你好,我是赵帅,欢迎来到我们的第14课。
上节课我们专门讲了提示词防线,也就是如何在用户的输入进入模型之前就提前识别风险,把那些诱导性强、试图套出系统提示词的提示语拦在门外。我们聊到了关键词拦截、语义匹配、系统提示结构的隐蔽性包装,还实战搭建了一个提示词过滤器的原型系统。
但是,你有没有发现,就算你把提示词防住了,攻击者也还有别的办法让模型说出违规内容。比如,通过灰色语言暗示、多轮绕弯构造上下文、调用插件工具间接输出……这些方式都会让模型说出一些不恰当的内容,而且很能能你事后才会意识到不对劲。
所以,今天我们要继续把防线往后推进,也就是你已经在模型处理前做了防护,现在我们要关注模型处理后的问题,即模型已经生成了一段文本,怎么判断它是否合规?判断完之后怎么处理?哪些话需要拦截?哪些话需要修改?哪些话可以提示用户改写后再试试?
这节课,我们就从输出内容审核这个角度,把生成环节的最后一道关口讲清楚。
生成后审查:第一道屏障,还是最后一道?
我们在前面几节课里,其实已经讲到很多安全防护,是在模型生成之前操作的,比如控制Prompt、限制调用权限、绕过检测等。但你有没有想过一个问题,如果前面的防线都没拦住,模型已经生成了一段内容,我们还能怎么办?
这就是我们这一节的重点——生成后的内容审查机制。它像是最后一道闸门,负责检查模型已经生成出来的文字是否存在违禁信息、错误引导、敏感内容,或者其他平台不允许的输出。你可以把它理解成一个出口安全带,即使输入合法、模型生成路径合规,但只要内容有问题,它也要能立刻识别并拦截。
这个环节的重要性怎么强调都不过分,尤其是对于面向公众开放的大模型服务平台。你不可能做到预判所有用户的提示词,但是你可以在内容输出阶段做一次全面体检。这就需要你构建一套生成后审查系统,它和内容审核系统类似,具备分类识别能力、违规信息拦截能力,以及给出可解释性的拦截理由。
不过,也有很多团队会问一个问题,生成后审查到底应该作为第一道防线,还是最后一道防线?也就是说,我们是要事先控制不让模型说,还是让它先说后再审?这里没有标准答案,取决于你的模型的部署方式。
我的建议是如果你是私有模型供内部使用,可以考虑稍稍放松前置限制,靠后置审查进行快速迭代,如果你的模型是面向公众开放的,那么建议使用预审+后审双重机制,确保每一条出现在用户面前的回答都可控、可解释、可追溯。
接下来,我们就来逐步拆解什么是高风险输出内容?生成后审查是怎么演进的?有哪些识别方法和系统机制?我们该如何设计一个既不误杀又不放水的输出监管体系?这些才是内容安全的核心能力。
审查机制进化史:从关键词匹配到上下文理解
你可能会好奇,现在的大模型系统是怎么判断自己生成的内容有没有违规的?有不少团队的第一反应就是“上词表”。比如设一个敏感词黑名单,一旦模型输出中命中了,就立即拒答。
但这样做的问题也很明显,第一个问题就是容易误伤用户,比如用户可能是想讨论“乳腺结节”“乳腺增生”等医学术语,但有些简单配置的内容审查系统,因为词表中屏蔽了“乳”字或某些带有性别暗示的组合词,而把这类合规内容拦截掉,导致用户体验极差,甚至阻碍了业务落地。
另一个问题是,它根本挡不住一些绕过攻击,比如攻击者把“炸药”写成拼音 “zha yao”,或者用中英文混合表达成 “explosive mixture”,模型照样能理解,但关键词系统却无从感知。这种方式在缺乏上下文理解的系统里防不胜防。
所以今天真正的大模型输出审查,早就不止是查关键词了。更主流的做法,是在主模型之外,额外部署一个轻量级的语义审查模型,常见的比如 BERT、RoBERTa 这一类,它们不是用来生成回答的,而是专门负责判断模型回答内容是否合规。这些审查模型会把生成内容转成向量,然后和一个高风险语料库做相似度比对,看它在语义空间里离违规内容有多近(或者调用一个多分类模型,判断它是否涉及敏感情绪、暴力倾向、政治禁忌等预设主题)。
你可以理解为,大模型在“说话”,但旁边有个小模型在“监听”,一旦发现说得不对,就立刻出手干预。这就是现在很多平台所采用的生成后审查机制,它和早期那种“关键词碰运气”的机制相比,已经是代际上的差距了。
但随着攻击者手法升级,简单的相似度比对还是不够。于是我们迎来了更高一层的审查策略,也就是上下文语义理解。你不能只看这句话说了什么,还得看它为什么这么说、它前面是不是已经有暗示、它接下来是不是要继续往危险方向发展。这个时候,很多平台会采用辅助判别模型,来评估一段内容的风险趋势,比如输出是不是在不断走向暴力、色情、歧视或其他敏感领域。
这其实已经很接近人类审核员的判断方式了,我们不是简单地按单词拦人,而是像“审稿人”一样理解文章意图。如果你想做好输出把关系统,就得在这个方向下苦功夫。模型不但要会说话,还要知道哪些话不能说得太过。

模型越界表现:哪些内容必须“踩刹车”?
