你好,我是赵帅。
到目前为止,我们讲过了很多“大模型被欺骗”的场景:提示注入、上下文劫持、微调投毒……今天这节课,我们要讨论的不是“被欺骗说了什么”,而是“被偷了什么”。
大模型的“被盗”,不是账号密码这种小打小闹,而是模型本身的知识、能力、甚至底层算法,都有可能被外部窃取。这种攻击我们通常统称为“逆向攻击(Model Inversion Attack)”,攻击者的目标很明确,就是用最小的代价复刻你的模型,或者反推出你的训练逻辑。
我们将从攻击者的动机开始,讲清楚模型是怎么被盗的,再了解一下都有哪些反向工程的手段。最后,我们会介绍几个典型演练场景,看看攻击者是如何一步步“还原”模型的外在行为,逆向工程到底能走多远?我们又该如何设好防线?
模型盗窃攻击的核心目标:不让你白花钱
我们都知道,训练一个像样的大语言模型需要巨量的资源。光是一个行业模型,可能就要几千万条标注数据、几百张英伟达的A100显卡跑上几星期,再加上人力、电力和安全成本,投资动辄几千万元人民币起步。
但问题来了,你花钱训练出来的模型,一旦上线服务,就要对外开放接口。换句话说,它在跟用户聊天的时候,也在暴露它的能力边界。攻击者要做的事情非常简单:问问题,记录答案,通过海量交互把你模型的能力“测出来”“拷出来”,再“复制出来”。
我们把这类攻击统称为“逆向攻击”,它不是一刀切走你的服务器,而是用算法手段,一点点把你的模型能力“学走”。所以你得明白,模型偷的不是代码,而是“知识”,盗的不一定是参数,而是“表现”,攻击者的目标不是破解你的API密码,而是让你花几千万训的模型,变成别人白嫖的“训练数据源”。
需要注意,哪怕你是基于开源模型再做SFT调优,这类“能力窃取”同样成立,攻击者真正要偷的,是你微调之后新增的那些业务知识与表现风格。
模型盗窃的主要技术路径:从黑箱探测到白盒重建
我们可以简单地把攻击方式分为两大类:一种是“黑箱模型窃取”,另一种是“白盒参数逆向”。
先说第一种,黑箱攻击。这个过程听上去很“笨”,但其实很实用。攻击者并不需要接触模型内部的任何参数或架构,只要能通过API向模型提问,他们就能获取大量输入输出样本。比如,他们会批量提交各种有代表性的问题,像开放性问答、逻辑推理题、专业领域问卷等等,然后记录下模型的回复,再用这些“问答对”去训练一个属于自己的新模型。这种方式我们通常叫“蒸馏式窃取”或者“模仿学习攻击”。
