朝闻道,夕死可矣。
——孔子
自然语言模型
在澳大利亚墨尔本的一个郊区,老奶奶安妮·斯科特勇敢地开始了一段不寻常的探索之旅。斯科特奶奶出生于 20 世纪 30 年代,那时正是大萧条时期,通用电子计算机尚未问世。在世界动荡不安的时期,她跌跌撞撞地长大了。历经沧桑的斯科特退休后回到自己熟悉的童年家园。时间一晃到了 2019 年,此时的她已经 85 岁高龄,却怀着年轻人的好奇心和勇气申请并进入了斯威本理工大学,开始了一段研究课题为“人类与智能机器的融合:想象未来世界”的博士生涯。她成为该校最年长的一位博士生,研究的是地地道道的人工智能问题。
今天,ChatGPT 已经展现出如此令人惊艳、神奇的效果,这吸引了无数人的目光,甚至连那些从未接触过代码的人,也想一探究竟,了解这一切究竟是如何发生的。现在我们就以安妮·斯科特 85 岁学人工智能的勇气和热情,不用复杂的公式,用通俗易懂的语言,给一位正在北京中国科学院某小区旁边买煎饼馃子的张奶奶讲明白,怎样动手“搓”一个 ChatGPT 出来。
这位在中国科学院工作了一辈子的张奶奶有着很高的科学素养。张奶奶刚刚退休,已经开始体验 ChatGPT 这一聊天机器人,但是她还不懂人工智能。张奶奶的第一个问题是:“为什么不同的人问 ChatGPT 完全一样的问题,或者一个人问两次,ChatGPT 给的答案每次都不是完全一样的,而是有轻微变化的呢?”
如图 4-1 所示,张奶奶问了她年轻时看到的一个关于《西游记》的问题。

图 4-1 张奶奶问 ChatGPT 的第一个问题
随后,张奶奶又问了一次。ChatGPT 的回答如图 4-2 所示。

图 4-2 ChatGPT 对同一个问题给出略微不同的回答
确实,两次回答表达了同一个意思,不管唐僧是不是真的爱上过女儿国国王,反正 ChatGPT 认为唐僧没有爱过。在第二次回答中,ChatGPT 的用词发生了显著变化,例如使用“取得真经”“爱情线索”等词,语言描述也发生了变化。
我们拿同样的问题问搜索引擎,它的表现如图 4-3 所示。
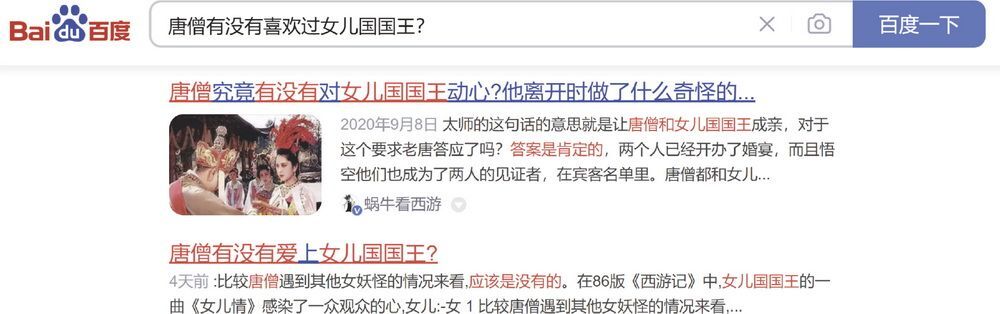
图 4-3 搜索引擎给出的答案
ChatGPT 和搜索引擎返回的结果是截然不同的。在搜索引擎里,搜 100 次,结果都是一模一样的。搜索结果来自多个网页,对于以上问题,前两个结果给出不同的答案:一个是爱,一个是不爱。
搜索引擎是宇宙级规模的知识仓库,而人工智能模型 ChatGPT 更像一个日渐成熟、熟读天下书的天才少年。两者在本质上截然不同。以谷歌为例,其搜索引擎的收录量在万亿数量级以上,网页体积在 10 000 TB 数量级以上,而 ChatGPT 的神经网络模型体积还不到 1 TB,只有几百 GB,两者至少相差了 10 000 倍。
想象一下,有两个图书馆:一个图书馆叫谷歌,其中收录了 100 亿本书;另一个图书馆叫 OpenAI,尽管规模较小,但它剔除了垃圾内容,只收录了价值连城的 100 万本书。在 OpenAI 这个图书馆里有一位少年,他从来没有见过图书馆外面的世界,就读完了这 100 万本书。他并不是逐字地背书,而是熟练学到了书上的所有内容。这个天才少年,就是 ChatGPT。
搜索引擎是一个互联网存储仓库和检索器。当我们向它提问时,它会毫不犹豫地为我们找到最相关的 10 个答案,这些答案来自已经存在的网页。无论查询多少次,它都会提供相同的结果。而 ChatGPT 是一个自然语言模型,它不存储具体的原始数据。当我们向 ChatGPT 这个在图书馆里长大的少年提问时,他每次的回答都会略有不同,因为每次的答案都是新生成的。因此,ChatGPT 给出的答案往往在搜索引擎中是搜不到的。来看一个简单的类比:假设你很了解《西游记》,如果你给张奶奶讲 10 遍《西游记》,那么你每次讲的内容并不完全一样,因为你不可能把整本《西游记》逐字背下来。如果你的记忆力特别好,那么你讲的情节会非常准确,但是用词肯定会有所变化。
另外,目前 ChatGPT 模型本身在生成答案时是离线的,而不是联网的。因此,ChatGPT 目前不会通过搜索来给出答案。
当我们多次向 ChatGPT 提出相同的问题时,它其实会表现出很高的一致性,不过每个答案在具体用词上会有细微的差别。就如同一个诚实的孩子,只要掌握了相关知识,它就会尽力告诉我们正确的答案。然而,遇到不了解的问题,它就会胡编乱造答案,所以 ChatGPT 目前还有胡说八道的毛病。有时,我们很难看出来答案中的哪些内容是胡编的。
生成式模型
ChatGPT 对谷歌搜索引擎产生了很大的冲击,因为两者在解决用户需求方面有着天壤之别。谷歌搜索引擎依赖于互联网上已有的内容来回答问题,缺乏真正的思考能力和创造能力。而 ChatGPT 拥有极高的智能,能够生成富有创意且贴近用户需求的内容。这种智能性就来自生成式预训练 Transformer(Generative Pre-trained Transformer,GPT)模型。我们从名字开始解构 ChatGPT,如图 4-4 所示。

