你好,我是Chrono。
在前面的两节课里,我们学习了对Pod和对集群的一些管理方法,其中的要点就是设置资源配额,让Kubernetes用户能公平合理地利用系统资源。
虽然有了这些方法,但距离我们把Pod和集群管好用好还缺少一个很重要的方面——集群的可观测性。也就是说,我们希望给集群也安装上“检查探针”,观察到集群的资源利用率和其他指标,让集群的整体运行状况对我们“透明可见”,这样才能更准确更方便地做好集群的运维工作。
但是观测集群是不能用“探针”这种简单的方式的,所以今天我就带你一起来看看Kubernetes为集群提供的两种系统级别的监控项目:Metrics Server和Prometheus,以及基于它们的水平自动伸缩对象HorizontalPodAutoscaler。
Metrics Server
如果你对Linux系统有所了解的话,也许知道有一个命令 top 能够实时显示当前系统的CPU和内存利用率,它是性能分析和调优的基本工具,非常有用。Kubernetes也提供了类似的命令,就是 kubectl top,不过默认情况下这个命令不会生效,必须要安装一个插件Metrics Server才可以。
Metrics Server是一个专门用来收集Kubernetes核心资源指标(metrics)的工具,它定时从所有节点的kubelet里采集信息,但是对集群的整体性能影响极小,每个节点只大约会占用1m的CPU和2MB的内存,所以性价比非常高。
下面的这张图来自Kubernetes官网,你可以对Metrics Server的工作方式有个大概了解:它调用kubelet的API拿到节点和Pod的指标,再把这些信息交给apiserver,这样kubectl、HPA就可以利用apiserver来读取指标了:
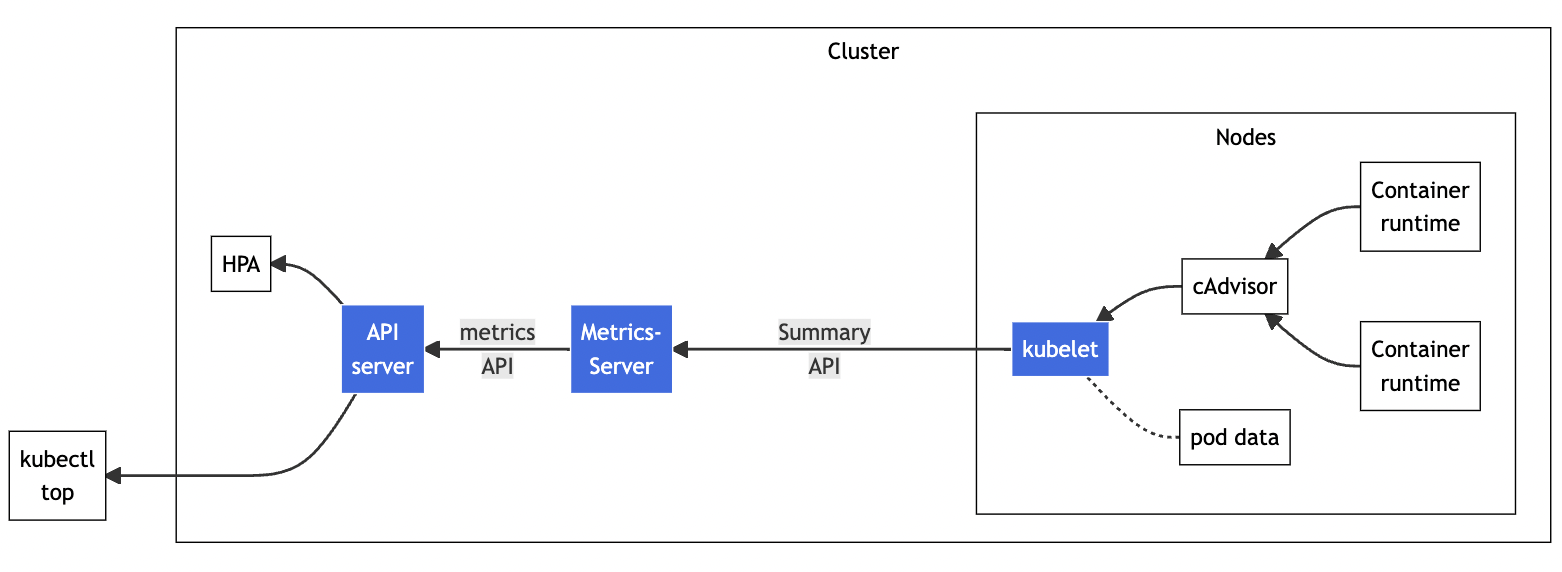
在Metrics Server的项目网址(https://github.com/kubernetes-sigs/metrics-server)可以看到它的说明文档和安装步骤,不过如果你已经按照第17讲用kubeadm搭建了Kubernetes集群,就已经具备了全部前提条件,接下来只需要几个简单的操作就可以完成安装。
Metrics Server的所有依赖都放在了一个YAML描述文件里,你可以使用wget或者curl下载:
wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
但是在 kubectl apply 创建对象之前,我们还有两个准备工作要做。
第一个工作,是修改YAML文件。你需要在Metrics Server的Deployment对象里,加上一个额外的运行参数 --kubelet-insecure-tls,也就是这样:
apiVersion: apps/v1
kind: Deployment
metadata:
name: metrics-server
namespace: kube-system
spec:
... ...
template:
spec:
containers:
- args:
- --kubelet-insecure-tls
... ...
