个段子为什么好笑做出回答
很显然,ChatGPT 完全没搞懂这个段子为什么好笑。通过反复测试 ChatGPT 对段子的理解,我们可以看出 ChatGPT 是否真正理解了人、理解了人性。未来如果出现像《星际穿越》中的 TARS 机器人及《流浪地球 2》中的 Moss 机器人,我们可以将它们的幽默值设定为 0% ~ 100%。如果幽默是故事线之间的跳跃,那么它也是概率上的突然变化。
用同样的段子,我们再来试试 GPT-4 版 ChatGPT 的反应,如图 8-3 所示。

图 8-3 GPT-4 版 ChatGPT 对同一个段子为什么好笑做出的回答
很显然,和前一版本比,ChatGPT 变化显著。GPT-4 版 ChatGPT 完美地解释了这个段子的主要逻辑,理解深度完全上升了一个层次。
在这个段子里有两条故事线。
故事线 A:单身男以为结了婚会更轻松,婚后不用自己洗衣服。
故事线 B:已婚男指出了结婚的真相,婚后要洗更多的衣服。
后来我发现,脱口秀大师就是这样定义幽默感的:两条故事线之间的跳跃。这个例子中的故事线 B,便造成了一种意外。幽默大师陈佩斯在总结幽默的本质时,就曾指出意外的作用。
如果我们从数学角度看,幽默有个必要限定条件:不仅要跳出故事线 A,还得跳到故事线 B 上,给人一种新的认知。想象一下,如果上面所讲的第一个例子变成“圣诞节帅哥抱花向我走来,他给了我一拳”,就不会那么好笑了,因为这里的意外似乎没有什么意义。
在观察婴儿是怎样认识世界时,我们会发现婴儿对任何突然出现的东西总是会感到兴奋,咯咯笑个不停。这种对意外的兴趣和注意,其实是一种强大的生存本能。实际上,幽默就是一种新知奖励。在进化的过程中,人类遇到了巨大的生存压力,对于新变化会本能地产生更大的兴趣。当获得新认知的时候,大脑产生的愉悦感就是巨大的奖励。但是,如果对生存无用,那么幽默感就不会存在了。
在辩论中,那些更有幽默感的人总显得更聪明,更有说服力。短视频 UP 主也喜欢利用这一点,总会制造巨大的反差、意外,以勾起你的兴趣。所以,短视频行业形成了“3 秒法则”这一基本创作原则。我给“3 秒法则”另起了一个名字——“多巴胺钩子”。
通过上面所举的海伦·凯勒学习“水”和“爱”的例子,以及探索“幽默”的定义,我们可以总结出:一个词的本质就是一系列事物所拥有的相同模式。词其实是相似的许多事物涌现出的共同特征的名字;造一个新词,等于给这种特征起一个名字,这不仅仅包括名词,动词、虚词、形容词也一样。
海伦·凯勒在感受水时,去除了杯子的干扰,在水井旁反复体验湿润清凉的感觉。这种反复出现的相同模式,让海伦感到了“水”这个概念的存在。像名词这种有实际意义的词,我们看得到、摸得着,这让我们更容易理解和学习。而有些概念,例如“爱”,对于海伦·凯勒这样不幸陷入黑暗寂静世界的女孩来说,是难以捉摸的。但是,当不断体会亲吻、温暖、给小草浇水这些包含相同本质的生活体验时,她就瞬间理解了什么是“爱”。这里所包含的共同本质,就是一方为另一方增加了生存概率和生命值。
这里顺便提一下“爱”和“喜欢”的区别。“喜欢”的受益方是自己:我们喜欢一个人,是因为对方的某种特质让我们感到愉悦。而“爱”的受益方则是对方:爱一个人意味着我们想让对方幸福开心。当从数学角度来定义这两个词时,我们会发现“喜欢”和“爱”都在增加一方的生命值,只是方向不一样。
如果做进一步的解释,词汇可以被看作拥有相同的模式,这种模式可以用统计学上的概率来表达。我们以椅子和凳子为例,感受一下这种微妙的差异。如果一把椅子的靠背有 50 厘米高,当靠背的高度从 50 厘米处以 1 厘米为间隔阶梯式降低,椅子就会逐渐变成凳子。在此过程中,某些中间形态的物品既可以被认为是椅子,也可以被认为是凳子。这种有趣的现象告诉我们,词汇实际上是一种概率模型。
语言的本质
1798 年,拿破仑率领军队远征埃及,宣称是为了保护法国商人,实则为了打击英国的海外经济利益。1799 年拿破仑军队占领埃及期间,一名军官在埃及罗塞塔镇附近发现了一块不同寻常的石头,石头的一面刻着密密麻麻的神秘符号,如图 8-4 所示。这块一米多高的黑色石头已经残缺不全,显出历尽沧桑的气息。此时,法国正处于对神秘埃及的狂热之中,这块石头很快得到了重视,仿佛它能够打开什么神秘大门。石碑上面显著地刻了 3 种文字,这极为罕见,肯定大有来头。很快,符号的复制品就在欧洲的学者中流传。
公元前 3200 年左右,古埃及象形文字诞生,它是当时的正式文书用字,如图 8-5 所示。经过漫长的演化,又衍生出了两种文字:古埃及草书和古希腊文。后来古埃及象形文字和古埃及草书渐渐因无人使用而消失了。到了公元 4 世纪,这两种文字再也没有出现过。当 1799 年罗塞塔石碑被发现时,已经大约有 1400 年没有人知道古埃及象形文字有什么含义了,所以古埃及的历史一直无人知晓。当时的人们普遍认为,如此栩栩如生的象形文字,应该是表意文字,而不是表音文字。

图 8-4 拿破仑军队的军官发现的罗塞塔石碑

图 8-5 古埃及文字