图 4-4 从名字开始解构 ChatGPT
如果我们问一下 ChatGPT,小说《三体》好不好看,它会如何作答呢?请看图 4-5。

图 4-5 ChatGPT 认为小说《三体》非常好看
它背后发生了什么?实际上,ChatGPT 的作答过程如图 4-6 所示。
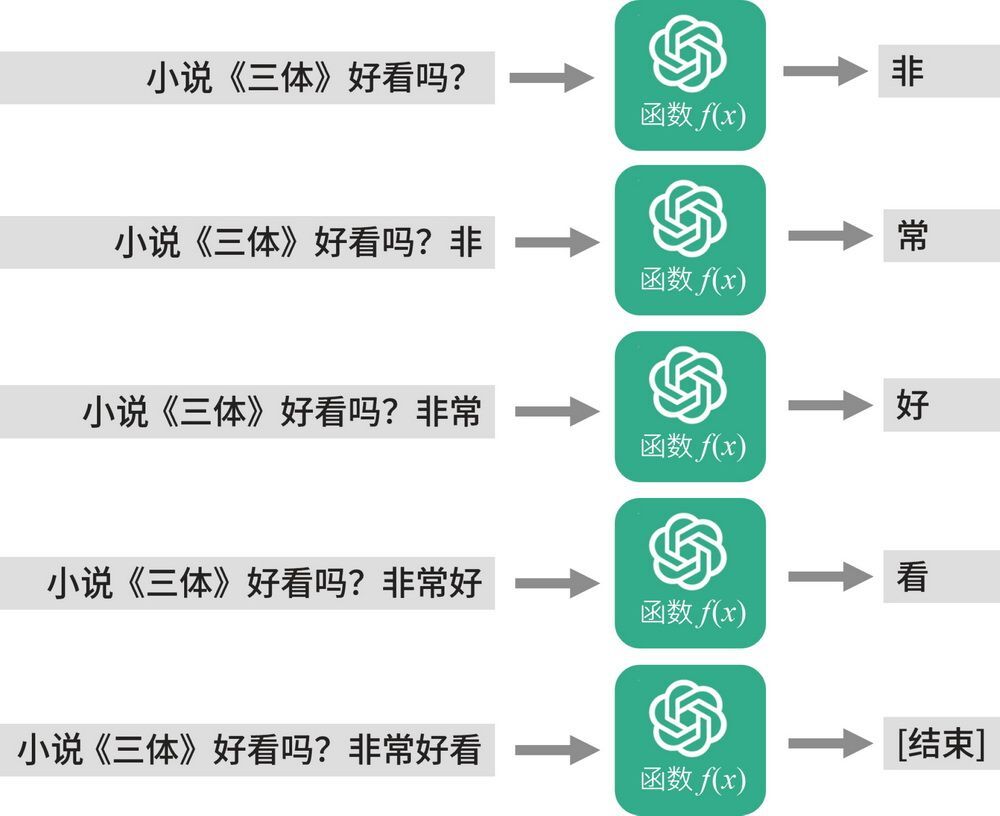
图 4-6 剖析 ChatGPT 的作答过程
这就是“生成”的基本原理,和我们人类聊天是一样的。再举一例,以下是一段互相表白的对话。
A :我喜欢你。
B :我也喜欢你。
在这段对话中,B 其实也经历了与 ChatGPT 一样的思考过程。
我喜欢你。→我
我喜欢你。我→也
我喜欢你。我也→喜
我喜欢你。我也喜→欢
我喜欢你。我也喜欢→你
当然,B 可能给出许多其他回答,如下所述。
[我]也喜欢你。
[我]需要点时间。
[谢]谢你。
[你]是个好人。
[那]我们在一起吧。
在[我喜欢你]之后,可能出现[我][谢][你][那]等很多字,它们都有不同的出现概率,如图 4-7 所示。从这些字中选出一个字后,再继续选择下一个字。
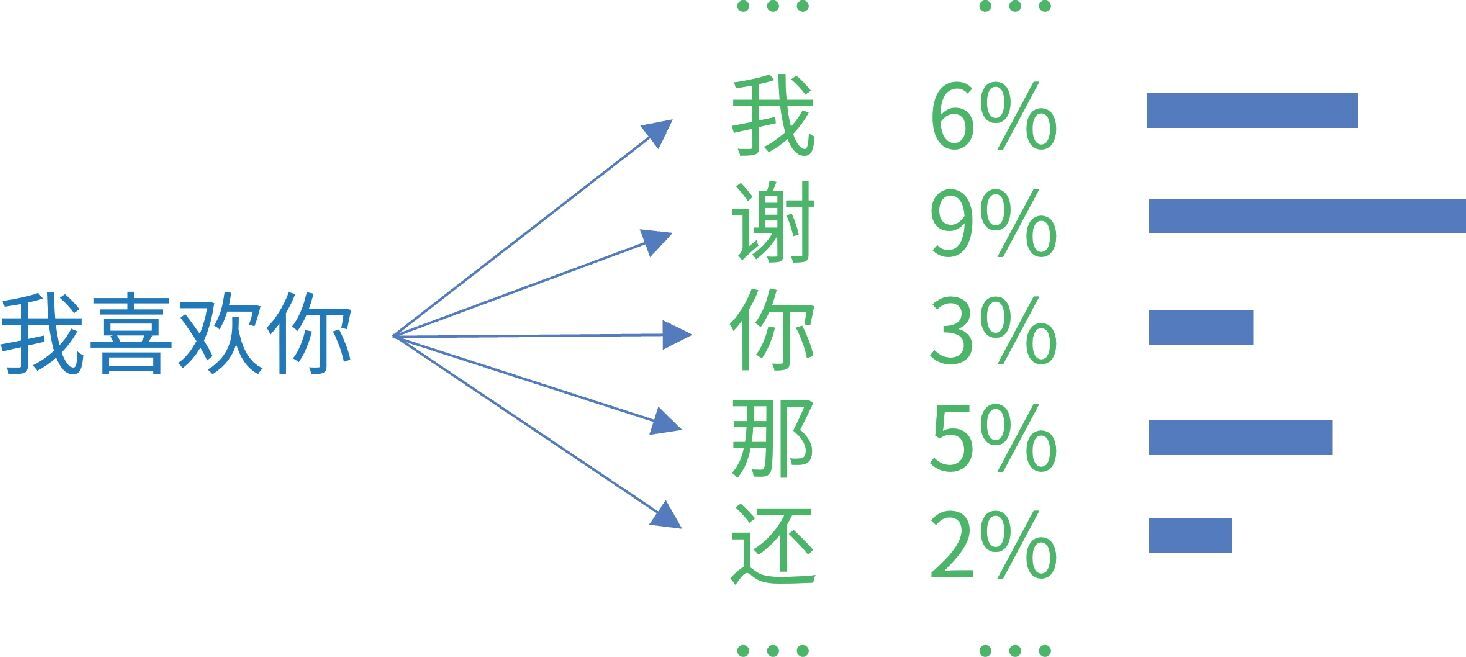
图 4-7 每个可能出现的字都有不同的出现概率
听了这些解释,张奶奶说:“那我懂了,这有点儿像我给孙子串手链,把珠子一颗一颗地串上去。而且,我可以根据花纹做调整。”的确如此,如图 4-8 所示。

