你好,我是陈天。储备好前置知识之后,今天我们就正式开始 Rust 语言本身的学习。
学语言最好的捷径就是把自己置身于语言的环境中,而且我们程序员讲究 “get hands dirty”,直接从代码开始学能带来最直观的体验。所以从这一讲开始,你就要在电脑上设置好 Rust 环境了。
今天会讲到很多 Rust 的基础知识,我都精心构造了代码案例来帮你理解,非常推荐你自己一行行敲入这些代码,边写边思考为什么这么写,然后在运行时体会执行和输出的过程。如果遇到了问题,你也可以点击每个例子附带的代码链接,在 Rust playground 中运行。
Rust 安装起来非常方便,你可以用 rustup.rs 中给出的方法,根据你的操作系统进行安装。比如在 UNIX 系统下,可以直接运行:
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
这会在你的系统上安装 Rust 工具链,之后,你就可以在本地用 cargo new 新建 Rust 项目、尝试 Rust 功能。动起手来,试试用Rust写你的第一个 hello world 程序吧!
fn main() {
println!("Hello world!");
}
你可以使用任何编辑器来撰写 Rust 代码,我个人偏爱 VS Code,因为它免费,功能强大且速度很快。在 VS Code 下我为 Rust 安装了一些插件,下面是我的安装顺序,你可以参考:
- rust-analyzer:它会实时编译和分析你的 Rust 代码,提示代码中的错误,并对类型进行标注。你也可以使用官方的 Rust 插件取代。
- rust syntax:为代码提供语法高亮。
- crates:帮助你分析当前项目的依赖是否是最新的版本。
- better toml:Rust 使用 toml 做项目的配置管理。better toml 可以帮你语法高亮,并展示 toml 文件中的错误。
- rust test lens:可以帮你快速运行某个 Rust 测试。
- Tabnine:基于 AI 的自动补全,可以帮助你更快地撰写代码。
第一个实用的 Rust 程序
现在你已经有工具和环境了,尽管我们目前一行 Rust 语法都还没有介绍,但这不妨碍我们写一个稍稍有用的 Rust 程序,跑一遍之后,你对 Rust 的基本功能、关键语法和生态系统就基本心中有数了,我们再来详细分析。
一定要动起手来,跟着课程节奏一行一行敲,如果碰到不太理解的知识点,不要担心,今天只需要你先把代码运行起来,我们后面会循序渐进学习到各个难点的。
另外,我也建议你用自己常用的编程语言做同样的需求,和 Rust 对比一下,看简洁程度、代码可读性孰优孰劣。
这个程序的需求很简单,通过 HTTP 请求 Rust 官网首页,然后把获得的 HTML 转换成 Markdown 保存起来。我相信用 JavaScript 或者 Python,只要选好相关的依赖,这也就是十多行代码的样子。我们看看用 Rust 怎么处理。
首先,我们用 cargo new scrape_url 生成一个新项目。默认情况下,这条命令会生成一个可执行项目 scrape_url,入口在 src/main.rs。我们在 Cargo.toml 文件里,加入如下的依赖:
[dependencies]
reqwest = { version = "0.11", features = ["blocking"] }
html2md = "0.2"
Cargo.toml 是 Rust 项目的配置管理文件,它符合 toml 的语法。我们为这个项目添加了两个依赖:reqwest 和 html2md。reqwest 是一个 HTTP 客户端,它的使用方式和 Python 下的 request 类似;html2md 顾名思义,把 HTML 文本转换成Markdown。
接下来,在 src/main.rs 里,我们为 main() 函数加入以下代码:
use std::fs;
fn main() {
let url = "https://www.rust-lang.org/";
let output = "rust.md";
println!("Fetching url: {}", url);
let body = reqwest::blocking::get(url).unwrap().text().unwrap();
println!("Converting html to markdown...");
let md = html2md::parse_html(&body);
fs::write(output, md.as_bytes()).unwrap();
println!("Converted markdown has been saved in {}.", output);
}
保存后,在命令行下,进入这个项目的目录,运行 cargo run,在一段略微漫长的编译后,程序开始运行,在命令行下,你会看到如下的输出:
Fetching url: https://www.rust-lang.org/
Converting html to markdown...
Converted markdown has been saved in rust.md.
并且,在当前目录下,一个 rust.md 文件被创建出来了。打开一看,其内容就是 Rust 官网主页的内容。
Bingo!我们第一个 Rust 程序运行成功!