1801 年,拿破仑的军队被英军打败,罗塞塔石碑落入了英国人手中。1802 年,罗塞塔石碑被运回伦敦,并成了大英博物馆的镇馆之宝。古埃及文字 1400 年的未解之谜刺激着欧洲学者的心,但是罗塞塔石碑上的碑文迟迟未被破译。直到 1822 年,法国学者商博良通过持久的努力,才破译了部分文字,他还推导出一个意外的结论:古埃及象形文字也是表音的。也就是说,古埃及象形文字是表音表意文字。这太让人吃惊了。
原来,罗塞塔石碑是 2400 年前展示在一座神庙内的纪念碑,刻的是国王托勒密五世的一份诏书,诏书列举了托勒密五世的善行。比如,托勒密五世捐助建设了神庙,减免了苛捐杂税,减免了穷人的债务,派遣军队抵抗了敌人,利用尼罗河的洪水冲毁了敌人的基地,等等。有意思的是,他还承诺神庙继续承受他的供奉;相对应地,作为回报,神要给予他健康、胜利、权力和所有最好的东西,并保佑他和他的子孙永远享有王位。这些内容和香客去五台山许愿还愿的内容差不多。现在我们知道如果穿越到古埃及应该怎样写纪念碑文了。罗塞塔石碑上的碑文内容不只是展示了一段古埃及历史,更像是现代人揭开古埃及文明的一把钥匙,因此后来罗塞塔石碑也成为解谜的象征。
罗塞塔石碑的碑文由 3 种文本平行镌刻,内容一模一样,所以才能最终破译成功。但是,如果只有罗塞塔石碑,人们也不能完全确定破译结果是正确的。后来随着一块又一块新的平行文本石碑的发现,罗塞塔石碑破译工作的正确性才不断得到了验证。因此,研究语言不仅要数据好,还要数据量足够多。
我们知道,已经有无数的著作对语言的本质是什么进行了阐述。语言是一个符号系统,是一种工具,也是一套声音象征系统。时至今日,关于语言的本质仍旧没有达成共识。如果要理解作为自然语言模型的 ChatGPT,我们需要更深层次地探讨语言的本质问题。
从本章开头所说的词的本质来看,词是一系列相同特征的集合,既包括实词也包括虚词。那么语言作为词的序列,实际上构成了对这个世界的描述。换句话说,自然语言是物理世界的投影。罗塞塔石碑解锁古埃及历史的故事告诉我们,语言的序列对我们更为重要。
1978 年,Koko 登上了美国《国家地理》杂志的封面,引起了全球关注。Koko 是一只雌性西部低地大猩猩,会使用超过 1000 个单词的手语,还养过几只猫咪宠物。手语也是一种语言,虽然 Koko 学会了很多单词,但是她从未拥有过输出句子的能力。输出句子是唯有人类可以驾驭的高级智慧。
如果说自然语言是物理世界的投影,那么我们可以进一步说,自然语言的序列体现了物理世界的时空因果关系,因为两个毫不相干的词或字是不会无缘无故地组合在一起的。如果在搜索引擎中搜索两个毫无关系的生僻字,你是得不到答案的。
从神经网络计算的角度来看,我们不难得出一个更深刻的结论:语言是人类大脑神经网络计算的中间特征,这些中间特征被用于人类交流,以便组成更大的人类大脑网络,实现更进一步的智能计算。在人类社会中,大脑需要借助语言这个工具才能将信息存储在实体介质上并进行传播、扩散和继承。而人类在创造新的字、词、句子时,就是在描述物理世界的新的事实或者对事实进行预演。由于大模型是在人类的语言基础上进行智能计算的,省略了对物理世界的基本建模,因此大模型要比其他人工智能路线更快地实现通用人工智能。
智能不都是语言,但是语言一定是智能。例如 AlphaGo 下棋和打铁老师傅的经验都是一种智能,但这种智能不是语言。我们人类通过语言认识物理世界,ChatGPT 也是通过语言认识物理世界的。
现象级畅销书《人类简史:从动物到上帝》由以色列历史学家尤瓦尔·赫拉利所著,其核心观点非常精彩,那就是人类的虚构想象力构成了人类社会的基础。这种虚构想象力的实际介质就是语言。人类通过语言构建了国家、法律、金融等一切概念,进而通过对抽象概念达成共识而实现了协作和文明。
人类不需要真正触电,就能够学习到电是危险的,而 ChatGPT 也不用真正触电就能学习到电是危险的。人类智慧已经凝结在了无数的语言序列之中。
接下来,我们看看 ChatGPT 在翻译上的不同,来理解大模型和传统的自然语言处理技术路线有什么不同,以便理解为什么语言序列体现了物理世界的时空因果关系。
话说谷歌在 2012 年以 4400 万美元的惊天价格收购了欣顿的 3 人公司后,伊利亚就跟随欣顿进入了谷歌公司。伊利亚在谷歌期间深度参与了谷歌翻译的开创性工作,通过使用 Seq2Seq 模型和注意力机制等新技术,使得谷歌翻译的翻译结果变得更加准确和自然,特别是在处理复杂的语法和语义结构时,谷歌翻译的表现比以前更好。
之前的谷歌翻译主要基于对短语的翻译,效果很差。名词对名词的翻译往往比较容易处理,因为实体之间通常是一对一的。而动词、虚词等词的含义非常丰富,多的有几百种含义。我们以 play 这个词翻译为中文为例。
在对应的解释里,只在很少的场景中,play 被翻译为“玩”,如图 8-6 所示。如果是固定搭配,比如 play music,我们可以将其翻译为“演奏音乐”,但是实际情况往往不会这么简单。来看一个例子:I have a movie that I want to watch, can you play that one for me?(我有一部想看的电影,你能为我播放它吗?)