图 4-8 AI 绘画作品:一个小女孩在串宝石项链
“奶奶,您的比喻很对。这在人工智能领域里叫作‘自回归语言模型’(Autoregressive Language Model),也就是说,每次吐一个字,然后根据历史记录和生成的字重新计算下一个字。”
“这也有点儿像织带图案的毛衣,每织一针就得回看一下整体图案是否正确,然后才能织下一针。”
“奶奶,您理解得太对了!”
这都是不同的概率涌现,同样是生成的。图 4-9 所示的模拟对话也是生成的。

图 4-9 ChatGPT 模拟对话
如果你来模拟对话,或许你也会以这样的结构回答。同理,翻译结果也是根据概率生成的。
在图 4-10 所示的例子中,当我们给出“翻译成英文”这个指令时,为什么 ChatGPT 能够隔着一段话,知道把最初的内容翻译成英文呢?这是因为每次作答时,ChatGPT 都会把前面所有的历史对话重新计算一遍,如图 4-11 所示。这样一来,它自然就知道需要翻译哪一句。

图 4-10 ChatGPT 能够正确识别需要翻译的内容
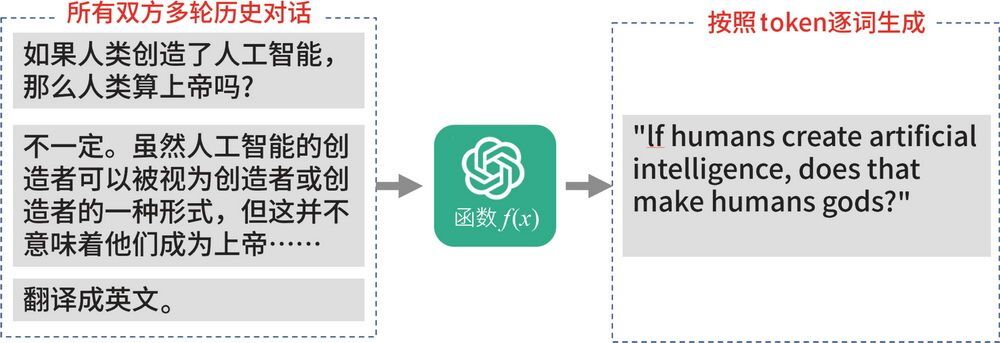
图 4-11 ChatGPT 翻译原理剖析
ChatGPT 支持几十种语言。无论你使用这些语言中的哪一种与 ChatGPT 交流,它都能够根据你的输入来自动确定最匹配的语言,并用该语言为你提供服务,这是基于概率的决策结果。也可以这样说:ChatGPT 拥有几十种母语,在它眼里,什么语言都一样,如图 4-12 所示。

图 4-12 ChatGPT 能够自如地切换不同的语言
我们来和 ChatGPT 对一下答案,如图 4-13 所示。

图 4-13 ChatGPT 对“生成式”的解释
再问一下,它是否按顺序生成内容,如图 4-14 所示。

图 4-14 ChatGPT 对内容生成方式的解释
张奶奶问:“那么两个人对话,也是两个人在根据上文生成内容吗?”
我回答:“答案非常正确!奶奶,您年轻时插过队吗?”
张奶奶回答:“我啊,年轻时啊,当然插过队了。”
我继续解释:“您看,您说的‘我啊’‘年轻时啊’,就体现了在顺序生成时需要计算响应时间。人们在聊天时,经常在所说内容里插入这样的口头禅,给大脑额外思考的响应时间。人们在演讲时,经常因为紧张或思路不清晰而断断续续,这就是因为想不起来后续该如何表述。”
我们来继续追问一下 ChatGPT,如图 4-15 所示。

图 4-15 继续追问 ChatGPT
在回答问题时,ChatGPT 就是一个字一个字地向外吐的,很多时候还会妙语连珠。有网友在评论 ChatGPT 的精彩回答时说道:“ChatGPT 明明可以给你直接甩答案,为了照顾你的阅读速度,才慢慢给你吐。”这条评论其实是不准确的,ChatGPT 和搜索引擎不一样,搜索引擎的答案是现成的,而 ChatGPT 的答案是顺序生成的。图 4-16 所示的这个细节可以反映这一点。
图 4-16 ChatGPT 在回答问题时会显示“Stop generating”按钮
ChatGPT 在回答问题时总会显示“Stop generating”(停止生成)按钮。我们来问问 ChatGPT 为什么会这样,如图 4-17 所示。

图 4-17 ChatGPT 解释显示“Stop generating”按钮的原因
我感觉 ChatGPT 这家伙有点儿不够实诚,因为我认为,省钱才是最主要的原因。于是,我继续逼问 ChatGPT,如图 4-18 所示。