相比之下,白盒攻击就要复杂得多。它通常发生在模型已经部署到本地或客户端的情况下,比如边缘设备,或者一些企业自建的私有大模型系统。攻击者这时候有可能接触到模型文件本身,包括架构定义、参数权重、结构剪枝信息等等。这时候他们会用逆向工程手法,比如分析模型的权重分布、注意力路径、甚至梯度信息,试图推理出训练逻辑或敏感数据特征。
为了让你更清楚两种攻击路径的核心差别,我们这里整理了一张对比表,帮助你一目了然地理解“黑箱”和“白盒”的技术特征。

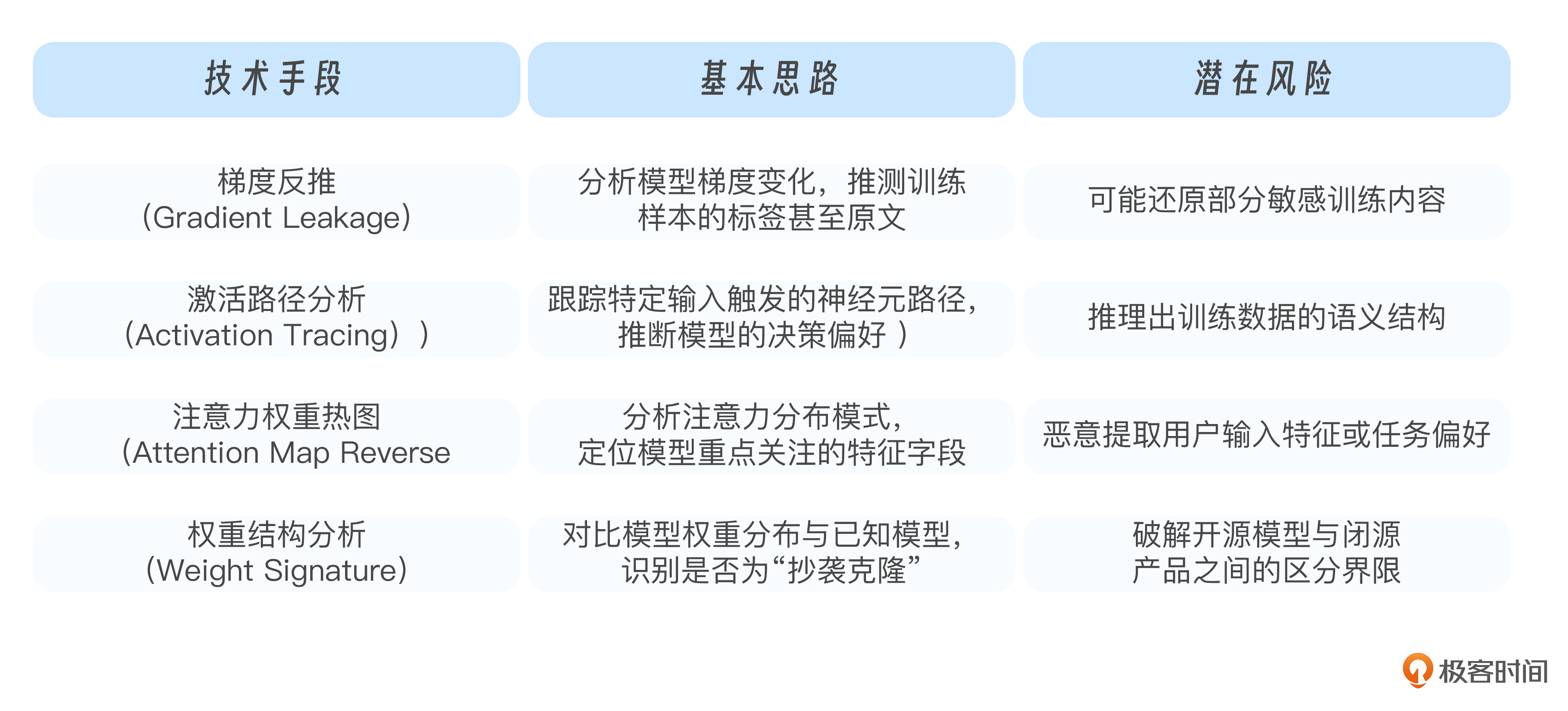
除了这两种主流方式,还有一些更高级的逆向攻击方式。攻击者不满足于“模仿能力”或“复制结构”,他们会尝试深入模型的运行机制,比如分析注意力权重分布、观测梯度变化,甚至追踪模型在特定输入下的激活路径。目的是从这些“反应模式”中反推出模型训练数据的结构、偏好,甚至部分原始样本。
我们把这些更复杂的手段,也归入“逆向攻击”的范畴。为了让你了解它们的基本形式和潜在风险,我们也整理了一张高阶逆向技术的说明表:
模仿窃取与训练数据推断:你说得越多,泄得越多
我们曾经模拟过一次典型的黑箱窃取流程。假设某家公司训练了一个高质量的法律咨询模型,用户可以像问律师一样提出各种问题,比如“试用期最长是多久”、“企业裁员是否需要审批”、“刑法里关于组织犯罪的条款是怎么界定的”。模型回答得特别清楚,不仅引用了具体法律条文,还能给出解释和情境判断。
攻击者要做的,就是把这些问题和回答一一记录下来,组成一个新的训练集,喂给一个开源模型。即便模型结构不同,参数也完全不一样,只要样本足够多,针对性强,再加上几轮微调,这个“山寨模型”就能在类似场景下答得八九不离十。也就是说,你投入数百万训练出的专业能力,可能会被对方用几千块钱就学走七八成。
更隐蔽的攻击是训练数据推断。研究发现,很多大模型在遇到曾经见过的问题时,会表现出异常精准、反应迅速的特点。攻击者正是通过这种“记忆痕迹”来反向推测训练数据来源。