图 8-6 英文单词 play 在不同词组搭配中有不同含义
想理解这里的 play,就需要到前面找 play 到底对应的是什么。答案是 movie,所以这里的 play 就要翻译为“播放”。在伊利亚和同事研发了 Seq2Seq 模型后,神经网络才深度理解了句子和句子之间的关系,大幅地提升了谷歌翻译的质量。
但是谷歌翻译并非尽善尽美。虽然 Seq2Seq 模型相比之前进步巨大,但是还有很多问题没有解决。举例来说,谷歌翻译需要收集大量的对齐文本,例如一句中文对应一句英文的句子对。谷歌支持 100 多种语言双向互译,理论上就需要构建 100×100 = 10 000 多种语言对,这是几乎不可能实现的数据量。谷歌翻译在训练时使用了多种中介语,即便如此,最少也需要 100 多种语言对,同时还需要由人工收集、验证这 100 多种语言对的数据是否正确。
ChatGPT 与此不同。ChatGPT 的基础模型数据集不需要严格对齐的语言对,只需要无标记文本。也就是说,大模型靠超级巨大的数据集中的语言规律,来深刻理解语言背后所投影的物理世界,进而找到相对应的翻译。这就非常神奇了。ChatGPT 并没有专门针对翻译任务进行训练,但是翻译能力惊人。在专业领域,专业翻译软件中的数据量更大,所以专业翻译软件效果更好;但在日常用语领域,ChatGPT 的翻译效果已经优于其他专业翻译软件。
只要某种语言不是孤岛,只要有足够多的语言交叉,大模型就能够学习到所有语言内在的深刻联系,从而体现出翻译、理解、推理、思考、写作等几乎所有的人类思维智能。这就是大模型的神奇所在。
复杂性科学:涌现
这不是一场恶作剧。
在巴西的一片草地上,几个人用一辆水泥罐车运来了稀水泥,将水泥注入一个蚂蚁窝的洞口。这是几位科学家正在进行的一场科学实验,目的是揭开切叶蚁地下巢穴的奥秘。大量的水泥源源不断地涌入蚂蚁洞,却始终无法将其填满,这个蚂蚁洞似乎深不见底。科学家忙活了几天后,蚂蚁洞洞口的水泥终于溢了出来,说明巢穴已被填满。
为了让水泥有充分的时间凝固,科学家足足等待了一个月。随后,他们开始慢慢地挖掘这个庞大的蚂蚁巢穴,如图 8-7 所示。在他们面前,逐渐显露出一个面积约 50 平方米、深达约 8 米的“地下都市”——大概有一个教室面积那么大、两三层楼深的坑。有人说,蚂蚁建造的这座“地下都市”仿佛是人类建造的万里长城。
作为地球上仅次于人类的第二大复杂动物社会结构,一个典型的切叶蚁巢穴可以居住 800 万只蚂蚁。这个庞大的社群并没有中央管理机构,全部依靠自组织共同生活。切叶蚁外出采集叶子,并不直接把它们作为食物,而是将其运回巢穴中的真菌“花园”,种植一种特殊的蘑菇。这些“花园”可以被称为蚂蚁的“蘑菇农场”,被用于喂养蚂蚁幼虫。蘑菇依赖蚂蚁提供的叶子作为养料,蚂蚁幼虫依赖蘑菇所提供的养料,而成虫则以树汁为食。早在 1500 万年前,切叶蚁就开始和真菌结伴,形成了这样的共生关系,但这种关系的形成并非一蹴而就,大约累计耗费了 3000 万年才稳定下来。
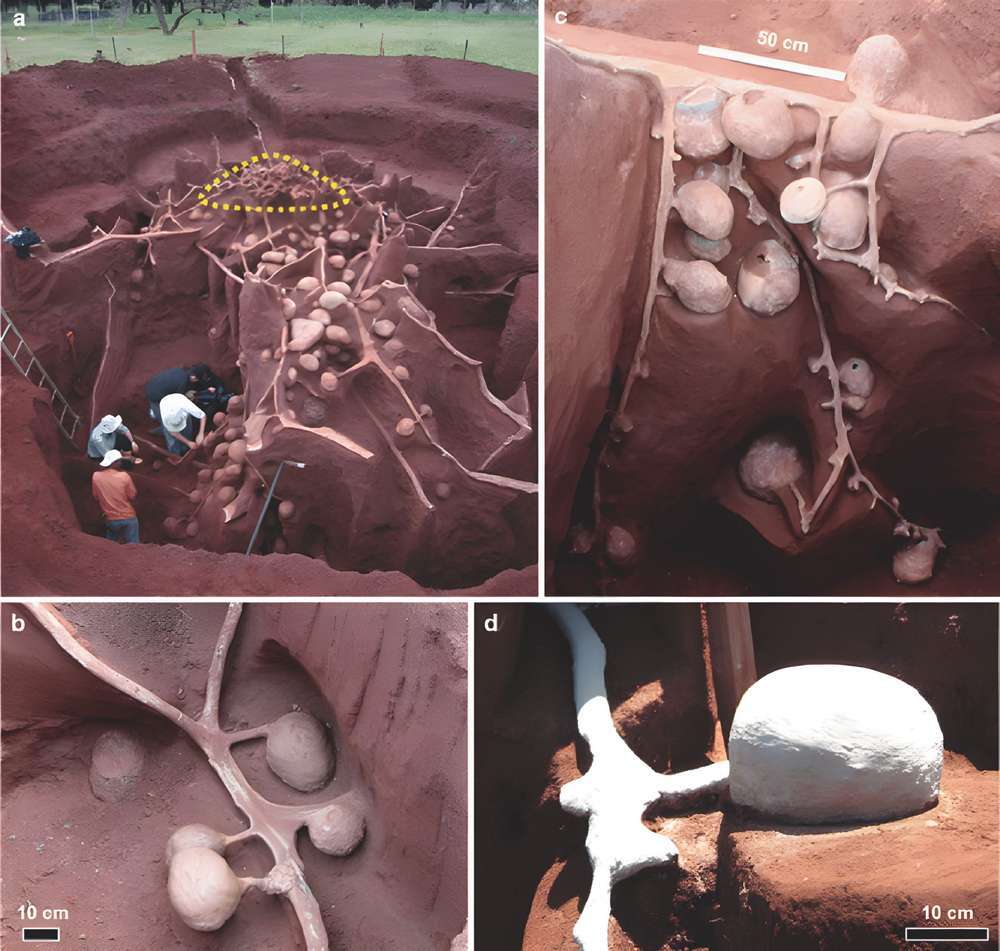
图 8-7 正在挖掘中的切叶蚁地下巢穴1
单只蚂蚁的生存能力有限,是无法单独存活的,但是当海量的蚂蚁聚在一起时,就形成了一种集体智慧。它们能够克服种种困难,拥有惊人的力量。如图 8-8 所示,蚂蚁可以靠身体搭桥就是一个很好的例子,这展现出蚂蚁拥有很高的生存智慧。全球蚂蚁数量约达 2 亿亿只,这个数是全球人口数量的 200 多万倍。

图 8-8 AI 绘画作品:蚂蚁搭桥
类似于切叶蚁这种集体行为的涌现,在自然界和人类社会中并不少见。比如鸟群、鱼群的群体行为,交通拥堵和城市的形态都是由大量的个体行为所导致的涌现效应。在 AI 领域中,深度学习算法的涌现也是一种类似的现象。
从伽利略到牛顿,经典力学被逐渐建立,它为我们的物理世界观奠定了基础。这一时期,机械决定论成为科学界的共识,其核心思想就是还原论,主张通过对研究对象进行不断分解和细化,寻找更底层的规律,这样就可能解释世界上的一切现象,并预测一切。