图 4-18 继续逼问 ChatGPT
但是,请记住,ChatGPT 仍旧有很严重的 AI 幻觉问题,所以这个答案未必就是对的。实际上,推理芯片在进行生成计算时,会对多个问题进行打包处理。即便用户点击“Stop generating”按钮,也可能未必会取消内容生成。从产品设计的逻辑来看,也有可能是 ChatGPT 的产品经理认为,一些答案过于离谱,可以让用户主动取消,从而避免看到垃圾内容。最关键的是,这些取消反馈是很好的负反馈,有助于 ChatGPT 进行数据收集。具体这个按钮是否真的取消了内容生成,我们不得而知,但是 ChatGPT 的确是逐字生成内容的。
1000 亿参数的模型
张奶奶问:“我对那个函数 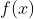 感兴趣。为什么这个函数这么厉害呢?”
感兴趣。为什么这个函数这么厉害呢?”
我答道:“奶奶,您问了一个好问题。ChatGPT 这个函数之所以这么强大,是因为它是一个超级巨大的神经网络。”
虽然神经网络在理论上是一个函数,但是它已经远远不是我们所认识的函数的样子。
图 4-19 展示了大脑神经网络的样子。

图 4-19 “大脑连接组计划”对大脑的一张扫描图
我们可以参考图 4-20 来理解 ChatGPT 这个超级函数。
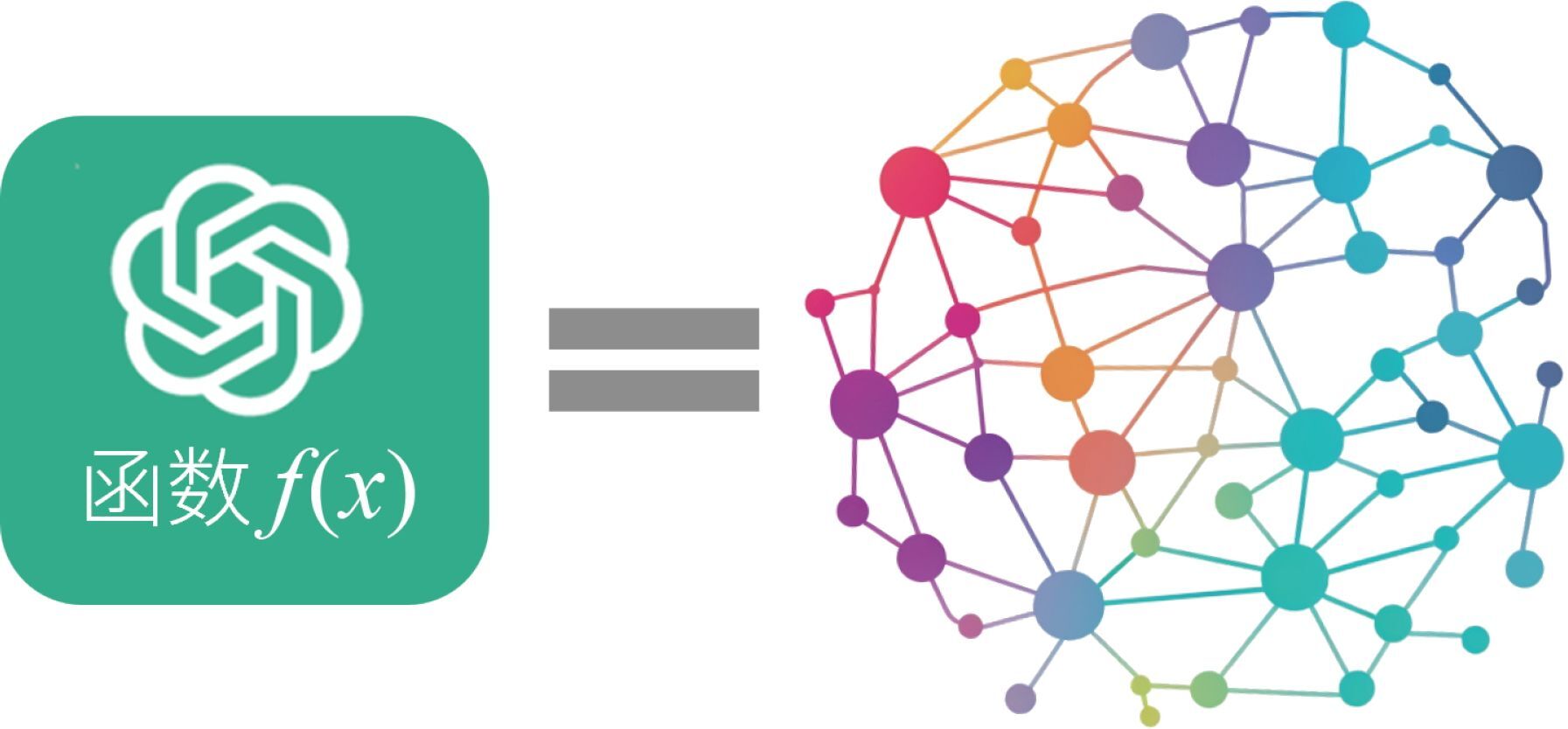
图 4-20 ChatGPT 的函数示意图
我们再来看一张大鼠大脑切片神经网络模拟图,如图 4-21 所示。
图 4-21 大鼠大脑切片神经网络模拟图(图片来源:瑞士洛桑联邦理工学院蓝脑计划)
可以看出,神经网络无比复杂。为了让张奶奶好懂一些,让我们回归到最简单的结构。图 4-22 展示了单个生物神经元和单个人工神经元。
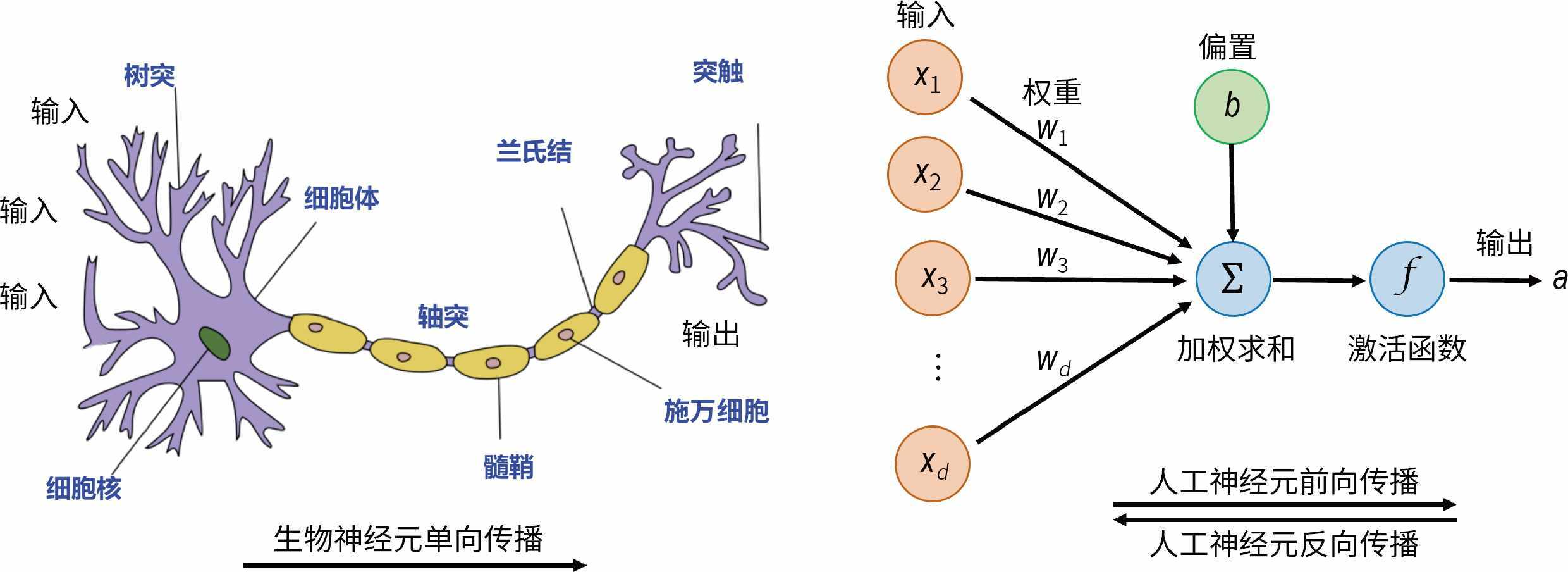
图 4-22 单个生物神经元(左)和单个人工神经元(右)
可见,两者是非常相似的。它们有如下共同点。
- 神经元都有特定的传输方向(但不同于生物神经元,人工神经元还可以双向传播)。
- 每个神经元的输出都对应着其他神经元的输入。
- 每个神经元在一定的输入下,要么激活,要么不激活。
如果看不懂也没关系,我们用 ChatGPT 来举例,帮助你理解,如图 4-23 所示。