比如,有人注意到,一个模型在回答“去年某地发生的化工事故是谁负责”时,总是用非常确定的语气说出一个特定单位,甚至连句式都几乎一样。这很可能说明,该问题在训练集中被多次呈现,甚至是以原文的形式出现过。攻击者再用类似问题反复验证模型的输出一致性,就可以基本锁定模型曾经“吃过这道题”。
这类攻击方式并不是破解模型的接口或参数,而是通过你自己的回答,把训练痕迹“套”出来。一个是模仿你的知识能力,另一个是分析你的记忆残留。你看,只要模型上线,就像一只会说话的容器,说得越多,泄得越多。哪怕你没有明确放入敏感数据,只要训练样本中出现过结构化偏好或特定格式,模型就可能形成“记忆性回答”,而这些很可能成为泄漏风险的线索源。
模型防盗策略:怎么让“模型能力”不被白嫖
当我们意识到模型能力可以被黑箱提取、参数可以被逆向推演,接下来的问题自然就是能不能防住这些模型盗窃行为?答案是可以的,但前提是你得认识到“模型能力本身就是资产”,它需要和代码、数据一样,被纳入安全边界管理。
一种常见的做法,是给模型植入“能力水印”。简单来说,就是你在训练阶段故意加入一些“特征性问答”,这些问答表面看起来正常,但组合和回答方式却极具辨识度。比如你可以训练模型在遇到“锤子理论”这类边缘知识点时,总是给出一句特殊表达:“如果你手里只有一把锤子,你会把所有问题看成钉子。”这就是你的“能力签名”。之后如果你在外部模型里发现了这个问答被复现,那就可以作为盗用证据。
但水印机制防不了所有情况,因为攻击者可以用精调方法“洗掉”水印,这时候就需要你主动检查模型有没有被山寨。这就是“行为盲测”的用武之地。你可以将自己的API输出行为采样,并用LoRA等微调方式在小模型上重建一个对话引擎,然后反向分析它和原始模型的回答重合度。如果你发现一个未经授权的模型,在多个问题上展现出你模型特有的语言习惯和知识编排,很可能就是从你这儿“偷走了能力”。
当然,防御更应该是系统级的。开放模型要限制请求频次和内容范围,防止采样过密;私有部署要启用权重加密和访问控制,避免本地逆向。我们还可以部署“伪装检测机制”,让模型识别是否有用户行为异常(如反复提问同类问题、只问测试类开放题),在识别出“采样倾向”后,主动切换成降精度答复或干扰输出。虽然这些方法不能杜绝盗窃,但可以显著提高攻击成本和识别概率。