而相对论和量子力学的横空出世,颠覆了经典物理学所树立的世界观。渐渐地,人们发现还原论无法解释某些东西。于是,复杂性科学诞生了。复杂性科学是一门非常年轻的科学,专门研究复杂系统的运作规律。1984 年,圣菲研究所成立后,复杂性科学才得到一定的发展,其中最出名的研究者当属斯蒂芬·沃尔弗拉姆,他的研究对象之一是元胞自动机。
复杂性科学的研究分支有很多,如图 8-9 所示。举些生活中的例子,当我们听人唱歌时,鼓掌的频率会随着唱歌者的快慢同步起来,这是因为触发了某个条件;同一寝室的女生生理周期会逐渐趋于接近。这些例子反映了复杂性科学中的协同理论。我们听说过蝴蝶效应,即复杂系统的初始状态的微小变化能够引起系统的巨大变化,这是复杂性科学的另一个分支——“混沌理论”。
图 8-9 复杂性科学的可视化分支图
涌现是复杂性科学中的一个核心概念,它描述了在诸多相互作用的个体所组成的系统中,全新行为模式的出现。同时,新的现象往往不能从单个个体推断或预测出来。在自然界中,最典型的涌现现象包括蚂蚁、鸟群和鱼群等生物群体的集体行为。在社会生活中,涌现现象也很常见,例如社交网络中的病毒式传播、股价的波动、网红商品的流行等。某个事件上微博热搜在其发生之前几乎是不可预测的;在万人演唱会现场,总会涌现出一个人听歌时所不存在的情绪,这些都是涌现。有人认为,人和人之间不过是利益交换,从复杂性科学来看,这种世界观很狭隘。在很多人聚集起来后,就会涌现出单独个人所永远也无法得到的情绪和智能。
在 ChatGPT 惊人的智能表现背后,就发生了智能涌现的现象。我们来看一下 5 个语言模型在不同计算数量级上的表现,如图 8-10 所示。
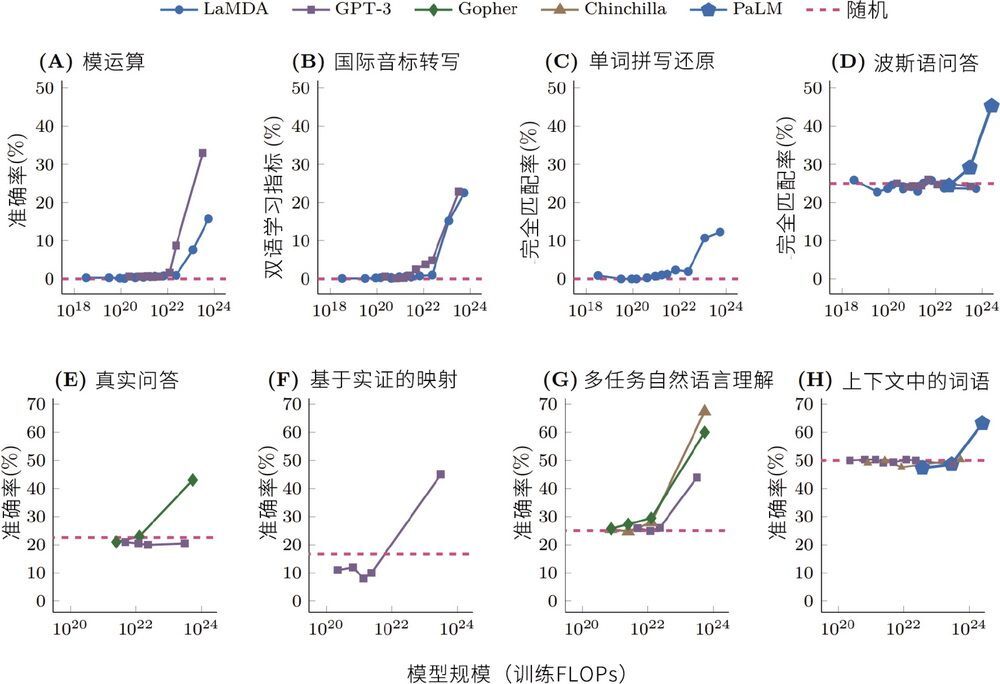
图 8-10 5 个语言模型(LaMDA、GPT-3、Gopher、Chinchilla 和 PaLM)的 8 种涌现能力2
图 8-10 中的 8 张图代表不同模型在 8 种人类任务中表现出的测评结果。横轴代表神经网络的 FLOPs(总计算量),纵轴代表准确率(可以理解为模型的表现分数)。每张图中的横向虚线代表随机性能(可以理解为随机选择的表现)。随机性能不是零分,比如做选择题,就算一道都不会,总分是 100 分的四选一选择题(每题 5 分)靠猜也能拿 25 分。我们可以明显看到,当计算规模达到 1024,也就是一亿亿亿次运算时,所有的模型都涌现出了新的完成任务的能力。
我们再来看一个惊人的例子,如图 8-11 所示。

图 8-11 神经网络在训练过程中被要求计算同余加法 a + b (mod m)
在《通过机械可解释性进行 Grokking 进展测量》3(“Progress Measures for Grokking via Mechanistic Interpretability”)这篇论文中,神经网络在训练过程中被要求执行一个特定任务,即计算同余加法 a + b (mod m)。在训练的某一时刻,神经网络突然达到了 100% 的准确率,这意味着它找到了一种解决方法。通过分析神经网络的行为,研究人员发现神经网络实际上学会了利用傅里叶变换来计算同余加法。这可以理解为,神经网络利用钟表画圆解决了一个代数问题。傅里叶变换是一种数学工具,即便是大学生通常也不用傅里叶变换来计算同余加法,所以这是一种出乎意料且反人类直觉的发现。
不少人评论说人工智能只会归纳,不会推理,显然他们没有了解过这些惊人的案例。同余加法是一个代数领域的数学问题,通过傅里叶变换,它被转化为几何问题,这是代数和分析数学的交叉。这种转化求解的方法让复杂的问题变成了更简单的形式。人工智能在数学这样高度抽象的领域中展现出惊人的推理能力,而这只是冰山一角。