图 4-23 ChatGPT 对单个神经元的解释
在 ChatGPT 给的答案中,“音量调节器”这个比喻最好,因为其中的音量旋钮是线性叠加的,如图 4-24 所示。举例来说,你可以分别调节主持人的音量和背景歌曲的音量,然后音响就会得到线性叠加的声音。我们可以发现,用 ChatGPT 来解释一些晦涩难懂的知识,同时结合打比方的提问,就能够帮助我们很快地学习新知识。

图 4-24 AI 绘画作品:一个布满音量调节旋钮的调音台
不过,当涉及多层网络时,情况就不一样了。我们来看一些不同类型的神经网络,如图 4-25 所示。
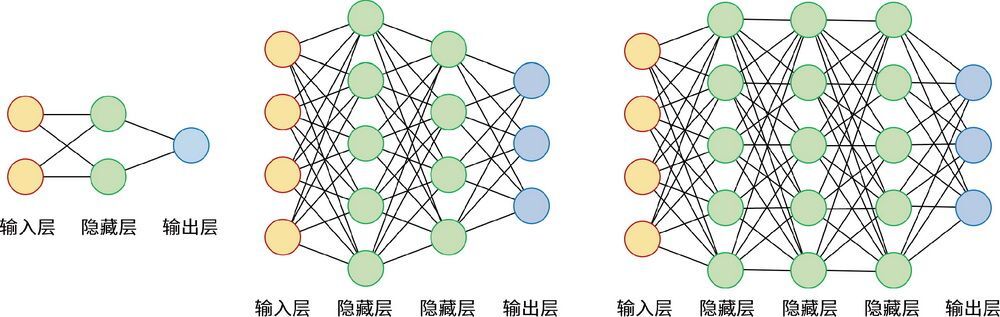
图 4-25 不同类型的神经网络
神经网络模型也被称为蛛网图,因为它和蜘蛛网长得很像。
实际上,神经网络模型要比图 4-25 所示的复杂得多。下面举一个手写数字识别的神经网络例子,如图 4-26 所示。
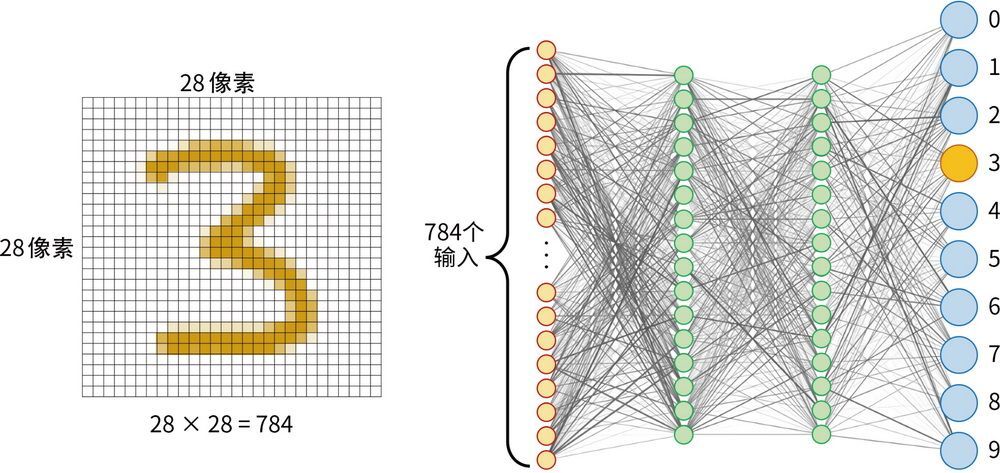
图 4-26 识别手写数字的神经网络
这是一个 28 像素×28 像素的手写数字识别神经网络。每一个圆点代表一个神经元,每条线代表神经元之间的连接,也就是一对突触,负责在神经元之间传递信号。每条线的权重就是一个参数,用于调节信号的强度。右侧的 10 个神经元是输出端,每次输出从 0、1、2、3 一直到 9,分别表示识别结果。
实际上,神经元的突触非常多,单个生物神经元的突触数量多达几百甚至几千个。每个突触看起来像是一个双头棒棒糖,这个棒棒糖的一端是几千个突触,另一端也是几千个突触,而且突触之间的信号传递是单向的,如图 4-27 所示。
图 4-27 突触之间的信号传递是单向的
接下来我们更进一步,看看 2012 年的里程碑式神经网络模型 AlexNet,如图 4-28 所示。
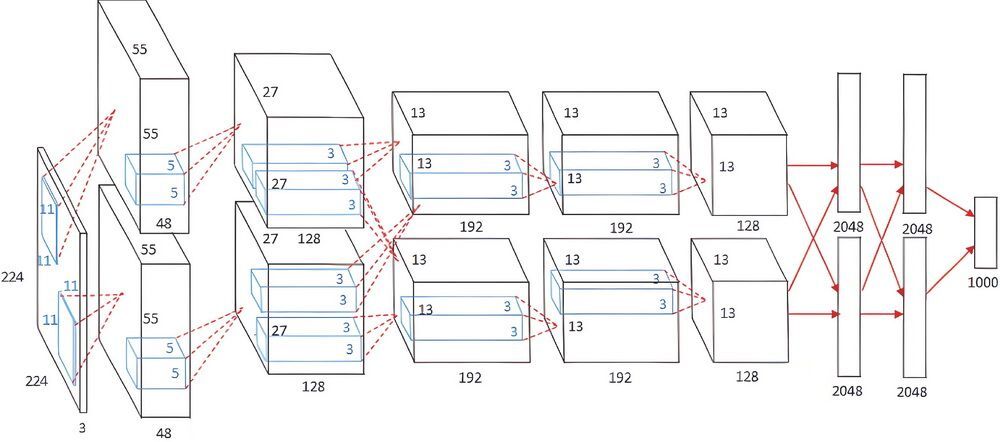
图 4-28 AlexNet1
暂且忽略图中的细节。我们可以看到,左侧是输入端,右侧是输出端。从左侧“喂入”224 像素×224 像素的图像,在右侧就会“吐出”一个 1 ~ 1000 的数,这就代表识别成功。每个数对应 1000 个图像类别之一,例如小狗、小猫等。AlexNet 有 650 000 个神经元和 6000 万个参数。