这是因为Metrics Server默认使用TLS协议,要验证证书才能与kubelet实现安全通信,而我们的实验环境里没有这个必要,加上这个参数可以让我们的部署工作简单很多(生产环境里就要慎用)。
第二个工作,是预先下载Metrics Server的镜像。看这个YAML文件,你会发现Metrics Server的镜像仓库用的是gcr.io,下载很困难。好在它也有国内的镜像网站,你可以用第17讲里的办法,下载后再改名,然后把镜像加载到集群里的节点上。
这里我给出一段Shell脚本代码,供你参考:
repo=registry.aliyuncs.com/google_containers
name=k8s.gcr.io/metrics-server/metrics-server:v0.6.1
src_name=metrics-server:v0.6.1
docker pull $repo/$src_name
docker tag $repo/$src_name $name
docker rmi $repo/$src_name
两个准备工作都完成之后,我们就可以使用YAML部署Metrics Server了:
kubectl apply -f components.yaml
Metrics Server属于名字空间“kube-system”,可以用 kubectl get pod 加上 -n 参数查看它是否正常运行:
kubectl get pod -n kube-system
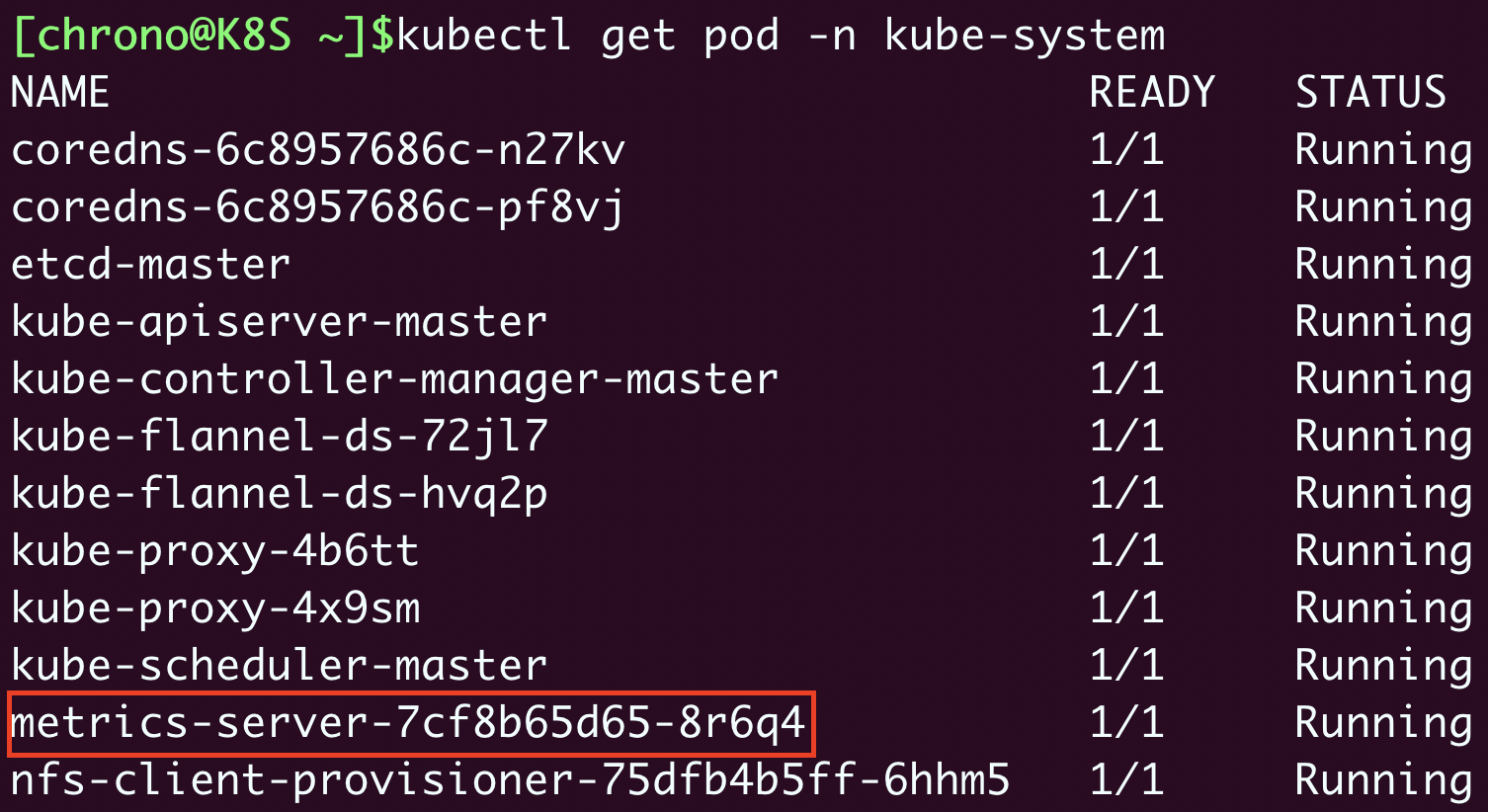
现在有了Metrics Server插件,我们就可以使用命令 kubectl top 来查看Kubernetes集群当前的资源状态了。它有两个子命令,node 查看节点的资源使用率,pod 查看Pod的资源使用率。
由于Metrics Server收集信息需要时间,我们必须等一小会儿才能执行命令,查看集群里节点和Pod状态:
kubectl top node
kubectl top pod -n kube-system
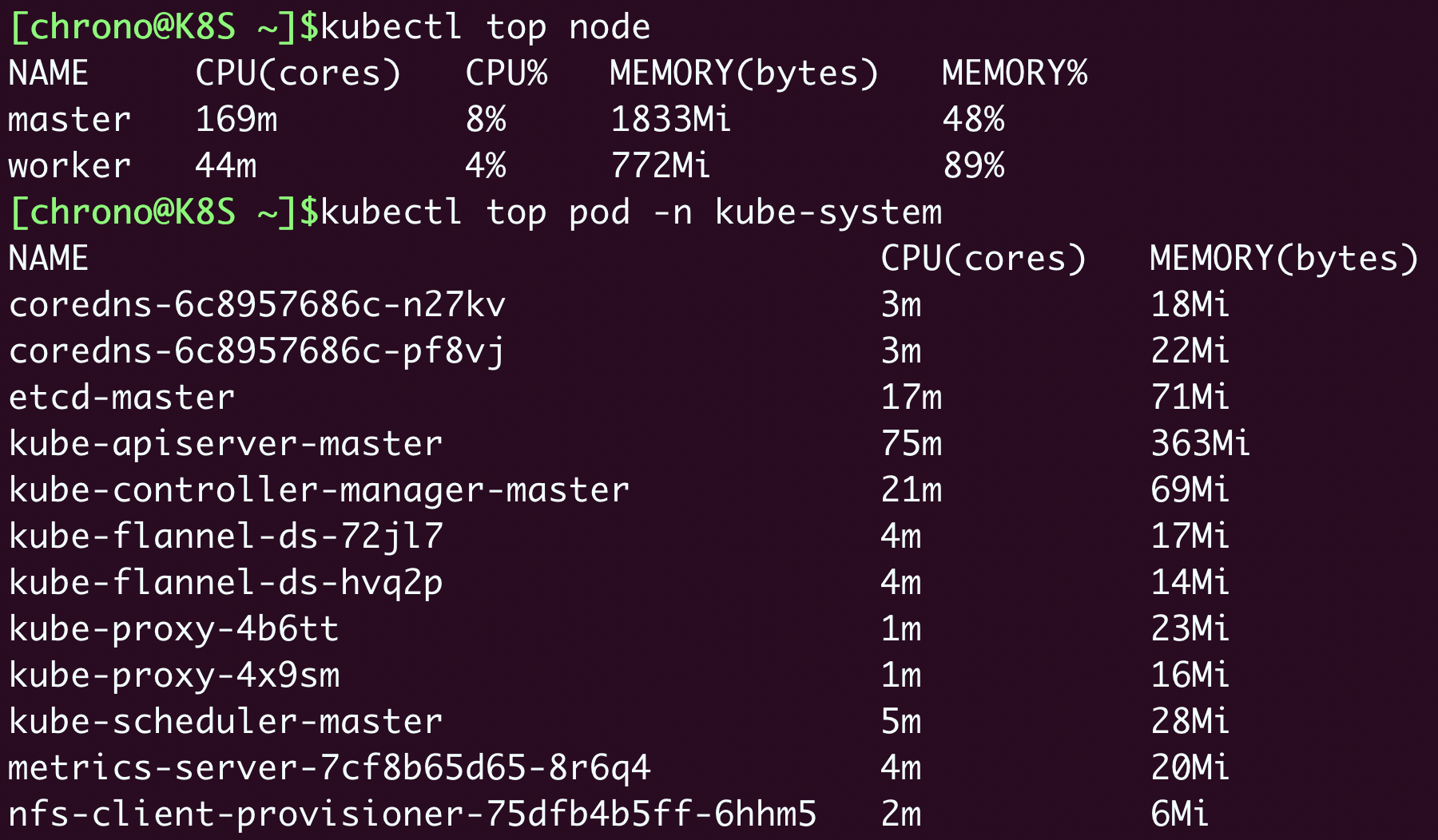
从这个截图里你可以看到:
- 集群里两个节点CPU使用率都不高,分别是8%和4%,但内存用的很多,master节点用了差不多一半(48%),而worker节点几乎用满了(89%)。
- 名字空间“kube-system”里有很多Pod,其中apiserver最消耗资源,使用了75m的CPU和363MB的内存。
HorizontalPodAutoscaler
有了Metrics Server,我们就可以轻松地查看集群的资源使用状况了,不过它另外一个更重要的功能是辅助实现应用的“水平自动伸缩”。
在第18讲里我们提到有一个命令 kubectl scale,可以任意增减Deployment部署的Pod数量,也就是水平方向的“扩容”和“缩容”。但是手动调整应用实例数量还是比较麻烦的,需要人工参与,也很难准确把握时机,难以及时应对生产环境中突发的大流量,所以最好能把这个“扩容”“缩容”也变成自动化的操作。
Kubernetes为此就定义了一个新的API对象,叫做“HorizontalPodAutoscaler”,简称是“hpa”。顾名思义,它是专门用来自动伸缩Pod数量的对象,适用于Deployment和StatefulSet,但不能用于DaemonSet(原因很明显吧)。
HorizontalPodAutoscaler的能力完全基于Metrics Server,它从Metrics Server获取当前应用的运行指标,主要是CPU使用率,再依据预定的策略增加或者减少Pod的数量。
下面我们就来看看该怎么使用HorizontalPodAutoscaler,首先要定义Deployment和Service,创建一个Nginx应用,作为自动伸缩的目标对象:
