上文提到的例子涉及为数值数据建立模型,这些数据基本上来自简单的物理学—几个世纪以来,我们已经知道可以用一些“简单的数学工具”为其建模。但是对于 ChatGPT,我们需要为人脑产生的人类语言文本建立模型。而对于这样的东西,我们(至少目前)还没有“简单的数学”可用。那么它的模型可能是什么样的呢?
在讨论语言之前,让我们谈谈另一个类人任务:图像识别。一个简单的例子是包含数字的图像(这是机器学习中的一个经典例子)。

我们可以做的一件事是获取每个数字的大量样本图像。

要确定输入的图像是否对应于特定的数字,可以逐像素地将其与已有的样本进行比较。但是作为人类,我们似乎肯定做得更好:因为即使数字是手写的,有各种涂抹和扭曲,我们也仍然能够识别它们。
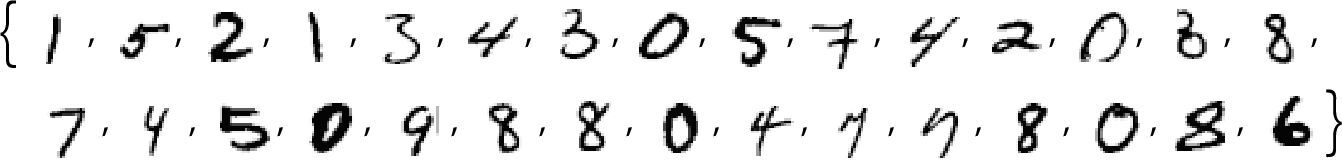
当为上一节中的数值数据建立模型时,我们能够在取得给定的数值 x 之后,针对特定的 a 和 b 来计算出 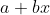 。那么,如果我们将图像中每个像素的灰度值视为变量
。那么,如果我们将图像中每个像素的灰度值视为变量 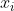 ,是否存在涉及所有这些变量的某个函数,能(在运算后)告诉我们图像中是什么数字?事实证明,构建这样的函数是可能的。不过难度也在意料之中,一个典型的例子可能涉及大约 50 万次数学运算。
,是否存在涉及所有这些变量的某个函数,能(在运算后)告诉我们图像中是什么数字?事实证明,构建这样的函数是可能的。不过难度也在意料之中,一个典型的例子可能涉及大约 50 万次数学运算。
最终的结果是,如果我们将一个图像的像素值集合输入这个函数,那么输出将是一个数,明确指出该图像中是什么数字。稍后,我们将讨论如何构建这样的函数,并了解神经网络的思想。但现在,让我们先将这个函数视为黑盒,输入手写数字的图像(作为像素值的数组),然后得到它们所对应的数字。
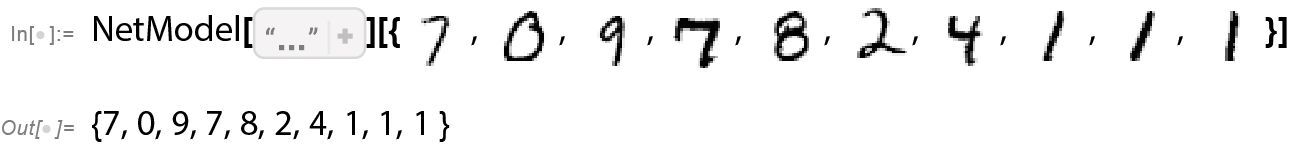
这里究竟发生了什么?假设我们逐渐模糊一个数字。在一小段时间内,我们的函数仍然能够“识别”它,这里为 2。但函数很快就无法准确识别了,开始给出“错误”的结果。
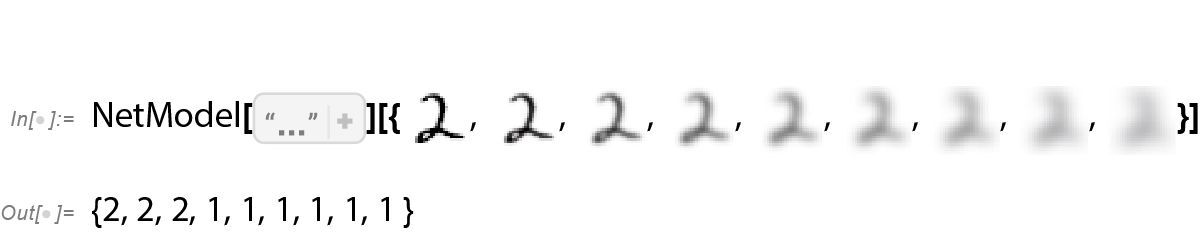
为什么说这是“错误”的结果呢?在本例中,我们知道是通过模糊数字 2 来得到所有图像的。但是,如果我们的目标是为人类在识别图像方面的能力生成一个模型,真正需要问的问题是:面对一个模糊的图像,并且不知道其来源,人类会用什么方式来识别它?
如果函数给出的结果总是与人类的意见相符,那么我们就有了一个“好模型”。一个重大的科学事实是,对于图像识别这样的任务,我们现在基本上已经知道如何构建不错的函数了。
能“用数学证明”这些函数有效吗?不能。因为要做到这一点,我们必须拥有一个关于人类所做的事情的数学理论。如果改变 2 的图像中的一些像素,我们可能会觉得,仍应该认为这是数字 2。但是随着更多像素发生改变,我们又应该能坚持多久呢?这是一个关于人类视觉感知的问题。没错,对于蜜蜂或章鱼的图像,答案无疑会有所不同,而对于虚构的外星人的图像,答案则可能会完全不同。
精选留言
2024-01-30 08:57:55