ChatGPT 本质上是一种生成语言输出的系统,其输出遵循来自互联网和书籍等的训练材料中的“模式”。令人惊奇的是,输出的类人特征不仅体现在小范围内,而且在整个文章中都很明显。它可以表达连贯的内容,通常以有趣和出人意料的方式包含它所学的概念。产生的内容始终是“在统计学上合理”的,至少是在语言层面上合理的。尽管它的表现非常出色,但这并不意味着它自信给出的所有事实和计算都一定是正确的。
下面是我刚刚注意到的一个例子(ChatGPT 具有内在的随机性,因此如果你尝试问相同的问题,可能会得到不同的答案)。
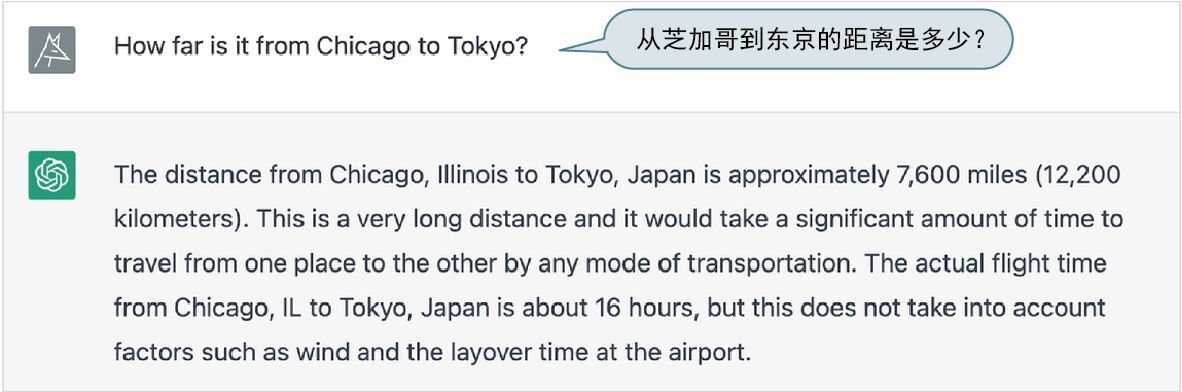
听起来相当有说服力。但是事实证明它是错误的,因为 Wolfram|Alpha 可以告诉我们如下答案。
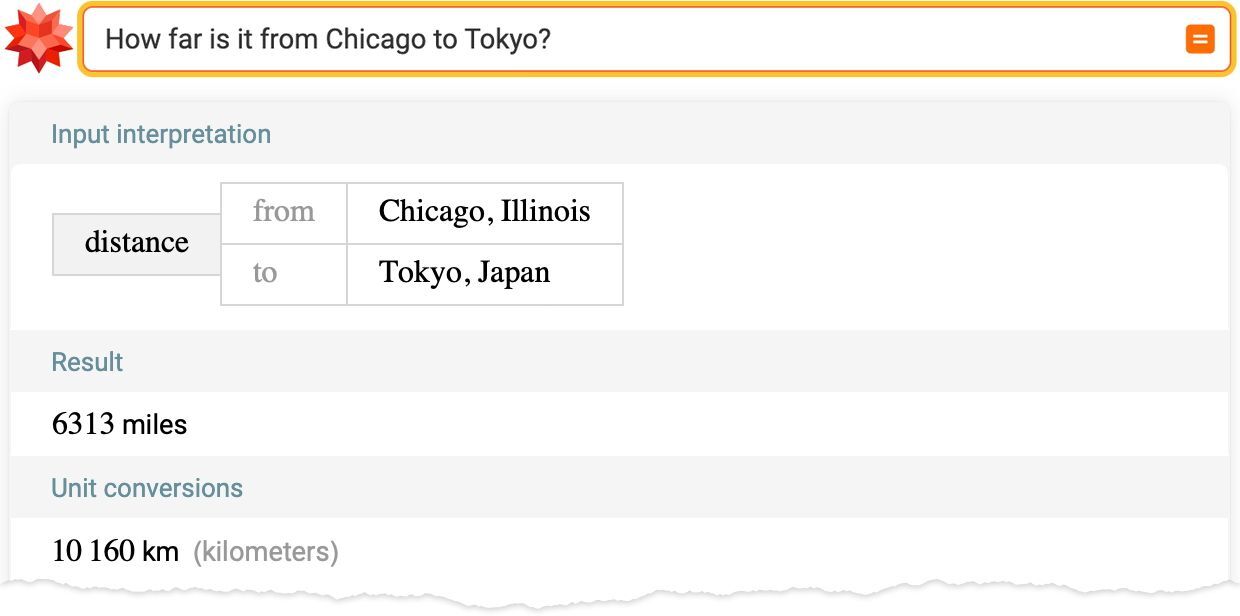
当然,这显得不太公平,因为这个问题正是 Wolfram|Alpha 擅长的问题类型:可以基于其结构化、有条理的知识进行精确计算。
有趣之处是,我们可以想象让 Wolfram|Alpha 自动帮助 ChatGPT。可以通过编程向 Wolfram|Alpha 提问(也可以使用 Web API 等)。

现在再次向 ChatGPT 提问,并附上此结果。

ChatGPT 非常礼貌地接受了更正。如果你再次提出该问题,它会给出正确的答案。显然,可以用一种更精简的方式处理与 Wolfram|Alpha 的交流,但是看到这种非常简单的纯自然语言方法已经基本奏效也很令人高兴。
不过,为什么 ChatGPT 一开始会犯这个错误呢?如果它在训练时从某个地方(例如互联网上)看到了芝加哥和东京之间的具体距离,它当然可以答对。但在本例中,仅仅依靠神经网络能轻松完成的泛化(例如对于许多城市之间距离的许多示例的泛化)并不够,还需要一个实际的计算算法。
Wolfram|Alpha 的处理方式则截然不同。它接受自然语言,然后(假设可能的话)将其转换为精确的计算语言(即 Wolfram 语言),在本例中如下所示。

城市的坐标和计算距离的算法是 Wolfram 语言内置的计算知识的一部分。是的,Wolfram 语言拥有大量内置的计算知识—这是我们几十年的工作成果,我们精心梳理了不断更新的海量数据,实现(而且经常发明)了各种方法、模型和算法—并且系统地为一切构建了一整套连贯的计算语言。
精选留言