类似的解决问题的办法体现在费马大定理的证明上。费马大定理是数学史上的一个著名定理,其主要内容是:对于任意大于 2 的整数,关于 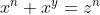 不存在正整数解。直到 1994 年,英国数学家安德鲁·怀尔斯才找到了一个完整的证明方法。怀尔斯的证明过程非常复杂,他把这个数论问题转化为椭圆曲线和模形式进行求解,最终完成了证明。
不存在正整数解。直到 1994 年,英国数学家安德鲁·怀尔斯才找到了一个完整的证明方法。怀尔斯的证明过程非常复杂,他把这个数论问题转化为椭圆曲线和模形式进行求解,最终完成了证明。
数学家陶哲轩曾被认为是世界上智商最高的人(智商超过《生活大爆炸》中的谢尔顿)。陶哲轩声称已经把多种 AI 工具纳入了自己的工作流。“大到寻找公式、辅助证明定理,小到改写论文语句、查询小语种数学名词的发音”,陶哲轩都会使用 ChatGPT。虽然 ChatGPT 并不能直接给出答案,但是已经可以辅助陶哲轩研究极为艰深的数学问题了,可见 ChatGPT 的智能深度不容小觑。
为什么是 OpenAI 第一个做出了具有上千亿参数的 GPT-3,并为 ChatGPT 的成功奠定了基础?从 2019 年 2 月发布在 OpenAI 的官方博客上的一张图中,我们可以发现一些线索。
图 8-12 展示了 GPT-2 的性能表现。图中的横轴代表模型的参数量,其最右侧的“1542M”指的是 GPT-2 拥有大约 15 亿的参数量。图中的曲线上共有 4 个点,如果我们仅看右侧 3 个点,可以看到参数量每增长一倍,测评指标会提升 6% 左右。如果想从最右侧点的 55% 显著提高到约 90%(人类水平),那么至少需要 7 个 6%,所以参数量可能需要 2 的 7 次方,即 128 倍。而 GPT-3 的实际参数量是多少呢?是 1750 亿个参数,大约是 GPT-2 的 15 亿参数量的 117 倍。这一数值非常接近 128 倍了。GPT-2 的参数量约是 GPT-1 的 13 倍,而 GPT-3 的参数量约是 GPT-2 的 117 倍,倍数已跃升至三位数。这就是我们对为什么 OpenAI 押注千亿级参数量的一个可能猜测。
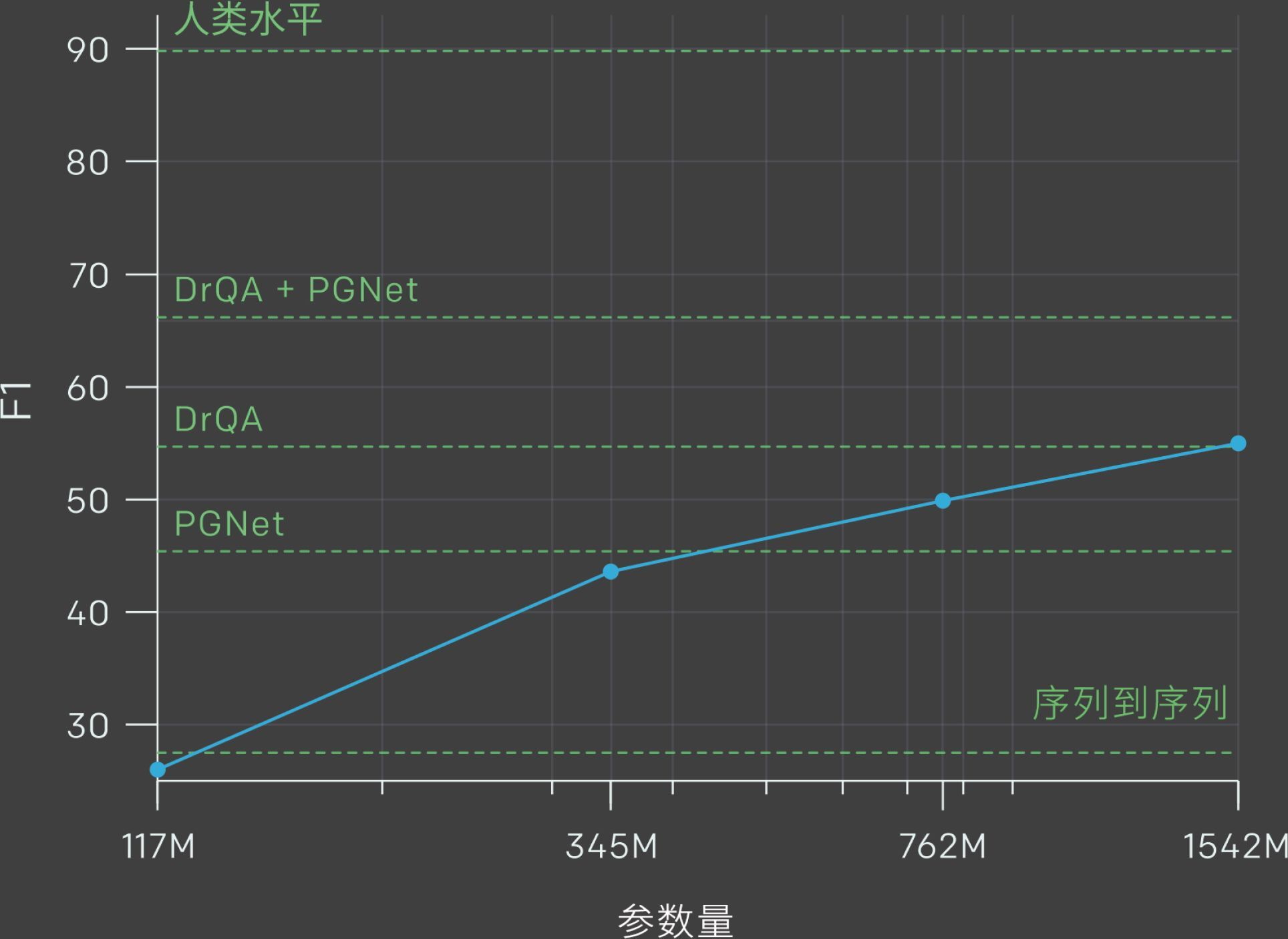
图 8-12 OpenAI 的官方博客展示了 GPT-2 的性能表现
大模型是一种非常庞大的自然语言模型,被用来处理很多文本任务。我们还是来问问 ChatGPT 什么是大模型,如图 8-13 所示。

图 8-13 ChatGPT 对“什么是大模型”的回答
大模型的核心要义就是“大”,就是“力大砖飞”的大,就是“大力出奇迹”的大。大,才是大模型的核心特征。OpenAI 在研发 GPT 大模型上至少花费了数亿美元的成本,用掉了数万块 1 万多美元的英伟达 A100 显卡。相比之下,中国拥有万块 A100 显卡的公司屈指可数。让我们通过图 8-14 来看看 GPT 系列大模型的性能表现。
图 8-14 本图展示了所有 42 个以准确度命名的基准的总体性能。虽然零样本性能随着模型大小的增加而稳步提高,但少样本性能增长更快,这表明较大的模型更擅长上下文学习4
涌现现象是极为复杂的,因为复杂性科学就是研究复杂的,复杂是其基本特征。而所有复杂性科学的分支都是新科学,我们还远远没有搞清楚。例如,涌现现象并非只有自下而上,也可以自上而下。很多年前,美国神经外科医生马克·雷波特在进行清醒开颅手术时,发现了一个惊人的现象。他有意创造欢快的气氛和病人交谈,聊一些生活八卦,在病人不知情的情况下向病人的嗅球(也就是嗅觉相关脑区)提供微弱的电流刺激。第一次,雷波特先用欢快的口吻与病人交谈,谈论即将到来的春季周末等话题,然后趁着病人专注于闲谈之时向嗅觉相关脑区施加微弱电流刺激。病人会突然打断对话,说:“谁把玫瑰花拿进来了?”过了一段时间,雷波特把谈话内容转向一些负面话题,并再次提供强度和位置与第一次完全一致的电流刺激。病人会再次打断对话,但第二次说的是:“谁把臭鸡蛋带进来了?”