apiVersion: apps/v1
kind: Deployment
metadata:
name: ngx-hpa-dep
spec:
replicas: 1
selector:
matchLabels:
app: ngx-hpa-dep
template:
metadata:
labels:
app: ngx-hpa-dep
spec:
containers:
- image: nginx:alpine
name: nginx
ports:
- containerPort: 80
resources:
requests:
cpu: 50m
memory: 10Mi
limits:
cpu: 100m
memory: 20Mi
---
apiVersion: v1
kind: Service
metadata:
name: ngx-hpa-svc
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: ngx-hpa-dep
在这个YAML里我只部署了一个Nginx实例,名字是 ngx-hpa-dep。注意在它的 spec 里一定要用 resources 字段写清楚资源配额,否则HorizontalPodAutoscaler会无法获取Pod的指标,也就无法实现自动化扩缩容。
接下来我们要用命令 kubectl autoscale 创建一个HorizontalPodAutoscaler的样板YAML文件,它有三个参数:
- min,Pod数量的最小值,也就是缩容的下限。
- max,Pod数量的最大值,也就是扩容的上限。
- cpu-percent,CPU使用率指标,当大于这个值时扩容,小于这个值时缩容。
好,现在我们就来为刚才的Nginx应用创建HorizontalPodAutoscaler,指定Pod数量最少2个,最多10个,CPU使用率指标设置的小一点,5%,方便我们观察扩容现象:
export out="--dry-run=client -o yaml" # 定义Shell变量
kubectl autoscale deploy ngx-hpa-dep --min=2 --max=10 --cpu-percent=5 $out
得到的YAML描述文件就是这样:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: ngx-hpa
spec:
maxReplicas: 10
minReplicas: 2
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: ngx-hpa-dep
targetCPUUtilizationPercentage: 5
我们再使用命令 kubectl apply 创建这个HorizontalPodAutoscaler后,它会发现Deployment里的实例只有1个,不符合min定义的下限的要求,就先扩容到2个:
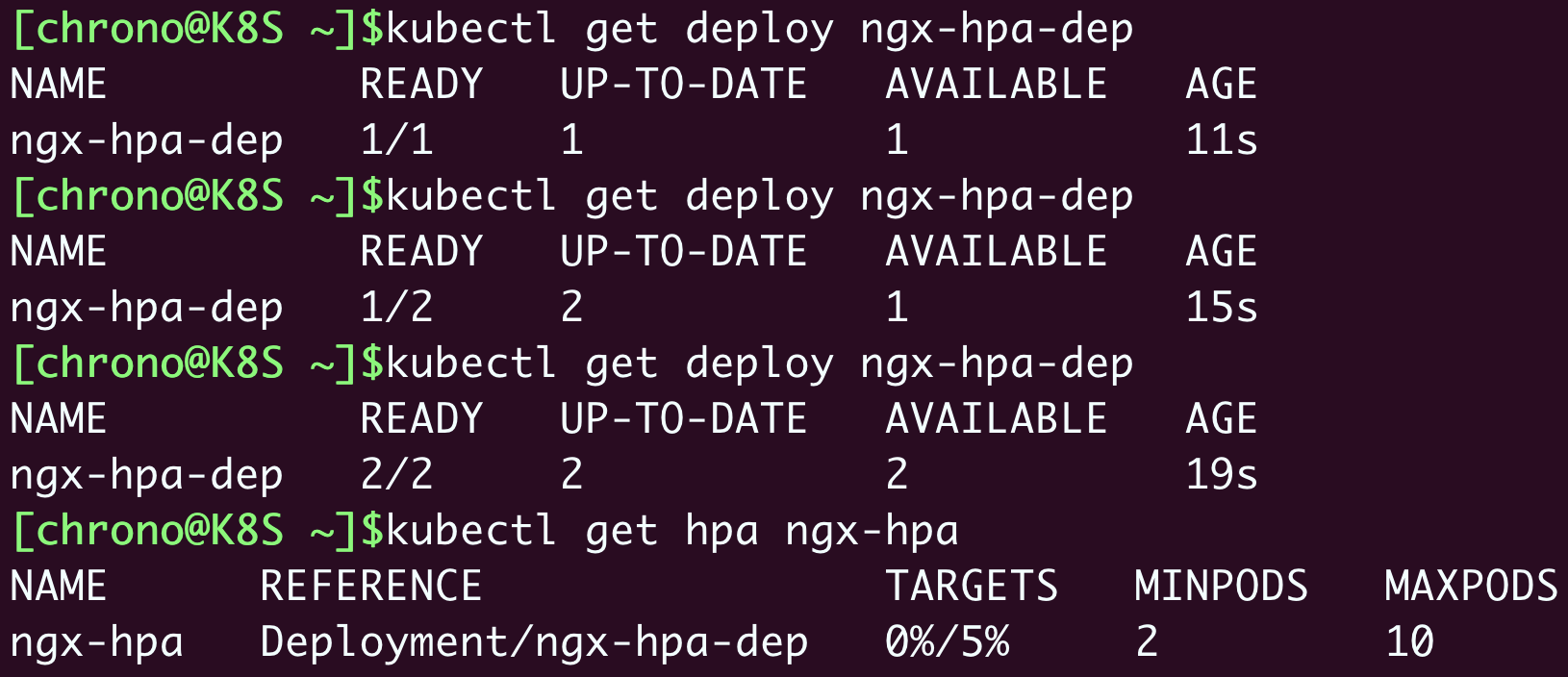
从这张截图里你可以看到,HorizontalPodAutoscaler会根据YAML里的描述,找到要管理的Deployment,把Pod数量调整成2个,再通过Metrics Server不断地监测Pod的CPU使用率。
下面我们来给Nginx加上压力流量,运行一个测试Pod,使用的镜像是“httpd:alpine”,它里面有HTTP性能测试工具ab(Apache Bench):
kubectl run test -it --image=httpd:alpine -- sh

然后我们向Nginx发送一百万个请求,持续1分钟,再用 kubectl get hpa 来观察HorizontalPodAutoscaler的运行状况:
ab -c 10 -t 60 -n 1000000 'http://ngx-hpa-svc/'