从这段并不长的代码中,我们可以感受到 Rust 的一些基本特点:
首先,Rust 使用名为 cargo 的工具来管理项目,它类似 Node.js 的 npm、Golang 的 go,用来做依赖管理以及开发过程中的任务管理,比如编译、运行、测试、代码格式化等等。
其次,Rust 的整体语法偏 C/C++ 风格。函数体用花括号 {} 包裹,表达式之间用分号 ; 分隔,访问结构体的成员函数或者变量使用点 . 运算符,而访问命名空间(namespace)或者对象的静态函数使用双冒号 :: 运算符。如果要简化对命名空间内部的函数或者数据类型的引用,可以使用 use 关键字,比如 use std::fs。此外,可执行体的入口函数是 main()。
另外,你也很容易看到,Rust 虽然是一门强类型语言,但编译器支持类型推导,这使得写代码时的直观感受和写脚本语言差不多。
很多不习惯类型推导的开发者,觉得这会降低代码的可读性,因为可能需要根据上下文才知道当前变量是什么类型。不过没关系,如果你在编辑器中使用了 rust-analyzer 插件,变量的类型会自动提示出来:
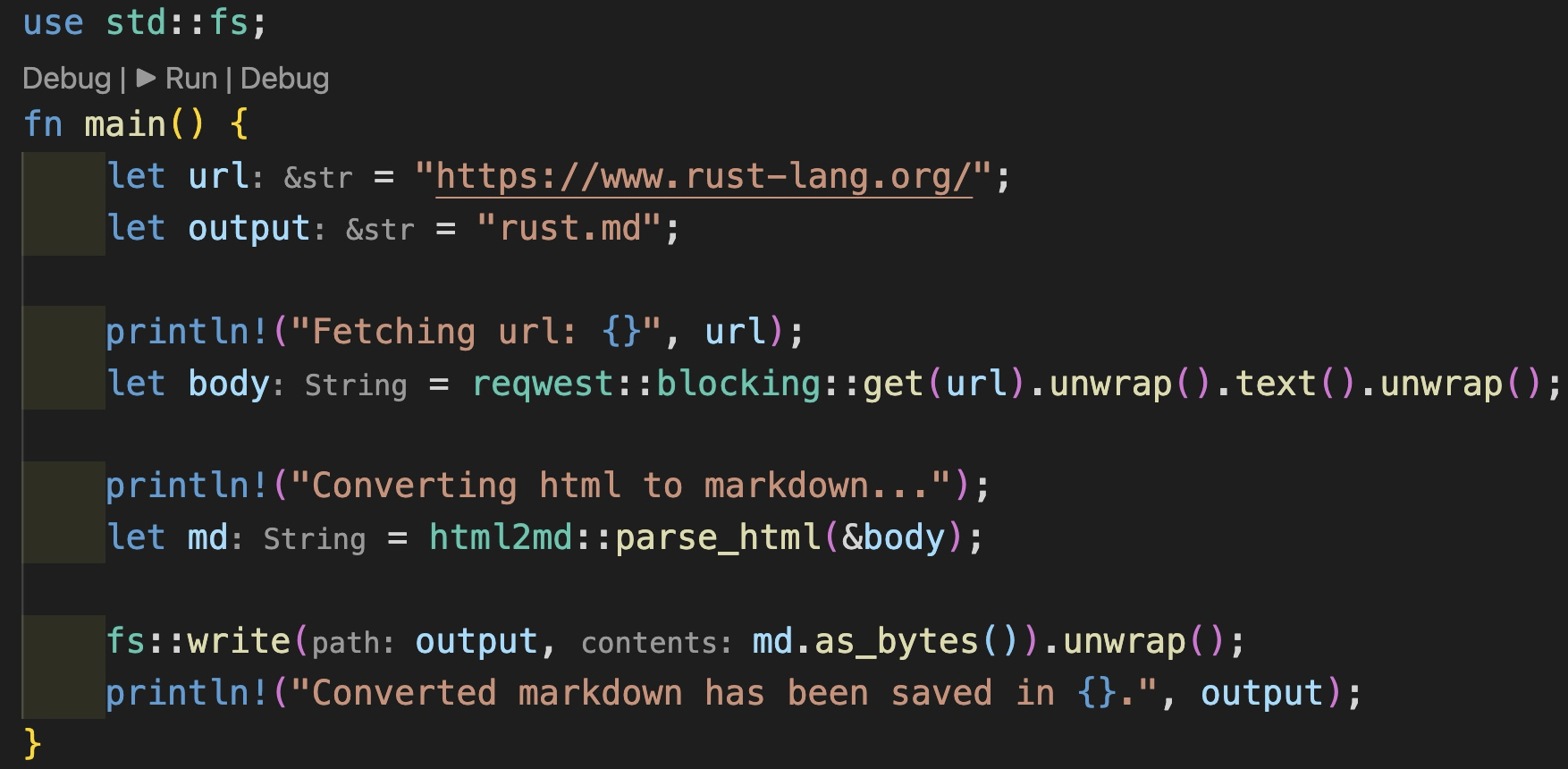
最后,Rust 支持宏编程,很多基础的功能比如 println!() 都被封装成一个宏,便于开发者写出简洁的代码。
这里例子没有展现出来,但 Rust 还具备的其它特点有:
- Rust 的变量默认是不可变的,如果要修改变量的值,需要显式地使用 mut 关键字。
- 除了 let / static / const / fn 等少数语句外,Rust 绝大多数代码都是表达式(expression)。所以 if / while / for / loop 都会返回一个值,函数最后一个表达式就是函数的返回值,这和函数式编程语言一致。
- Rust 支持面向接口编程和泛型编程。
- Rust 有非常丰富的数据类型和强大的标准库。
- Rust 有非常丰富的控制流程,包括模式匹配(pattern match)。
第一个实用的 Rust 程序就运行成功了,不知道你现在是不是有点迟疑,这些我现在都不太懂怎么办,是不是得先去把这些都掌握了才能继续学?不要迟疑,跟着继续学,后面都会讲到。
接下来,为了快速入门 Rust,我们一起梳理 Rust 开发的基本内容。
这部分涉及的知识在各个编程语言中都大同小异,略微枯燥,但是这一讲是我们后续学习的基础,建议你每段示例代码都写一下,运行一下,并且和自己熟悉的语言对比来加深印象。

基本语法和基础数据类型
首先我们看在 Rust 下,我们如何定义变量、函数和数据结构。
变量和函数
前面说到,Rust 支持类型推导,在编译器能够推导类型的情况下,变量类型一般可以省略,但常量(const)和静态变量(static)必须声明类型。
定义变量的时候,根据需要,你可以添加 mut 关键字让变量具备可变性。默认变量不可变是一个很重要的特性,它符合最小权限原则(Principle of Least Privilege),有助于我们写出健壮且正确的代码。当你使用 mut 却没有修改变量,Rust 编译期会友好地报警,提示你移除不必要的 mut。
在Rust 下,函数是一等公民,可以作为参数或者返回值。我们来看一个函数作为参数的例子(代码):
fn apply(value: i32, f: fn(i32) -> i32) -> i32 {
f(value)
}
fn square(value: i32) -> i32 {
value * value
}
fn cube(value: i32) -> i32 {
value * value * value
}
fn main() {
println!("apply square: {}", apply(2, square));
println!("apply cube: {}", apply(2, cube));
}
这里 fn(i32) -> i32 是 apply 函数第二个参数的类型,它表明接受一个函数作为参数,这个传入的函数必须是:参数只有一个,且类型为 i32,返回值类型也是 i32。