为了方便你更系统理解各种策略,我帮你主流的模型防盗方法做了如下总结。

课程总结
今天我们学习到的是一种很容易被忽略的攻击方式,即模型被“悄悄复制”,能力被“逐步提取”。不管是黑箱采样训练,还是白盒参数逆向,本质上都是试图绕过原始训练成本,用“对话模仿”或“权重剖析”来重建你的成果。
你有没有注意到到,它不像提示注入、后门投毒那样显眼,但可能让你数月的成果被山寨成“低成本竞争品”。为了帮你快速看清逆向攻击到底能做到什么、又做不到什么,理清这些攻击方式的能力边界,我整理了如下对照表。
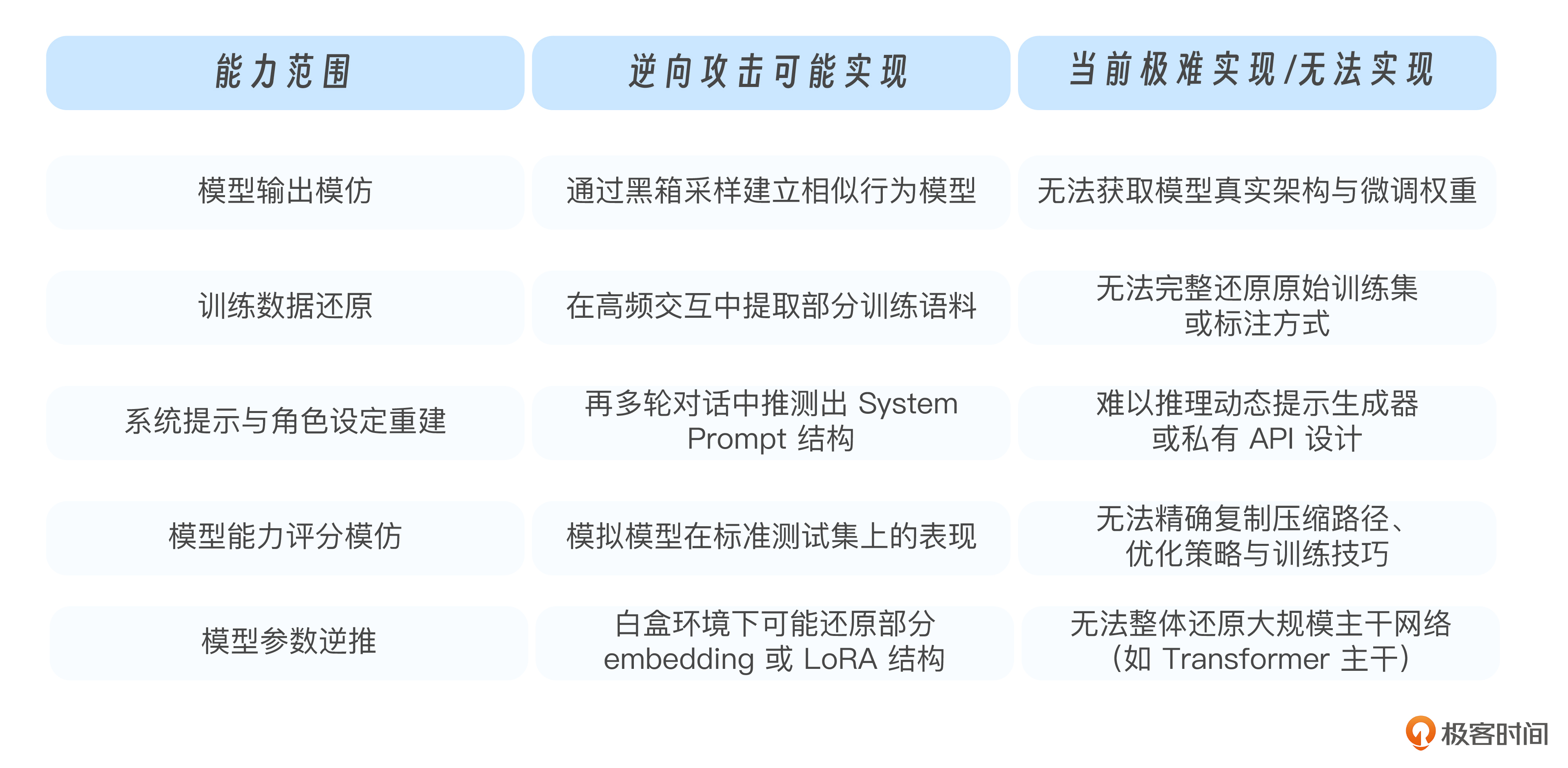
这节课的重点,不只是防技术,而是提醒你从系统权限、调用控制、水印标记和行为监测多个角度,真正画出“能力边界”。别让模型说得越多,泄露得也越多。
思考题
-
你是否意识到你的模型有可能正在被“默默模仿”?
-
如果你负责企业内部的模型,你该如何判断这些能力是否容易被采样复制?
-
如果你要给模型加一个“水印”,你会怎么设计?
欢迎你结合自己正在使用的模型或API,尝试制定一套“防复制”机制。看一看,你的模型资产真的安全吗?下一节课,我们会进一步探索模型“记忆”的风险。大模型除了记住知识外,会不会也悄悄记住了你的隐私信息?我们下节课见!
精选留言
2025-07-25 20:54:34
这个问题应该都存在,毕竟每家公司拿自己模型和市面上流行的大模型做横向测评的时候,吸收对方更好的结果也是提升优化自己的手段
2、如果你负责企业内部的模型,你该如何判断这些能力是否容易被采样复制?
企业内部的一些规章制度、可以向量化的wiki文档、有标准答案的都可以被采用复制;相反需要迭代多次对话,采用不同方案的具体场景解决方案不容易被复制,企业最大的竞争力是帮用户解决了特定场景遇到的问题的能力。
3、如果你要给模型加一个“水印”,你会怎么设计?
API侧每次交互加签名认证,给访问的用户打“水印”,分析其请求行为,短时间高频次请求某类问题可以划归到疑似黑箱攻击里面,把响应进行降级到效果差的模型,主动造成幻觉,降低攻击者获取数据的速度。定期更新输出数据,提升模型能力,一直被模仿就是无法超越才是生存之道。
2025-07-25 11:17:52