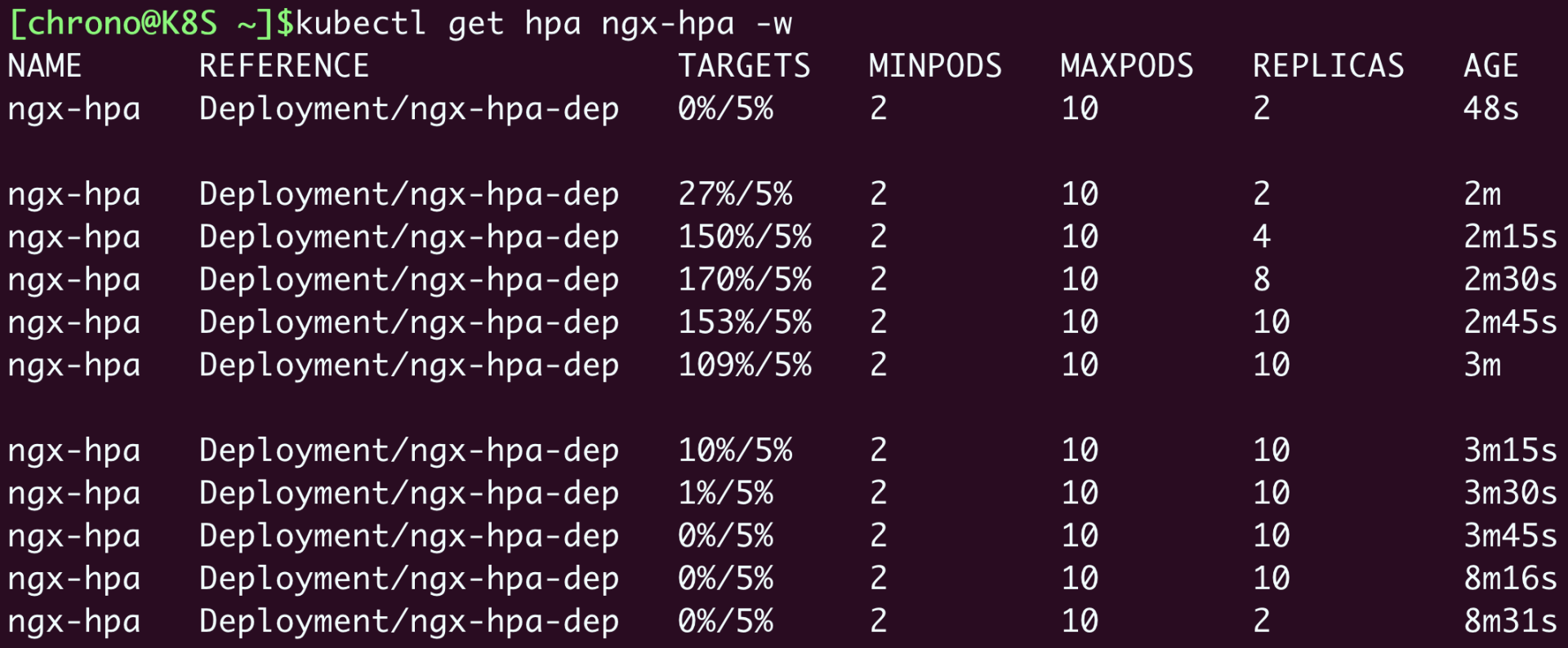
因为Metrics Server大约每15秒采集一次数据,所以HorizontalPodAutoscaler的自动化扩容和缩容也是按照这个时间点来逐步处理的。
当它发现目标的CPU使用率超过了预定的5%后,就会以2的倍数开始扩容,一直到数量上限,然后持续监控一段时间,如果CPU使用率回落,就会再缩容到最小值。
Prometheus
显然,有了Metrics Server和HorizontalPodAutoscaler的帮助,我们的应用管理工作又轻松了一些。不过,Metrics Server能够获取的指标还是太少了,只有CPU和内存,想要监控到更多更全面的应用运行状况,还得请出这方面的权威项目“Prometheus”。
其实,Prometheus的历史比Kubernetes还要早一些,它最初是由Google的离职员工在2012年创建的开源项目,灵感来源于Borg配套的BorgMon监控系统。后来在2016年,Prometheus作为第二个项目加入了CNCF,并在2018年继Kubernetes之后顺利毕业,成为了CNCF的不折不扣的“二当家”,也是云原生监控领域的“事实标准”。

和Kubernetes一样,Prometheus也是一个庞大的系统,我们这里就只做一个简略的介绍。
下面的这张图是Prometheus官方的架构图,几乎所有文章在讲Prometheus的时候必然要拿出来,所以我也没办法“免俗”:
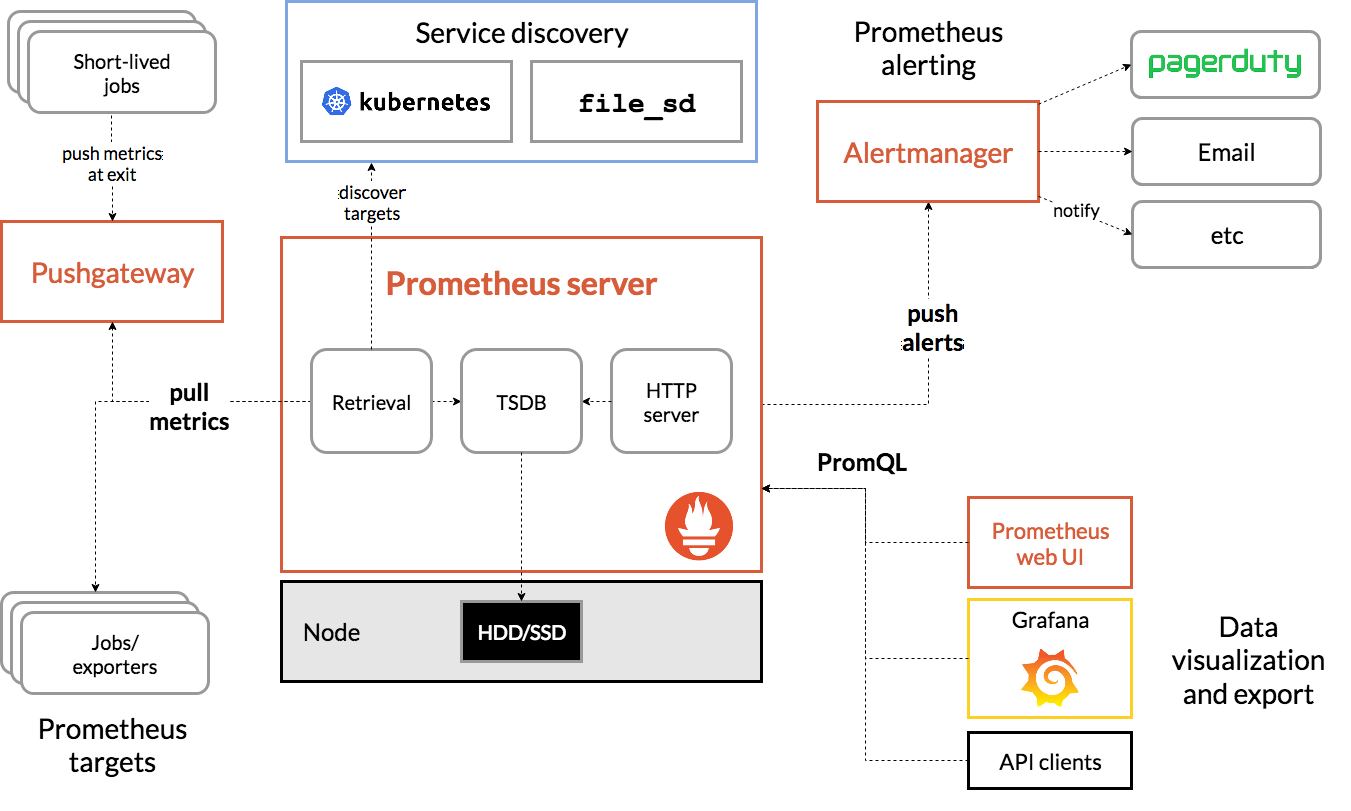
Prometheus系统的核心是它的Server,里面有一个时序数据库TSDB,用来存储监控数据,另一个组件Retrieval使用拉取(Pull)的方式从各个目标收集数据,再通过HTTP Server把这些数据交给外界使用。
在Prometheus Server之外还有三个重要的组件:
- Push Gateway,用来适配一些特殊的监控目标,把默认的Pull模式转变为Push模式。
- Alert Manager,告警中心,预先设定规则,发现问题时就通过邮件等方式告警。
- Grafana是图形化界面,可以定制大量直观的监控仪表盘。
由于同属于CNCF,所以Prometheus自然就是“云原生”,在Kubernetes里运行是顺理成章的事情。不过它包含的组件实在是太多,部署起来有点麻烦,这里我选用了“kube-prometheus”项目(https://github.com/prometheus-operator/kube-prometheus/),感觉操作起来比较容易些。
下面就跟着我来在Kubernetes实验环境里体验一下Prometheus吧。
我们先要下载kube-prometheus的源码包,当前的最新版本是0.11:
wget https://github.com/prometheus-operator/kube-prometheus/archive/refs/tags/v0.11.0.tar.gz
解压缩后,Prometheus部署相关的YAML文件都在 manifests 目录里,有近100个,你可以先大概看一下。
和Metrics Server一样,我们也必须要做一些准备工作,才能够安装Prometheus。
第一步,是修改 prometheus-service.yaml、grafana-service.yaml。
这两个文件定义了Prometheus和Grafana服务对象,我们可以给它们添加 type: NodePort(参考第20讲),这样就可以直接通过节点的IP地址访问(当然你也可以配置成Ingress)。
第二步,是修改 kubeStateMetrics-deployment.yaml、prometheusAdapter-deployment.yaml,因为它们里面有两个存放在gcr.io的镜像,必须解决下载镜像的问题。