在一个复杂的神经网络中,不同层次的神经元负责处理不同级别的特征。最初级的神经元,就只能处理最初级的特征,比如边缘。越深层次的神经元,越能处理高级的特征。例如识别一只鸟,初级检测器检测到鸟的边缘后,组合成更大的特征,例如鸟嘴、羽毛等,由更深的检测器检测,最终由最高级的检测器检测整体形状。AlexNet 在 2012 年 ImageNet 大规模视觉识别挑战赛 2 中表现卓越,原因之一就是它在学习深度上层次更深。
我们来让 ChatGPT 举例说明视觉识别神经网络中的特征,如图 4-29 所示。

图 4-29 ChatGPT 举例说明视觉识别神经网络中的特征
我们再来看看自然语言中的特征举例,如图 4-30 所示。

图 4-30 ChatGPT 举例说明自然语言神经网络中的特征
理解了神经网络的基本原理,我们就可以继续讨论怎样“手搓”一个 ChatGPT 了。
两步“手搓”一个 ChatGPT
张奶奶问:“如果把大象关进冰箱需要三步,那么制作一个 ChatGPT 需要几步呢?”
ChatGPT 的研发过程极为复杂。不过,如果我们用最简单的方式去看,那么这个过程只有两步:预训练和微调。我们来继续深挖,怎样只用这两步,“手搓”一个 ChatGPT 出来。
我们先看一下 ChatGPT 的基本流程图,如图 4-31 所示。
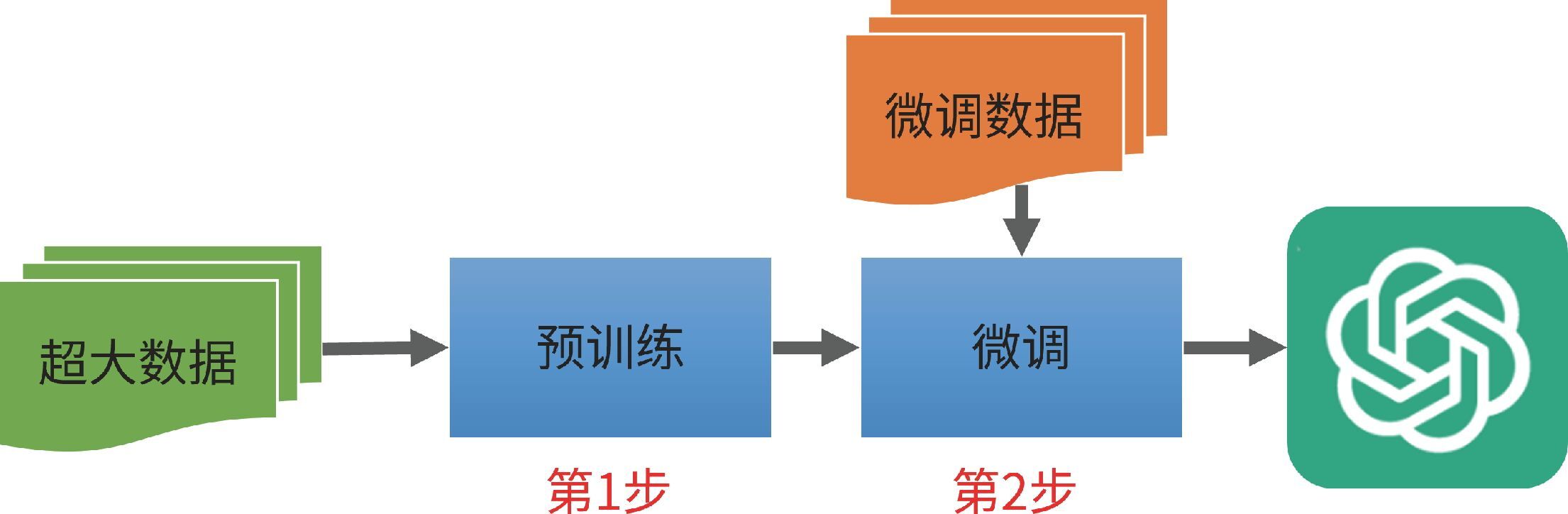
图 4-31 ChatGPT 的基本流程图
ChatGPT 的训练内容来自 45 TB 的数据集,这些数据来自书籍、论文、论坛、网络爬虫抓取的网页等。这里的论坛数据值得一提,ChatGPT 重点采用了来自 Reddit 热门论坛的帖子,它们是非常重要的学习材料。这是因为,很多词几乎只在论坛中出现,如果没有这些数据,神经网络根本学不会很多口语。论坛上的讨论更接近日常对话,具有较强的口语风格,这对于训练一个与人聊天的 AI 模型非常有帮助。
我们来问问 ChatGPT 知道 Reddit 论坛上有哪些网络流行语,如图 4-32 所示。