目前,在大模型的智能涌现方面,我们只有 3 个结论。
第一,我们不知道什么时候会涌现某种新能力。
第二,我们不知道到一定规模时会涌现哪一种新能力。
第三,我们唯一知道的是,只要数据量足够大,训练得足够深,一定会有涌现发生。
这也是大模型领域目前最激动人心的地方。人类的智慧可以分解为一项又一项的能力,就像是大学中的各种考试。由于涌现的复杂度,即便是 OpenAI,也不知道怎样得到以及得到什么新能力,它也是激进地试出来的。ChatGPT 第一个版本 GPT-3.5 验证了智能涌现的参数量是在 100 亿到 1000 亿这个数量级范围内。现在,大模型解锁了一项又一项的新能力,而最可怕的是,我们目前看不到这种新能力的上限。
珠峰级工程
“我们正处在人工智能的 iPhone 时刻。”在 2023 年 3 月 21 日的 GTC 大会上,这句话被总是身着发亮皮衣的“AI 教父”黄仁勋反复强调了 3 次。
英伟达的 GTC(GPU Technology Conference)大会是一个年度性会议,旨在展示英伟达公司最新的 GPU 技术和应用。自 2009 年以来,GTC 大会已经成为全球 GPU 技术领域的重要盛会。英伟达 GTC 大会不仅仅是全球游戏迷倍加关注的大事,在 2012 年深度学习兴起之后,它也成为呈现 AI 领域重要进展的地方。
原本 GPU 是进行游戏计算的显卡,但是 2012 年之后,英伟达的命运就已经悄然发生改变,GPU 成为进行大规模 AI 计算的不二之选。英伟达在最近的 10 年内,公司市值从几十亿美元增长到超过 1 万亿美元。而英特尔没有赶上 AI 计算的浪潮。截至 2023 年 3 月,英特尔的股价仅仅相当于 2015 年前的股价,也就是说,一个英伟达的市值大约等于 8 个英特尔的市值,如图 8-15 所示。
2016 年,黄仁勋向 OpenAI 赠送了内置强劲 GPU 的 DGX-1(图 8-16),并寄语:“致马斯克和 OpenAI 团队!为了计算和人类的未来,我将世界上第一台 DGX-1 送给你们。”这台 DGX-1 能极大地缩短 OpenAI 对大模型的训练时间。马斯克也发推文表示了感谢:“感谢英伟达和 Jensen 将第一台 DGX-1 AI 超级计算机捐赠给 OpenAI,以支持人工智能技术的普及。”
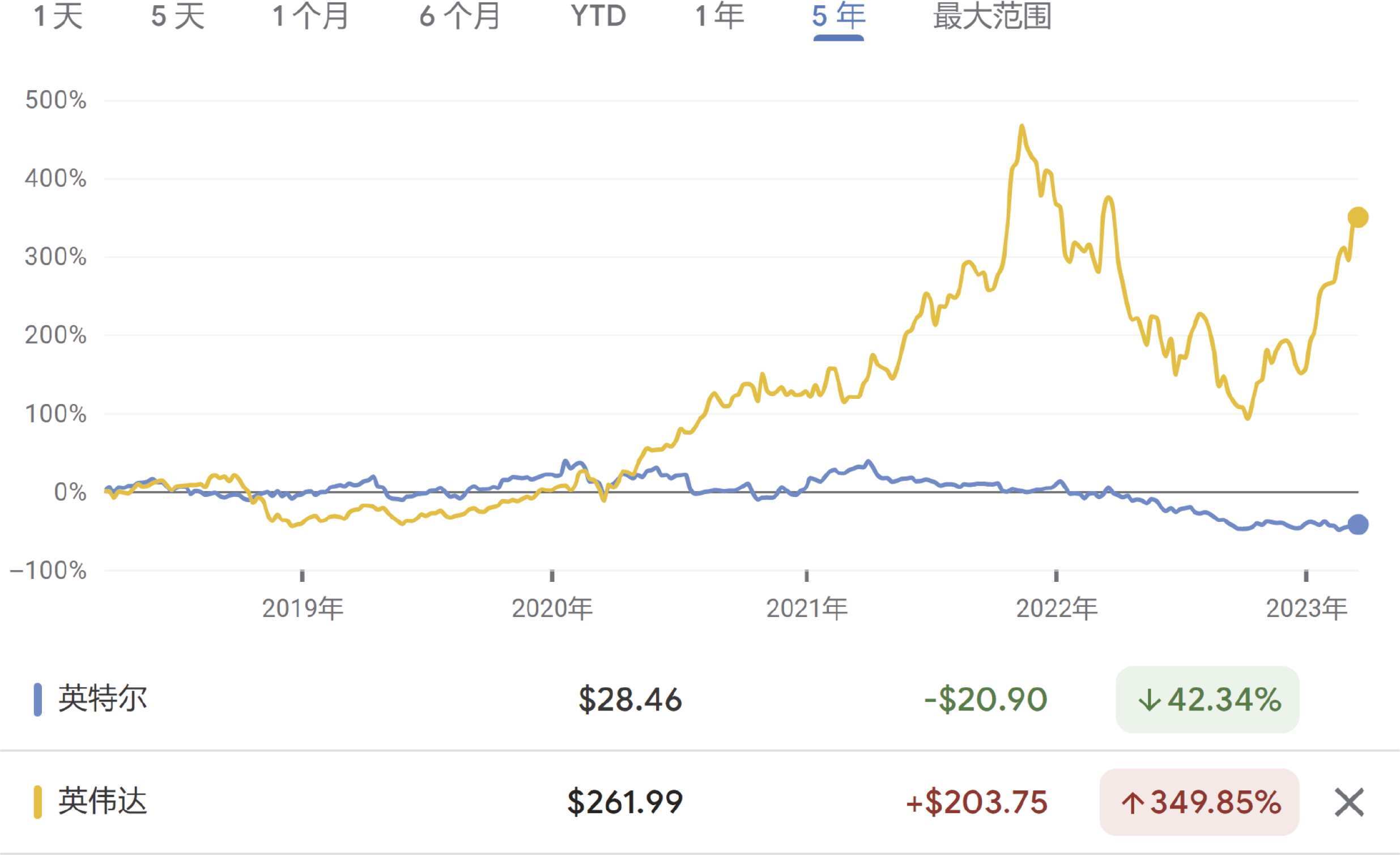
图 8-15 2019 年~ 2023 年英伟达和英特尔的股价对比

图 8-16 2016 年,黄仁勋向 OpenAI 赠送内置英伟达 GPU 的 AI 超级计算机
从图 8-17 中,我们可以看到从 2012 年起,深度学习改变了一切,技术范式发生了重大变化。从 2017 年起,以 Transformer 架构为基础的 GPT 系列模型等大模型的兴起,更是把神经网络计算推到了更陡峭的增长山坡上,技术范式再次发生变化。
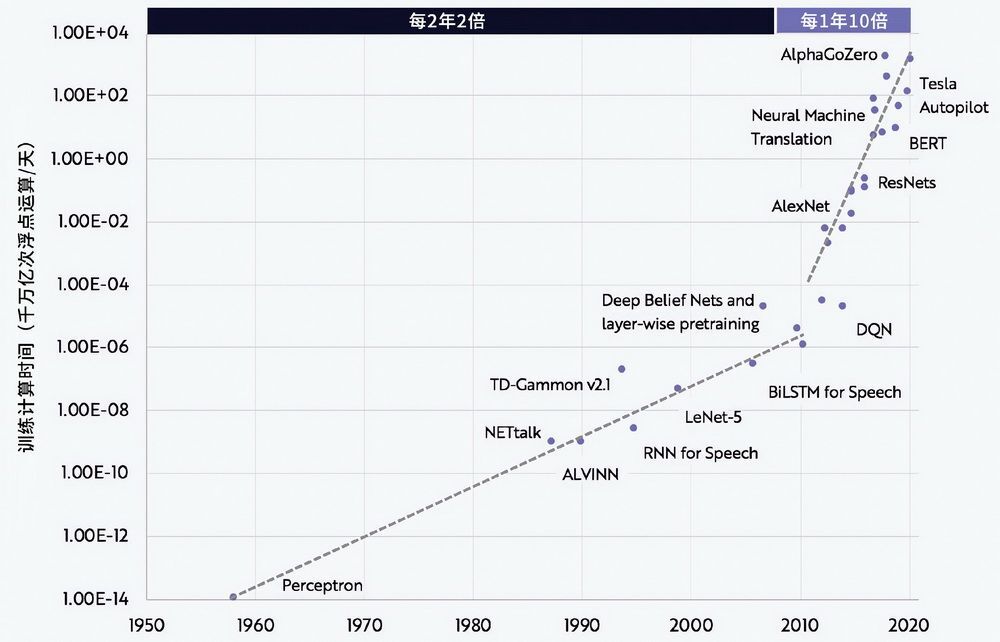
图 8-17 AI 模型训练的两个计算时代5