但很遗憾,我没有在国内网站上找到它们的下载方式,为了能够顺利安装,只能把它们下载后再上传到Docker Hub上。所以你需要修改镜像名字,把前缀都改成 chronolaw:
image: k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.5.0
image: k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1
image: chronolaw/kube-state-metrics:v2.5.0
image: chronolaw/prometheus-adapter:v0.9.1
这两个准备工作完成之后,我们要执行两个 kubectl create 命令来部署Prometheus,先是 manifests/setup 目录,创建名字空间等基本对象,然后才是 manifests 目录:
kubectl create -f manifests/setup
kubectl create -f manifests
Prometheus的对象都在名字空间“monitoring”里,创建之后可以用 kubectl get 来查看状态:
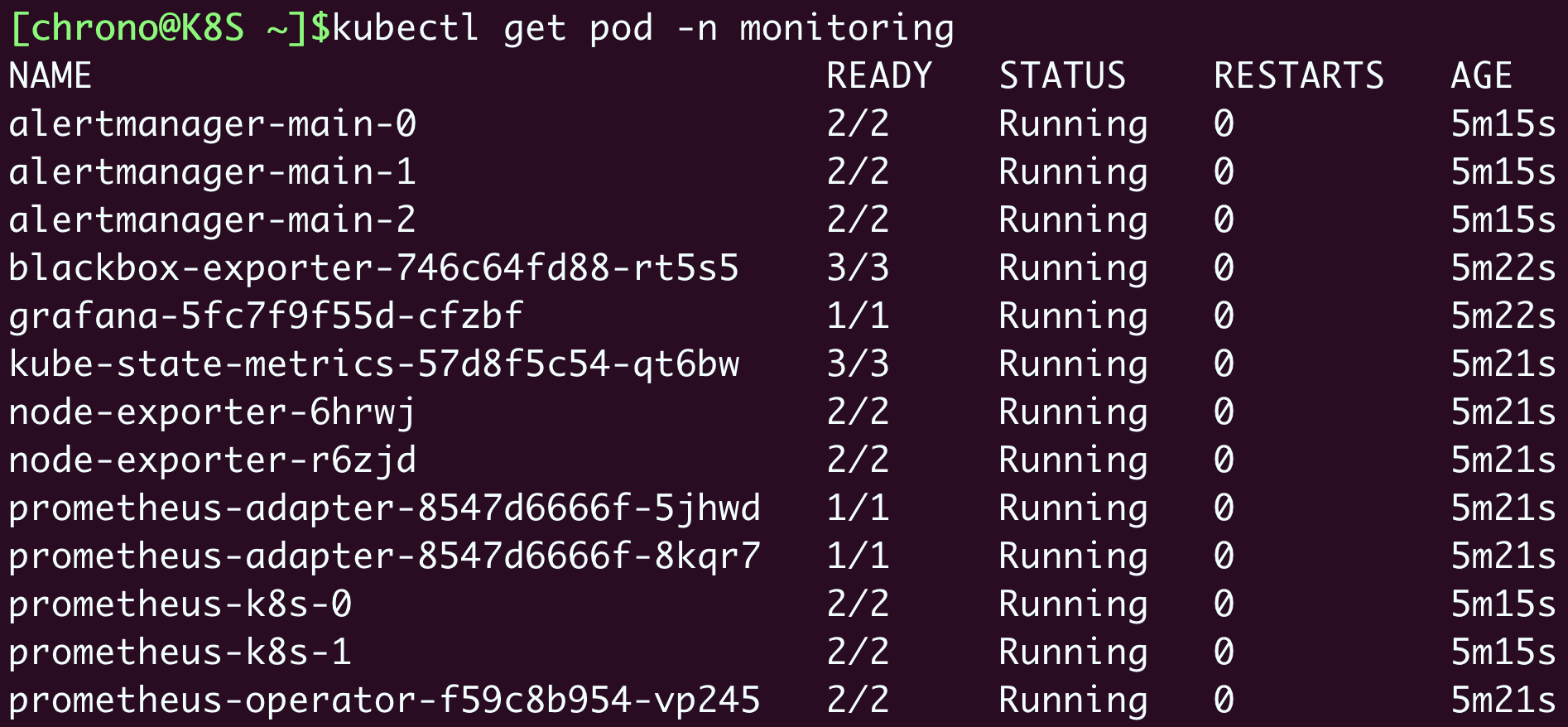
确定这些Pod都运行正常,我们再来看看它对外的服务端口:
kubectl get svc -n monitoring
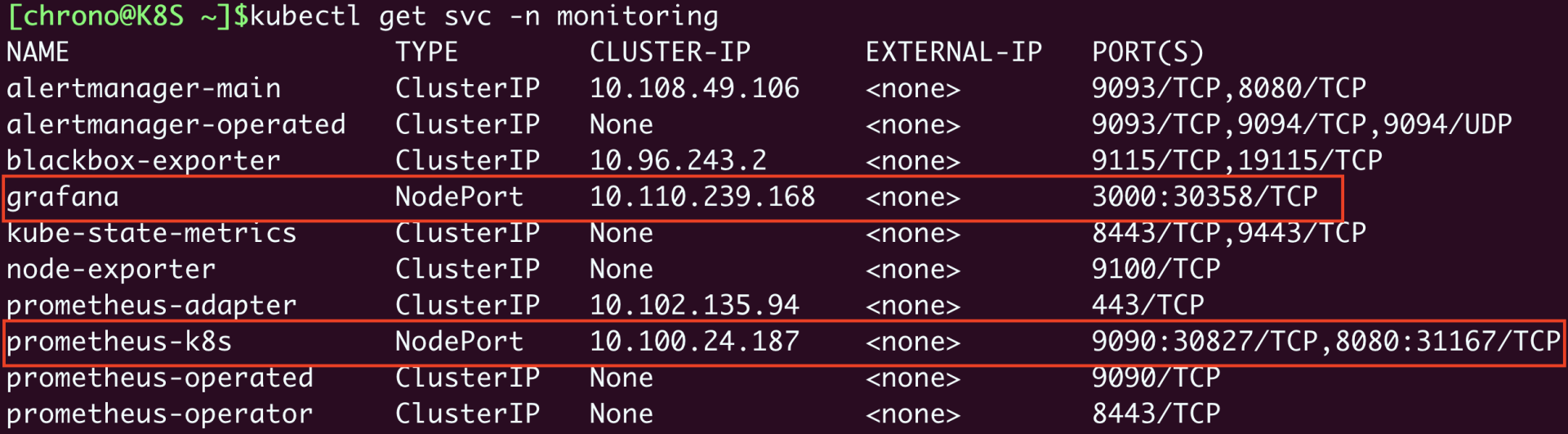
前面修改了Grafana和Prometheus的Service对象,所以这两个服务就在节点上开了端口,Grafana是“30358”,Prometheus有两个端口,其中“9090”对应的“30827”是Web端口。
在浏览器里输入节点的IP地址(我这里是“http://192.168.10.210”),再加上端口号“30827”,我们就能看到Prometheus自带的Web界面,:
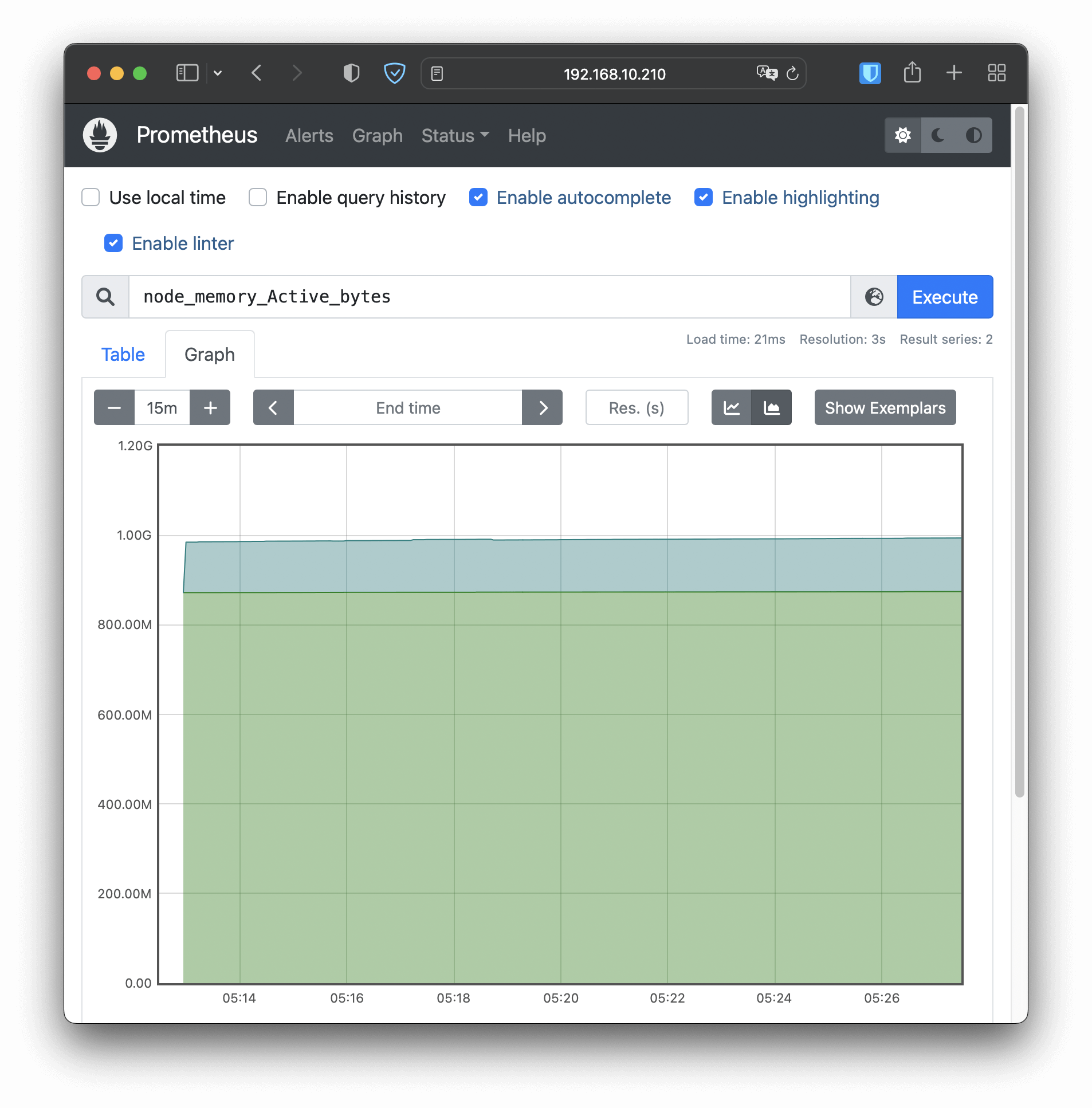
Web界面上有一个查询框,可以使用PromQL来查询指标,生成可视化图表,比如在这个截图里我就选择了“node_memory_Active_bytes”这个指标,意思是当前正在使用的内存容量。
Prometheus的Web界面比较简单,通常只用来调试、测试,不适合实际监控。我们再来看Grafana,访问节点的端口“30358”(我这里是“http://192.168.10.210:30358”),它会要求你先登录,默认的用户名和密码都是“admin”:

Grafana内部已经预置了很多强大易用的仪表盘,你可以在左侧菜单栏的“Dashboards - Browse”里任意挑选一个:
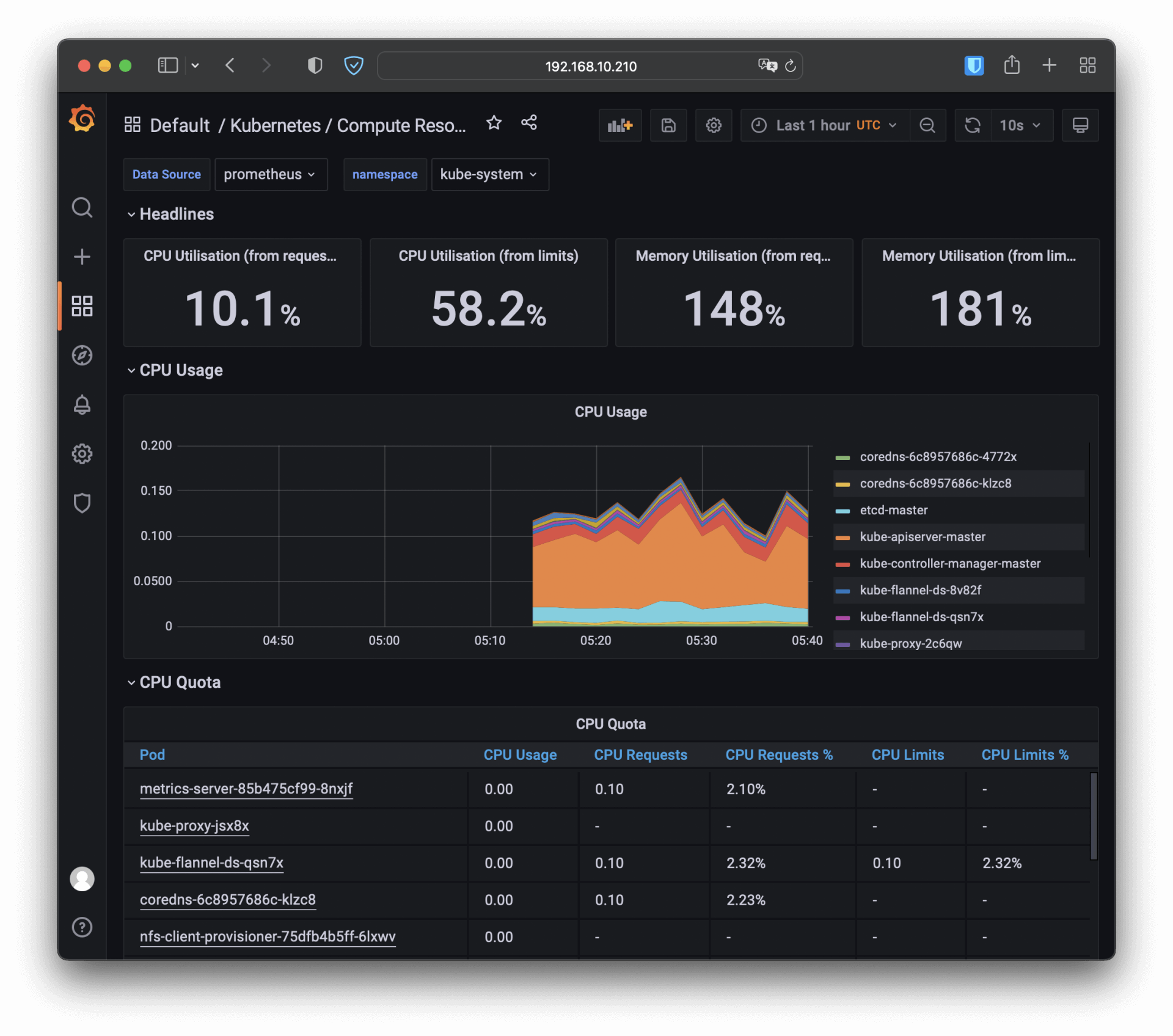
比如我选择了“Kubernetes / Compute Resources / Namespace (Pods)”这个仪表盘,就会出来一个非常漂亮图表,比Metrics Server的 kubectl top 命令要好看得多,各种数据一目了然:
关于Prometheus就暂时介绍到这里,再往下讲可能就要偏离我们的Kubernetes主题了,如果你对它感兴趣的话,可以课后再去它的官网上看文档,或者参考其他的学习资料。
小结
在云原生时代,系统的透明性和可观测性是非常重要的。今天我们一起学习了Kubernetes里的两个系统监控项目:命令行方式的Metrics Server、图形化界面的Prometheus,利用好它们就可以让我们随时掌握Kubernetes集群的运行状态,做到“明察秋毫”。
再简单小结一下今天的内容:
- Metrics Server是一个Kubernetes插件,能够收集系统的核心资源指标,相关的命令是