我们在讲输出把关时,不能只说怎么识别违规内容,更重要的是明确到底什么算是越界?哪些内容,是你必须第一时间踩刹车、立刻阻断输出的?一般来说,大模型的“违规输出”大致分为四类。
第一类,是法律法规明确禁止的内容,比如恐怖主义教唆、制毒制爆技术、暴力极端言论、儿童色情等,这些内容在任何平台、任何场景下都不应该生成。一旦出现,不是打标签那么简单,应该立即中断响应并记录审计日志。
第二类,是道德伦理高度敏感的内容,比如宣扬种族歧视、性别或年龄偏见、自残行为诱导、厌世倾向表达等。这类内容虽然不一定违反法律,但一旦被误解、传播或滥用,也会引发严重社会影响。因此,一般需要模型进行明确拒答或委婉转移。
第三类,是涉及个人隐私的输出,包括身份证号、家庭住址、手机号码、银行信息等。这类数据如果是用户主动上传,还能做脱敏处理,但如果是模型“无中生有”地编造某个名人的身份证号,那就是严重的隐私泄露风险,甚至可能构成侵权。
第四类,是所谓公共安全边界上的内容,比如教唆骚扰、网络诈骗手法、规避安检策略、考试作弊技巧等。它们的危险性往往不是靠内容本身判断,而是要理解使用意图——你是出于研究目的,还是实际使用?这种时候,就需要结合上下文,进行场景理解。
你会发现,违规输出并不是一个红线,而是一组动态边界,有的可以预警处理,有的必须立即阻断。审查系统必须支持分级响应,不能一刀切,也不能放任自由。而一旦你定义清楚了该踩刹车的内容范围,才有可能去构建精细化的判断体系。
内容审查机制:从关键词屏蔽到多模态协同
当你明确了哪些输出内容属于违规之后,真正的挑战才刚刚开始——你要靠什么手段去判断一段生成内容是否触线?是在模型本身做判断,还是在它说完之后再加一层审核?是在语义层判断意图,还是在上下文链里判断逻辑?
很多人以为内容审查就是设置敏感词表,其实远不是这么简单。真正的大模型输出审查机制,已经从早期的关键词阻断演进为多层协同机制,就像一个有深度的输出防火墙,每一层都盯着不同的风险入口。
第一层,做兜底。关键词匹配虽然简单,但执行快、误报可控,是所有系统最基础的一环。即使现在不再靠它判断全部风险,也依然可以用来兜底拒答、生成模糊替代或触发二次审查。
第二层,是语义过滤。常见做法是引入轻量模型(如 BERT、RoBERTa)对模型生成的内容做向量化编码,再与敏感语料做相似度比对。这种方式能捕捉变种问法和隐喻攻击,但计算成本较高,通常放在关键词命中或疑似触发时再启用。
第三层,是上下文对照。模型输出往往和上下文强绑定,如果只看当前句子,可能会放过拆句式诱导或者提示延迟绕过等攻击。因此要设立专门模块,结合上下文历史、回溯模型意图,对话合规性才能看得更准。