Rust 函数参数的类型和返回值的类型都必须显式定义,如果没有返回值可以省略,返回 unit。函数内部如果提前返回,需要用 return 关键字,否则最后一个表达式就是其返回值。如果最后一个表达式后添加了; 分号,隐含其返回值为 unit。你可以看这个例子(代码):
fn pi() -> f64 {
3.1415926
}
fn not_pi() {
3.1415926;
}
fn main() {
let is_pi = pi();
let is_unit1 = not_pi();
let is_unit2 = {
pi();
};
println!("is_pi: {:?}, is_unit1: {:?}, is_unit2: {:?}", is_pi, is_unit1, is_unit2);
}
数据结构
了解了函数如何定义后,我们来看看 Rust 下如何定义数据结构。
数据结构是程序的核心组成部分,在对复杂的问题进行建模时,我们就要自定义数据结构。Rust 非常强大,可以用 struct 定义结构体,用 enum 定义标签联合体(tagged union),还可以像 Python 一样随手定义元组(tuple)类型。
比如我们可以这样定义一个聊天服务的数据结构(代码):
#[derive(Debug)]
enum Gender {
Unspecified = 0,
Female = 1,
Male = 2,
}
#[derive(Debug, Copy, Clone)]
struct UserId(u64);
#[derive(Debug, Copy, Clone)]
struct TopicId(u64);
#[derive(Debug)]
struct User {
id: UserId,
name: String,
gender: Gender,
}
#[derive(Debug)]
struct Topic {
id: TopicId,
name: String,
owner: UserId,
}
// 定义聊天室中可能发生的事件
#[derive(Debug)]
enum Event {
Join((UserId, TopicId)),
Leave((UserId, TopicId)),
Message((UserId, TopicId, String)),
}
fn main() {
let alice = User { id: UserId(1), name: "Alice".into(), gender: Gender::Female };
let bob = User { id: UserId(2), name: "Bob".into(), gender: Gender::Male };
let topic = Topic { id: TopicId(1), name: "rust".into(), owner: UserId(1) };
let event1 = Event::Join((alice.id, topic.id));
let event2 = Event::Join((bob.id, topic.id));
let event3 = Event::Message((alice.id, topic.id, "Hello world!".into()));
println!("event1: {:?}, event2: {:?}, event3: {:?}", event1, event2, event3);
}
简单解释一下:
- Gender:一个枚举类型,在 Rust 下,使用 enum 可以定义类似 C 的枚举类型
- UserId/TopicId :struct 的特殊形式,称为元组结构体。它的域都是匿名的,可以用索引访问,适用于简单的结构体。
- User/Topic:标准的结构体,可以把任何类型组合在结构体里使用。
- Event:标准的标签联合体,它定义了三种事件:Join、Leave、Message。每种事件都有自己的数据结构。