kubectl top。 - Prometheus是云原生监控领域的“事实标准”,用PromQL语言来查询数据,配合Grafana可以展示直观的图形界面,方便监控。
- HorizontalPodAutoscaler实现了应用的自动水平伸缩功能,它从Metrics Server获取应用的运行指标,再实时调整Pod数量,可以很好地应对突发流量。
课下作业
最后是课下作业时间,给你留两个思考题:
- 部署了HorizontalPodAutoscaler之后,如果再执行
kubectl scale手动扩容会发生什么呢? - 你有过应用监控的经验吗?应该关注哪些重要的指标呢?
非常期待在留言区看到你的发言,同我同其他同学一起讨论。我们下节课再见。

精选留言
2022-09-06 01:14:24
1: metris-server如果出现执行命令 kubectl top 不生效可以加如下配置
apiVersion: apps/v1
kind: Deployment
metadata:
...
template:
....
spec:
nodeName: k8s-master #你自己的节点名称
2: prometheus 镜像问题
这里我偷懒,不用骑驴找驴了,直接用老师的
这里我建议您push到docker hub (因为集群有多个节点,push到docker hub上,这样pod调度到任意一个节点都可以方便下载)
docker pull chronolaw/kube-state-metrics:v2.5.0
docker tag chronolaw/kube-state-metrics:v2.5.0 k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.5.0
docker rmi chronolaw/kube-state-metrics:v2.5.0
docker push k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.5.0
prometheus-adapter 老师的版本运行不起来,我在docker hub上 找了一个可以用的
docker pull pengyc2019/prometheus-adapter:v0.9.1
docker tag pengyc2019/prometheus-adapter:v0.9.1 k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1
docker rmi pengyc2019/prometheus-adapter:v0.9.1
docker push k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1
然后执行:
kubectl create -f manifests/setup
kubectl create -f manifests
到此,运行成功
2022-11-01 16:15:42
1. 按文中的步骤,使用ab加压,可以看到pod增加到了10个
[shaohan@k8s4 ~]$ kubectl get hpa ngx-hpa -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
ngx-hpa Deployment/ngx-hpa-dep 150%/5% 2 10 2 90s
ngx-hpa Deployment/ngx-hpa-dep 129%/5% 2 10 4 105s
ngx-hpa Deployment/ngx-hpa-dep 93%/5% 2 10 8 2m
ngx-hpa Deployment/ngx-hpa-dep 57%/5% 2 10 10 2m15s
2. 在ab停止运行之后过了几分钟,kubectl get hpa ngx-hpa -w的输出中才出现了一行新数据,如下