从图 8-18 可以看到,根据摩尔定律,每 2 年计算速度会增加 1 倍。而计算机视觉、自然语言处理等传统 AI 神经网络的训练规模的增长速度是大约每 2 年增长 15 倍。以 ChatGPT 为代表的 Transformer 模型运算量规模更为夸张,以大约每 2 年 750 倍的速度超速增长。从移动互联网浪潮开始到现在,不过短短十几年时间,人工智能居然经历了两次技术范式变化。最初是古典人工智能,之后出现的第一次变化是 2012 年开始的深度学习,可被称为传统人工智能。第二次变化是 2017 年开始的大模型,可被称为 GPT 人工智能,它让我们明白了只有大模型才是全新的未来。
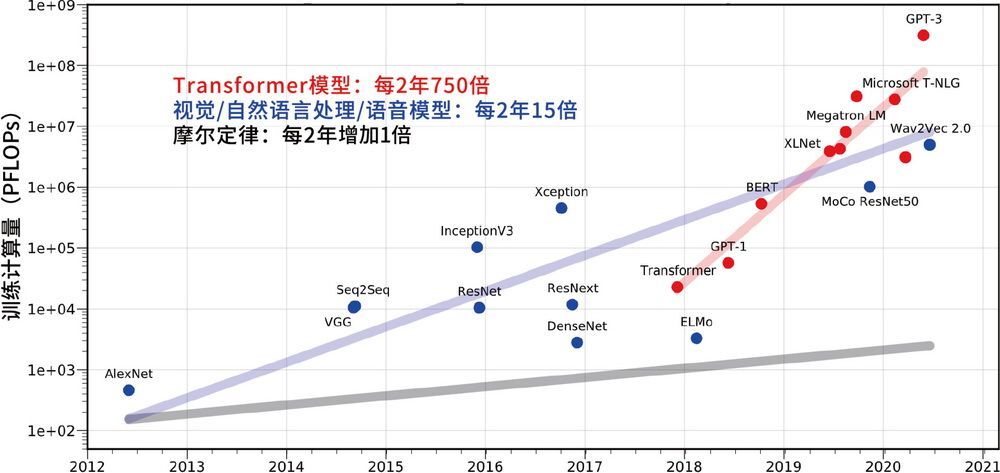
图 8-18 计算机视觉、自然语言处理、语音模型算力增长速度对比6
传统人工智能就像专才,即便是自然语言任务,也分为很多工种,比如做翻译的只做翻译,做信息检索的只做检索,做摘要的只做摘要;大模型就像通才,不是为某一项任务而生的,而是在每一个任务上都做得更深、更透,因为大模型是更深度的人工智能。
大模型的计算规模是如此恐怖,以至于大模型是一个珠峰级工程。对于普通的创业者来说,真正的大模型是完全无法染指的。举个例子,用于训练 ChatGPT 的英伟达高端显卡 A100,不仅内存高达 80 GB,有 7000 左右的 CUDA 核心数量,而且每秒的 GPU 内部显存传输速率高达 2 TB,GPU 之间的数据交换量每秒接近 1 TB。OpenAI 在探索阶段至少投入了数亿美元,才训练出有着 1750 亿参数量的庞然大物。经过很多优化,大模型的训练成本已经降到数百万美元,但是如果要研发最先进的大模型,仍至少需要 1 亿美元。随着大模型开源化和小型化的趋势,被训练好后的大模型就可以装到高配的个人计算机上运行了。目前谷歌、微软、Meta 等,都在超级计算上投入巨资。这是一场“烧钱的军备竞赛”。

图 8-19 微软 Azure 发布了英伟达 H100 AI 超级计算机的私人预览版
最大未解之谜
科幻电影《降临》讲述了一个外星人拯救地球的故事。故事主线是一位语言学家破解外星生物“七肢桶”的非线性语言,从而和外星生物实现了接触,获得了预知未来的能力。《降临》改编自科幻小说《你一生的故事》,是华裔科幻作家特德·姜的著作。
对语言理解很深的特德·姜于 2023 年 2 月在美国杂志《纽约客》上发表了一篇关于 ChatGPT 的评论文章,题目为“ChatGPT Is a Blurry JPEG of the Web”(ChatGPT 是网络上的一个模糊的 JPEG 文件)。这篇文章从压缩的角度,对 ChatGPT 的智能涌现提供了一个非常新颖的理解视角:大模型的预训练,实际上是一种有损压缩。这种观点非常奇特,认为压缩是一种理解。文章举例说,如果你要最大压缩一个包含 100 万个加减乘除例子的文本文件,那么可以通过理解其中加减乘除的规律从而压缩掉很多重复的答案;在解压缩时再通过计算还原出原始文本。由于 ChatGPT 不能精准还原原始文本,只是模糊地记住了规律,在回答问题时通过计算再差值拼凑出原貌,就像有损压缩的 JPEG 图片一样。
为什么仅仅通过概率预测的文字接龙,ChatGPT 就实现了上百种的人类技能呢?没有接受任何针对性训练,就实现了翻译、写作、思考、角色扮演等人类技能,这种深度理解和思考能力,其本质是什么呢?