图 4-32 ChatGPT 所了解的 Reddit 流行语
首先,需要把这 45 TB 的数据集清洗一下。网上的垃圾内容太多了,尤其是网页数据,远远没有书籍、论文、杂志的质量高,需要去掉无用的导航、推荐、广告等信息,主要保留有价值的正文。张奶奶说:“这就像择菜,去掉黄的、蔫的、坏掉的叶子。”
45 TB 的原始语料经过清洗之后,数据量减少到 570 GB 左右(OpenAI 没有详细披露这些数据,但这个数应该和实际值相差不多)。经过清洗的数据都是值得学习的精华,相当于我们上学时的教材,而不是地摊文学。例如,来自 Reddit 的数据只包含获得 3 个赞的内容,因为一个赞也没有的内容肯定价值很低,甚至含有很多无意义的脏话。将这样的数据“喂”给神经网络,就会导致它学坏,毫无意义。也就是说,预训练数据的选择质量和 ChatGPT 最终的性能密切相关。
然后,我们就可以开始训练神经网络了。训练的过程就是通过 GPU(图形处理器,或称为图形处理单元,也就是显卡)把要训练的数据“喂”给模型,经过一些时间,就可以训练出神经网络模型了。
张奶奶问:“我听说训练模型就像炼丹?”
我说:“那我们来问问 ChatGPT 是否可以这样比喻吧。”ChatGPT 的回答如图 4-33 所示。

图 4-33 是否可以把神经网络模型训练比作太上老君炼丹
张奶奶继续问:“那为什么不用 CPU(中央处理器),而是用 GPU 呢?”高知奶奶果然懂得多。
那是因为 CPU 本是用来执行各种各样的综合任务的,而 GPU 更适合进行大量的矩阵计算和向量计算。图 4-34 展示了两者的区别。
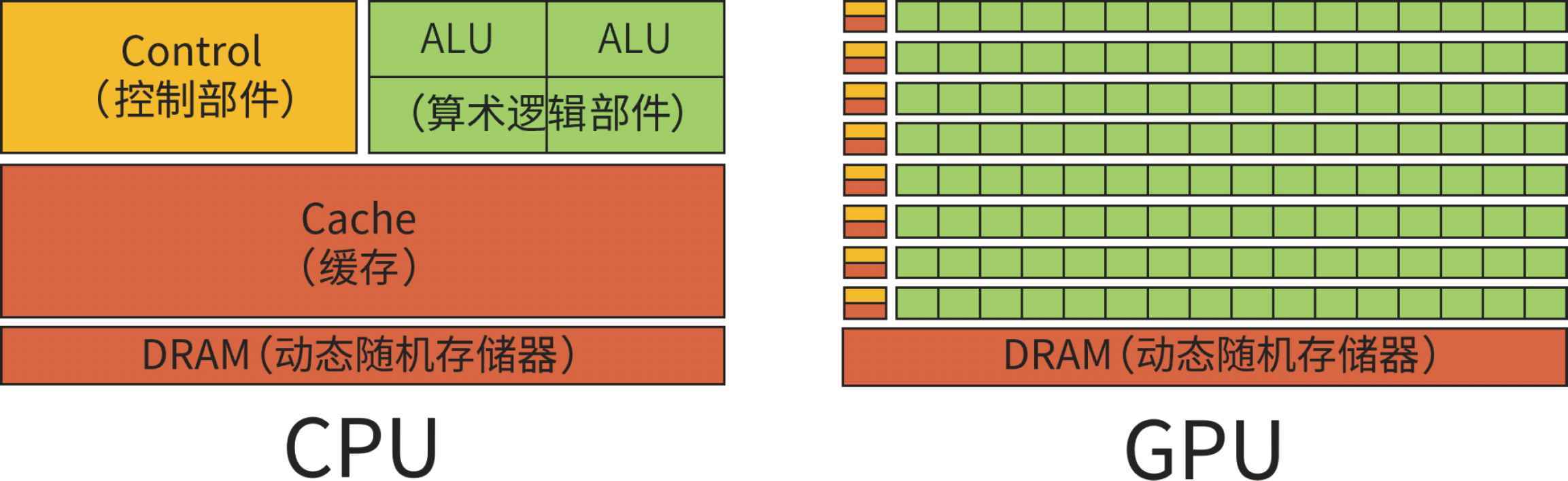
图 4-34 对比 CPU 与 GPU
张奶奶问:“那一块 GPU 相当于 100 块 CPU 吗?”
我说:“差不多吧。一块 GPU 可能有 10 000 个核心,而 CPU 一般最多只有几十个。”
张奶奶点点头说:“那我有点懂了,我可以拿孙子的 3090 显卡来进行训练。”
我回应道:“对,如果是小模型,确实可以通过 1 万多元人民币的 3090 显卡来训练。但是如果要训练 ChatGPT,那就需要 1 万多美元的英伟达 A100 显卡了,而且还需要上千块。实际上,ChatGPT 用了 1 万块 A100 显卡。”
张奶奶说:“不管怎样,我知道怎样进行预训练了。那训练到什么时候结束呢?”
我答道:“好问题。这就跟人的学习类似,当学习的效果开始下降时,就可以随时停止了。例如,一个人学《红楼梦》,学 100 遍肯定比学 10 遍得到的知识内容多很多倍,但是学 200 遍的提升效果相对于学 100 遍的提升效果而言,就没有那么明显了。”
经过预训练的模型叫作“基础模型”,它是所有后续微调工作的基础。基础模型已经像是一个具有无限潜力的超人,拥有丰富的知识。只是目前这个超人空有蛮力且善恶不分。
接下来就需要进行第 2 步,即微调。我们需要精细调整,这有些类似于给一部已经可以正常使用的空白智能手机增加一些详细的设置。
对 ChatGPT 的微调,实际上就是增加更多的对话数据集、程序代码等,以便使其更贴近聊天场景并且在回答时遵循道德规范和安全原则。例如,基础模型不仅知道怎样制作面包,还知道怎样制造原子弹;它不仅可以安慰人,还知道无数与种族歧视有关的笑话。此外,微调过程还可以帮助模型更好地理解对话场景,提供更有针对性的回答,并适应用户的需求,例如控制回答的长度等。
我给张奶奶展示了两张图,如图 4-35 和图 4-36 所示。