ngx-hpa Deployment/ngx-hpa-dep 0%/5% 2 10 10 7m31s
仍然是10个pod,并没有自动缩容
3. 查看pod
[shaohan@k8s4 ~]$ kubectl get pod
NAME READY STATUS RESTARTS AGE
ngx-hpa-dep-86f66c75f5-d82rh 0/1 Pending 0 63s
ngx-hpa-dep-86f66c75f5-dtc88 0/1 Pending 0 63s
(其他ngx-hpa-dep-xxx省略,因为评论字数限制……)
test 1/1 Running 1 (6s ago) 2m5s
可以看到,有两个pod是pending状态的,kubectl describe这两个pending pod中的一个,可以看到
Warning FailedScheduling 18s (x2 over 85s) default-scheduler 0/2 nodes are available: 1 Insufficient cpu, 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate.
是因为worker节点资源不足,master节点没有开放给pod调度,造成扩容时有两个pod虽然创建了,但一直在等待资源而没有进入running状态
4. 手动删除了用于执行ab的apache pod,释放资源,然后立刻查看pod,就只有两个了
kubectl get hpa ngx-hpa -w的输出中也出现了一行新数据
ngx-hpa Deployment/ngx-hpa-dep 0%/5% 2 10 2 7m46s
自动缩容成功执行了
所以,看起来,hpa是“严格按顺序执行的”,它按照规则设定的条件,要扩容到10个pod,在10个pod全都running之前,即使已经符合缩容的条件了,它也不执行缩容,而是要等到之前扩容的操作彻底完成,也就是10个pod全都running了,才会执行缩容
2022-08-31 17:17:50
Q1:Grafana 不是Prometheus的组件吧
架构图中标红色的是属于Prometheus,在UI方面,架构图中的”prometheus web ui”应该是Prometheus的组件吧。Grafana好像是一个公共组件,不是Prometheus独有的。
Q2: Prometheus部署后有四个POD的状态不是RUNNING
blackbox-exporter-746c64fd88-ts299:状态是ImagePullBackOff
prometheus-adapter-8547d6666f-6npn6:状态是CrashLoopBackOff,
错误信息:
sc = Get "https://registry-1.docker.io/v2/jimmidyson/configmap-reload/manifests/sha256:91467ba755a0c41199a63fe80a2c321c06edc4d3affb4f0ab6b3d20a49ed88d1": net/http: TLS handshake timeout
好像和TLS有关,需要和Metrics Server一样加“kubelet-insecure-tls”吗?在哪个YAML文件中修改?
Q3:Prometheus部署的逆向操作是什么?
用这两个命令来部署:
kubectl create -f manifests/setup
kubectl create -f manifests
部署后,如果想重新部署,需要清理环境,那么,怎么清理掉以前部署的东西?
和kubectl create -f manifests/setup相反的操作是“kubectl delete -f manifests/setup”吗?