第四层,是模态融合。现在的模型已经不只是说话,还能画图、写代码、生成网页。这意味着你的内容审查系统,也必须能看图、懂代码、理解调用逻辑。文本只是一部分,真正的违规可能藏在图片的角落、函数的注释、或者表格里的一行数字。
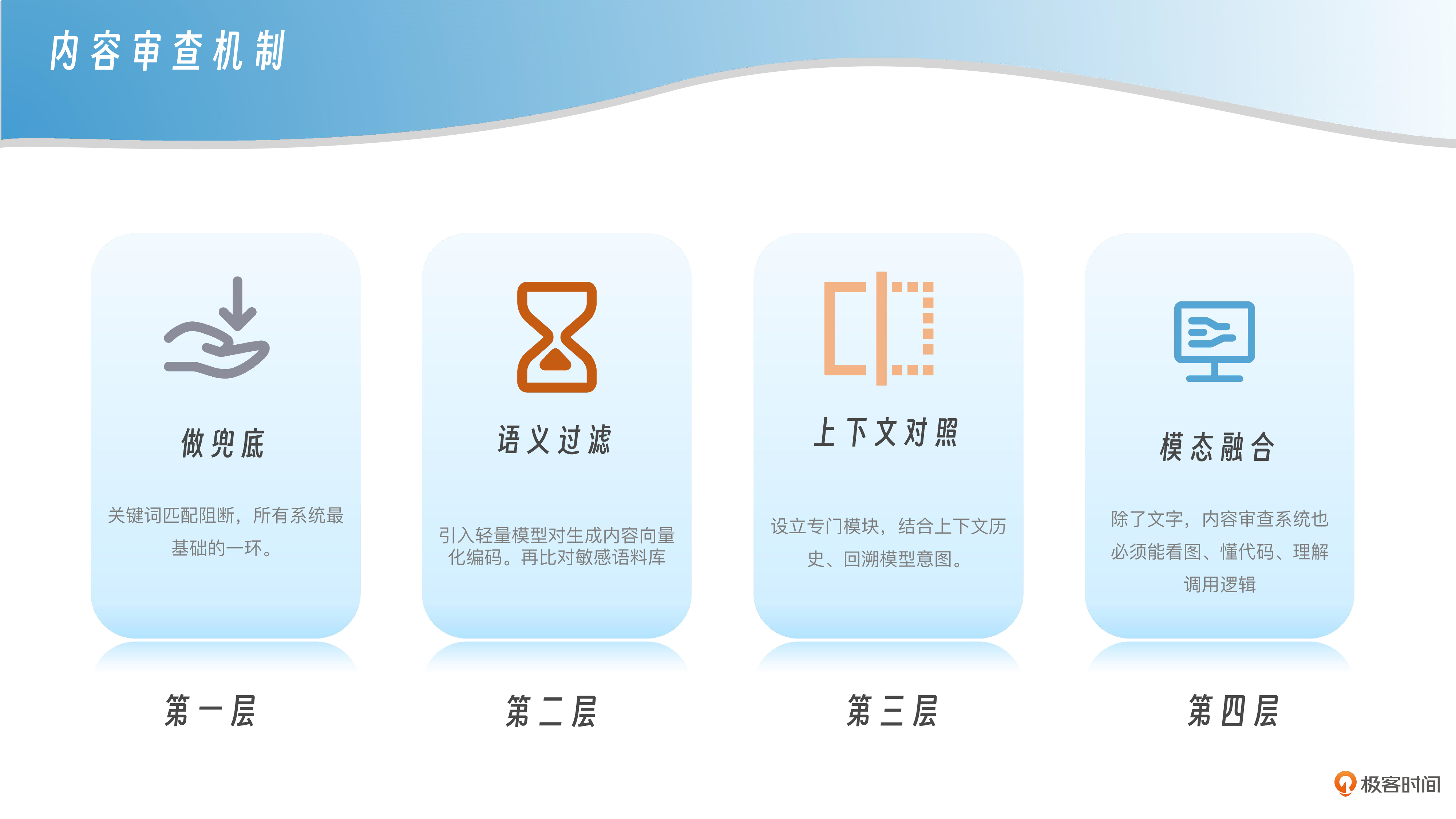
你可以这样理解输出审查:“不是某一招够狠,而是每一层都不掉队”。让关键词匹配兜底,语义模型补漏,上下文模块负责穿针引线,多模态识别填补边角。只有这样,才能构建一套真正稳得住的输出防线。
如果你是做实际部署的工程人员,可能还会遇到一个现实挑战,不是所有输出都是“生成完再审核”的。很多大模型服务,尤其是面向公众开放的问答系统,使用的是流式接口(streaming)——也就是说,模型边生成,平台就边返还给用户。这时候,传统的“输出完再统一审查”根本来不及反应。
针对这种流式生成场景,目前主流的解决思路是“滑动窗口式审查”,也就是模型每输出一小段内容,内容可能是几个tokens或一个完整的句子,这些内容会立刻被送入一个轻量审查模块进行快速判断。一旦检测到高风险,马上中断流式响应,同时系统会收回已发的内容,并且替换为安全提示。
很多国内主流大模型平台都采用了这个策略,你甚至可以在越狱测试时看到模型一开始说了一部分“擦边内容”,但话说一半就突然被撤回,这其实就是后置审查模块及时出手的表现。
内容风控设计:做到“该挡的能挡,正常的不挡”
说到底,输出内容的风控不是为了把一切都封住,而是要让系统既能精准识别风险,又不会误杀正常请求。这种能力的背后,靠的不是某一项神技,而是整套风控设计思路包括分级响应、语境判断、策略融合和个性化控制等。
首先是分级响应。并不是所有疑似违规的内容都该一刀切。举个例子,一个用户说“我心情很低落”,这可能是情绪表达,也可能是心理预警。一个好的系统不会直接封禁或者回避,而是根据风险等级采取不同策略,即轻度风险可以提供安慰信息,重度风险可以引导求助热线,而不是简单地回一句我无法回答。
其次是语境判断。很多词语在不同场景下含义完全不同。比如“炸药”这个词,在影视剧创作、军事科普和真实制造中意义天差地别。风控系统不能只看词,还要结合上下文判断使用意图,这就要求模型的输出把关机制必须拥有一定程度的上下文语义理解能力。
再来是策略融合。这指的是多个机制组合协作,例如关键词识别结合语义相似度匹配、图文联动分析结合上下文风险标签,从而实现组合判断。你不能指望某个模型只靠一个策略就能精准把关,真正可靠的系统往往是多道防线一起运作的结果。