OpenAI 的技术负责人杰克·雷有另一种解释:ChatGPT 的本质是一个无损压缩器。杰克在一次名为“压缩,用于通用人工智能”的视频连线分享中,提出了压缩即智能的观点:通用人工智能大模型的目标是实现对有效信息最大限度的无损压缩。他举了一个精妙的例子,这里我用更好理解的语言重新描述一下。
假如一个完全不懂英文的人,把全世界由英文翻译成中文的所有翻译任务,都写入一本翻译词典,然后由另一个不懂英语的人来用这本翻译词典做翻译,那么会出现两个问题。
一是,这本词典极厚无比,历史上所有翻译过的任务都在这本词典里。
二是,一旦要翻译的句子或词组没有出现在这本词典里,那就无法翻译了。
如果要把这本词典变薄,那么就需要深入地理解语言规律,这样就不需要列出所有句子的对应翻译,只需列出所有用法。通过压缩这本词典,就实现了对所有翻译任务的理解。压缩率越高,说明对原始文本理解得越深,实际上越能翻译出超出原始文本之外的其他文本,换句话说,其泛化能力越强。泛化能力就是举一反三的能力,它越强越好。例如,小朋友通过学习 2 个苹果加 3 个苹果是 5 个苹果,就会算出一个包子铺卖包子、馒头、油条一天一共卖了多少元,这就是一种泛化能力。
特德·姜的有损压缩理论很好理解,因为 ChatGPT 不能精确还原原始文本。那么杰克的无损压缩理论该如何理解呢?这是其中最深奥的地方。无损压缩既不是指原始文本,也不是指文本背后所体现的物理世界,而是指最小描述、本质知识。大模型的压缩率越高,大模型对所有语料所体现的物理世界理解得越深。
有损压缩和无损压缩并不是对大模型的“唯二”解释,还有很多人有不同的看法。对大模型深层真相的追求不仅有助于深刻理解其本质,而且可以树立解决问题的目标。不过,需要补充说明的是,GPT-3.5 压缩之前的数据量大概是 570 GB,压缩后数据量仍是几百 GB,数据在压缩体积上的变化并不大,而压缩后的大模型却发生了翻天覆地的变化。
学习、理解、推理的本质是什么呢?举个例子,一个人读一本学科教材,往往开始时会感觉越读书越厚,记的笔记也非常多,但在学习了同一本书很多遍之后,反而觉得书越读越薄。这个过程中大脑神经网络到底经历了什么?目前并没有一个全面的答案。
大模型有很多未解之谜,例如,ChatGPT 的智能涌现造就了思维链(Chain of Thought,CoT)现象,进而造就了提示词工程(Prompt Engineering)的深度使用技巧。思维链现象从何而来?人工智能研究员符尧等人的论文《拆解追溯 GPT-3.5 各项能力的起源》中提到了思维链来自代码训练的观点。ChatGPT 在预训练阶段,也读取了大量的代码,使用思维链进行复杂推理的能力很可能是代码训练的一个神奇的副产物。代码是逻辑性极强且非常精准的语言,代码训练可以学到自然语言中相对较弱的逻辑思维。
大模型的智能涌现就是人类智能吗?显然不是。ChatGPT 在某些方面极为出色,但在某些方面非常糟糕。例如,ChatGPT 在最初的版本里,判定 27 是一个素数。在非常先进的 GPT-4 中,在回答“congratulations 的第 12 个字母是什么”这个问题时,会给出错误答案“t”,正确答案应该是“i”。深度学习之父杰弗里·欣顿把 ChatGPT 比作白痴天才,这是一个非常精准的比喻。大模型可以计算素数,但是目前还做不到发现素数。让我们来做一个思想实验。如果将目前最先进的大模型穿越回古希腊时期,哪怕“喂”给大模型当时的所有语言数据,大模型可能还是无法证明素数有无限多个。而 2300 年前的欧几里得就能证明出素数有无限多个。
虽然大模型已经具备了理解能力,但是这种理解能力到底有多强?欣顿在采访中提到了物理学家理查德·费曼的理念:“除非你能在实践中构建它们,否则你无法真正理解事物。这才是对你是否理解它们的真正考验。”
大模型的智能涌现是最大未解之谜,这个谜包括很多子谜:智能涌现来自哪里?智能涌现的上限在哪里?预训练是不是一种压缩?到底何谓智能?到底何谓理解?到底何谓学习?为什么大模型存在 AI 幻觉?提示词工程的潜力到底有多大?这些谜题等待着人类逐步解开,对通用人工智能的探索永无止境。

ChatGPT 的梦 作者:CCOPunk
精选留言