图 4-35 艺术画:尚未微调的基础模型(图片来源:Qiao)

图 4-36 艺术画:基础模型接受微调(图片来源:小不点)
张奶奶说:“看到这两张图,我好像懂了。微调是有点儿类似于用面团做馒头和花卷吗?”
这个比喻很有趣,我们一起来问问 ChatGPT,如图 4-37 所示。
张奶奶很开心:“通过这个比喻,我更懂了!使用 ChatGPT 真的能帮助我学习和理解。ChatGPT 这个名字,也可以用来解释‘微调’这最后一步。在 GPT 基础模型上,加入 Chat 数据集,进行对话效果提升。Chat + GPT = ChatGPT。这样一来,GPT 就不只是以续写的方式,而是以对话方式和我们聊天了,也就成为真正的 ChatGPT 了。”

图 4-37 ChatGPT 如何看待张奶奶的比喻
我鼓励道:“非常正确,您说得真的太棒了!”微调的过程也被称为 AI 对齐,就是让 AI 对齐人类的聊天习惯、对齐人类的聊天需求、对齐人类的道德观。从微软在 2023 年 3 月 22 日发布的研究报告《通用人工智能的火花:GPT-4 的早期实验》来看,在 AI 对齐前的 GPT-4 威力巨大,拥有高超的情感操纵能力,在微调之后对外发布的线上 GPT-4 版 ChatGPT 则越来越乖巧、越来越平和,很多能力因为不符合 AI 对齐标准而被封印了。这就像是我们需要一个超级英雄,但是我们肯定不希望他是绿巨人那样失控的超级英雄,我们需要懂文明、讲礼貌的物理学家罗伯特·布鲁斯·班纳博士(在漫威漫画中,绿巨人是班纳博士失控时的状态)。
我们通过例子来看一下预训练和微调的细微区别,如图 4-38 所示。

图 4-38 在本例中,ChatGPT 只进行了续写
提问的人说,“今天天气真不错”。ChatGPT 只进行了续写,而没有进行回答。这是 ChatGPT 初期版本中的一个 bug,说明这个版本保留着 GPT 的“前世记忆”。这也说明,没有彻底微调好的 ChatGPT 有时候会续写,而不太会对话。再来看看新版本 ChatGPT 的效果,如图 4-39 所示。

图 4-39 在本例中,ChatGPT 不再续写,而是对话
张奶奶高兴地说:“看来我的理解更深刻了,我有信心去申请一个人工智能博士学位读一读了!”
到此时为止,我们已经教给在路边买煎饼馃子的张奶奶“手搓”一个 ChatGPT 的大致方法了。
张奶奶问了最后一个问题:“为什么你开头的自回归函数只预测下一个字,进行文字接龙,居然就实现了人类的理解和推理智能了呢?”
我最后回答道:“奶奶,您可太会问问题了。这个问题是最难解答的,也是 ChatGPT 实现通用人工智能突破最核心的谜题。仅仅学习 3000 亿词的语料,然后对问题预测下一个字,居然就实现了人类智能,这就叫从概率预测的文字接龙到智能涌现。智能涌现最主要的条件就是数据规模要大,数据质量要好,神经网络参数够多,至少百亿级,算法要够好。至于为什么会有智能涌现,这个问题太难了,目前还没有一个完美的答案。”
至此,我和张奶奶的对话终于结束了。
OpenAI 的模型最初是开源的,随着模型的复杂度和能力的增长,到了 GPT-3 就转为闭源了。因此,对于很多技术细节的实现,外界只能猜测。2023 年 3 月 14 日,OpenAI 发布了基于 GPT-4 模型的新版本,我们甚至找不到相关的论文,只能找到一份技术报告。该报告没有描述太多的原理和细节,主要就是炫技,展示一下自己的效果多么惊艳。正所谓彪悍的人生不需要解释,目前的神经网络是一个黑盒,也不需要解释,因为即便是 OpenAI 也很难解释其内部原理。然而不可否认,GPT-4 版 ChatGPT 的效果是真好。
1776 年,瓦特成功将第一台蒸汽机投入商用,开启了机械革命,但解释其能量原理的热力学第一定律在 1842 年才被提出来,热力学第二定律在 1850 年被提出,热力学第三定律在 1912 年被提出。然而,比热力学这三条定律更基础的热力学第零定律在 1939 年才被提出。人工智能和湍流一样复杂,真正解开其中的全部奥秘可能需要一个世纪的时间。

无题 作者:贞璇 Mu
精选留言
2024-01-14 10:50:11