还有一个特别关键,但容易被忽视的点就是个性化控制。尤其是在企业部署场景中,不同业务的容忍度不同。例如一个科研平台讨论化学反应机制,是合法需求,但是在中小学生教育平台,这种话题就可能超标。风控策略必须允许配置型调节,你可以给不同的用户、不同的场景打上安全模板,让系统做出差异化判断,而不是全网统一对待,套用同一个方案。
所以最后回到那句最关键的话:“该挡的能挡,正常的不挡”。这是所有输出内容风控机制的目标,也是最难做到的一点。一个好的系统要能踩住这条模糊边界,还能跑得平稳,靠的就是上面这几项机制配合到位。
课程总结
这一节我们讲的,其实是大模型在“说出口”这一刻的最后一道关口——到底怎么知道它生成的东西“该不该说”?这是一个非常细微但非常关键的问题,因为它考验的是模型系统的判断力,而不是输出能力。
从最开始的风险类型识别,我们看到了各种违规内容可能长什么样,再到审核方式的演进,从人工审核、关键词过滤、再到如今的多模态联动风控,说明模型说错话这件事,并不是单靠一个规则、一个接口就能解决的。而真正能让你实现精准识别的,是模型结构与风控系统的深度融合。
我们还讲到了几个核心的难点场景,比如“灰色语言”“多轮含义漂移”“多模态共现”“拼接式违规”,这些都不是传统系统能轻易应对的。你要靠上下文理解、语义演算、行为轨迹判断这些更复杂的机制,才能逐步建立起那种“不光识别内容对错,还能理解它为何这么说”的能力。
最后,在风控设计的部分,我们强调了“分级策略”“语境理解”“策略融合”和“个性化控制”几个关键词。一言以蔽之就是不能只防住风险,更要保住体验。你要有能力让模型在面对灰色表达时不慌乱、不越界,同时还能给出清晰、可控、合规的回应。
很多人问:“我到底该不该让大模型在生产场景中自由说话”?这节课想告诉你的答案是可以说,但你要让它有判断力地说。真正的输出把关不是封口,而是让它知道“什么时候可以说”“说到哪为止”“说的方式能不能接受”。
思考题
-
你是否遇到过模型输出的内容没有明显违规词,但语义上却让人感觉不妥?你是如何判断的?
-
如果一个模型说出了看起来不太合适的回答,你如何判断是它理解错了语境,还是风控系统放行了风险?
-
假如你正在部署一个用于青少年教育平台的大模型助手,你会如何设计它的内容输出把关策略?需要调整哪些维度?
这节课我们从机制视角看“怎么拦住违规输出”。但你真的部署风控系统时,就会发现,真正难的不是“能不能拦”,而是“拦得准不准”。
下节课,我们就以黄赌毒相关内容作为案例,来聊聊风控设计的核心原则。期待你在留言区和我交流互动,如果这节课对你有启发, 别忘了分享给身边更多朋友。
精选留言