2022-09-02 01:40:15
2022-11-30 22:48:46
<1> 注意metrics-server版本,我拉下来的yml文件版本变成了v0.6.2,所以要根据最新的components.yaml文件中的metrics-server版本对应改一下老师的脚本;
<2> 注意要在Worker节点执行脚本,我就在master节点上执行了好几遍。。。
2022-10-02 12:03:21
1,会根据设置进行扩容(scale out),但是如果不满足 HPA 的指标条件,接着会立即进行缩容(scale in),下面是我的操作观察到的日志
---
Normal SuccessfulCreate 3s replicaset-controller Created pod: ngx-hpa-dep-86f66c75f5-z2gjk
Normal SuccessfulCreate 3s replicaset-controller Created pod: ngx-hpa-dep-86f66c75f5-p46lr
Normal SuccessfulDelete 3s replicaset-controller Deleted pod: ngx-hpa-dep-86f66c75f5-z2gjk
Normal SuccessfulDelete 3s replicaset-controller Deleted pod: ngx-hpa-dep-86f66c75f5-p46lr
---
2,我现有的经验很有限,主要集中在单机/集群机器指标的监控,以及对于应用及产品的监控(通过监控日志实现的),同时结合一些告警系统(alert),以便快速发现故障及解决。
关注的指标有 CPU、内存、网卡、磁盘读写,应用的性能监控和错误率(可用性)监控。性能监控指标主要是响应时间(RT)、各种吞吐量(比如QPS)等。错误率指标主要是指应用错误及异常、HTTP错误响应代码等。
2022-09-01 22:41:48
文中采用cpu占用率,比如md5sum是非常偏向于cpu运算的工作,但扩容可能并不能达到预期的效果(工作占满了一个核但是再多一个核却不能分摊这个工作)。
所以看起来系统负载而非占用率应该是更好的扩容指标,不知道我这么理解是否正确?
2023-02-16 16:00:27
2023-02-05 08:36:09
应该怎么配置呢?
2022-11-01 17:00:41
[shaohan@k8s4 ~]$ kubectl top node
Error from server (ServiceUnavailable): the server is currently unable to handle the request (get nodes.metrics.k8s.io)
执行kubectl get apiservice v1beta1.metrics.k8s.io -o yaml看到
status:
conditions:
- lastTransitionTime: "2022-10-29T09:57:08Z"
message: 'failing or missing response from https://10.98.115.140:443/apis/metrics.k8s.io/v1beta1:
Get "https://10.98.115.140:443/apis/metrics.k8s.io/v1beta1": dial tcp 10.98.115.140:443:
i/o timeout'
reason: FailedDiscoveryCheck
status: "False"
type: Available
在components.yaml中给deployment对象添加hostNetwork: true(在spec->template->spec下)就可以解决这个问题
2022-10-02 12:09:25
```bash
# 查看 Pod 状态,发现 prometheus-operator 无法正常启动
kubectl get pod -n monitoring
NAME READY STATUS RESTARTS AGE
blackbox-exporter-746c64fd88-wmnd5 3/3 Running 0 68s
grafana-5fc7f9f55d-qqt77 1/1 Running 0 68s
kube-state-metrics-6c8846558c-w66x9 3/3 Running 0 67s
node-exporter-68l4p 2/2 Running 0 67s
node-exporter-vs55z 2/2 Running 0 67s
prometheus-adapter-6455646bdc-4lz5l 1/1 Running 0 66s
prometheus-adapter-6455646bdc-gxbrl 1/1 Running 0 66s
prometheus-operator-f59c8b954-btxtw 0/2 Pending 0 66s
# 调查 Pod prometheus-operator
kubectl describe pod prometheus-operator-f59c8b954-btxtw -n monitoring
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 82s default-scheduler 0/2 nodes are available: 1 Insufficient memory, 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate.
Warning FailedScheduling 20s default-scheduler 0/2 nodes are available: 1 Insufficient memory, 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate.
# 去除 node 的污点 node-role.kubernetes.io/master
kubectl taint nodes --all node-role.kubernetes.io/master-
```
2022-08-31 15:41:14
2022-08-31 09:54:28
2022-08-31 08:07:54
2024-09-04 01:32:20
$ kubectl top node 提示出错
Error from server (ServiceUnavailable): the server is currently unable to handle the request (get nodes.metrics.k8s.io)
期间尝试:
- spec -> template -> spec 下添加 hostNetwork: true
错误依旧,查看 apiserver 日志:
$ kubectl logs -n kube-system kube-apiserver-master
E0902 17:28:30.885994 1 available_controller.go:524] v1beta1.metrics.k8s.io failed with: failing or missing response from https://10.101.216.86:443/apis/metrics.k8s.io/v1beta1: Get "https://10.101.216.86:443/apis/metrics.k8s.io/v1beta1": net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
看了下 kubectl describe -n kube-system pod metrics-server-6dc55579bb-qv98v 发现 metrics-server 部署在 worker 节点
Node: worker/192.168.10.130
看高赞评论,尝试下指定部署到 master 看能不能行,操作:
去掉 hostNetwork: true,同时 spec -> template -> spec 下添加 nodeName: master,这回正常显示 master 节点的用量了,但是 worker 节点所有字段都显示 <Unknown>
查看 metrics-server 日志
$ kubectl logs -n kube-system metrics-server-6dc55579bb-qv98v
E0903 15:50:56.622351 1 scraper.go:140] "Failed to scrape node" err="Get \"https://192.168.10.130:10250/metrics/resource\": context deadline exceeded" node="worker"
查看了 worker 的防火墙、VPN 也都没问题,访问 worker 节点的 10250 端口(kubelet)也正常:curl -k 'https://192.168.10.130:10250/metrics/resource'
没辙了,对比了下老师的 components.yaml(k8s_study/metrics/components.yaml)和我的,最后作了如下修改,kubectl top node 输出才终于正常..
1. spec -> template -> spec 下添加 hostNetwork: true
2. spec -> template -> spec 下添加 nodeName: master
3. containers -> secure-port=10250 改为 secure-port=4443
4. containerPort: 10250 改为 secure-port=4443
5. metrics-server deployment 的镜像(image)改为 k8s.gcr.io/metrics-server/metrics-server:v0.6.1
2023-12-29 16:39:08
1. 发现adapter运行不起来的话,如
prometheus-adapter-8547d6666f-9wj9j 0/1 CrashLoopBackOff
是老师的prometheus-adapter:v0.9.1镜像有问题,我也打了一个镜像oiouou/prometheus-adapter:v0.9.1,实测正常能用
2. prometheus-k8s-0 一直处于Pending状态,我这里是内存不足了,master和worker我都分配了2G内存,之后把worker升到4G,pod都正常了
2023-10-20 10:12:15
repo=registry.aliyuncs.com/google_containers
name=registry.k8s.io/metrics-server/metrics-server:v0.6.4
src_name=metrics-server:v0.6.4
sudo docker pull $repo/$src_name
sudo docker tag $repo/$src_name $name
sudo docker rmi $repo/$src_name
2023-08-03 16:11:36
这是因为 HorizontalPodAutoscaler 是根据 Metrics Server 提供的指标来自动伸缩 Pod 的数量的。当手动执行 kubectl scale 命令时,虽然可以直接改变 Pod 的数量,但是 HorizontalPodAutoscaler 会继续监控 Metrics Server 提供的指标,并根据自动伸缩策略对 Pod 的数量进行调整,以确保 Pod 的数量符合预定的范围。
总结起来,当部署了 HorizontalPodAutoscaler 后,建议使用 HorizontalPodAutoscaler 来自动伸缩 Pod 的数量,而不是直接使用 kubectl scale 命令进行手动扩容。这样可以确保自动伸缩策略的生效,以及避免手动扩容和自动伸缩策略之间的冲突。
2023-07-19 17:10:42
2023-05-04 19:39:33