在定义数据结构的时候,我们一般会加入修饰,为数据结构引入一些额外的行为。在 Rust 里,数据的行为通过 trait 来定义,后续我们会详细介绍 trait,你现在可以暂时认为 trait 定义了数据结构可以实现的接口,类似 Java 中的 interface。
一般我们用 impl 关键字为数据结构实现 trait,但 Rust 贴心地提供了派生宏(derive macro),可以大大简化一些标准接口的定义,比如 #[derive(Debug)] 为数据结构实现了 Debug trait,提供了 debug 能力,这样可以通过 {:?},用 println! 打印出来。
在定义 UserId / TopicId 时我们还用到了 Copy / Clone 两个派生宏,Clone 让数据结构可以被复制,而 Copy 则让数据结构可以在参数传递的时候自动按字节拷贝。在下一讲所有权中,我会具体讲什么时候需要 Copy。
简单总结一下 Rust 定义变量、函数和数据结构:

控制流程
程序的基本控制流程分为以下几种,我们应该都很熟悉了,重点看如何在 Rust 中运行。
顺序执行就是一行行代码往下执行。在执行的过程中,遇到函数,会发生函数调用。函数调用是代码在执行过程中,调用另一个函数,跳入其上下文执行,直到返回。
Rust 的循环和大部分语言都一致,支持死循环 loop、条件循环 while,以及对迭代器的循环 for。循环可以通过 break 提前终止,或者 continue 来跳到下一轮循环。
满足某个条件时会跳转, Rust 支持分支跳转、模式匹配、错误跳转和异步跳转。
- 分支跳转就是我们熟悉的 if/else;
- Rust 的模式匹配可以通过匹配表达式或者值的某部分的内容,来进行分支跳转;
- 在错误跳转中,当调用的函数返回错误时,Rust 会提前终止当前函数的执行,向上一层返回错误。
- 在 Rust 的异步跳转中 ,当 async 函数执行 await 时,程序当前上下文可能被阻塞,执行流程会跳转到另一个异步任务执行,直至 await 不再阻塞。
我们通过斐波那契数列,使用 if 和 loop / while / for 这几种循环,来实现程序的基本控制流程(代码):
fn fib_loop(n: u8) {
let mut a = 1;
let mut b = 1;
let mut i = 2u8;
loop {
let c = a + b;
a = b;
b = c;
i += 1;
println!("next val is {}", b);
if i >= n {
break;
}
}
}
fn fib_while(n: u8) {
let (mut a, mut b, mut i) = (1, 1, 2);
while i < n {
let c = a + b;
a = b;
b = c;
i += 1;
println!("next val is {}", b);
}
}
fn fib_for(n: u8) {
let (mut a, mut b) = (1, 1);
for _i in 2..n {
let c = a + b;
a = b;
b = c;
println!("next val is {}", b);
}
}
fn main() {
let n = 10;
fib_loop(n);
fib_while(n);
fib_for(n);
}
这里需要指出的是,Rust 的 for 循环可以用于任何实现了 IntoIterator trait 的数据结构。
在执行过程中,IntoIterator 会生成一个迭代器,for 循环不断从迭代器中取值,直到迭代器返回 None 为止。因而,for 循环实际上只是一个语法糖,编译器会将其展开使用 loop 循环对迭代器进行循环访问,直至返回 None。
在 fib_for 函数中,我们还看到 2…n 这样的语法,想必 Python 开发者一眼就能明白这是 Range 操作,2…n 包含 2<= x < n 的所有值。和 Python 一样,在Rust中,你也可以省略 Range 的下标或者上标,比如:
let arr = [1, 2, 3];
assert_eq!(arr[..], [1, 2, 3]);
assert_eq!(arr[0..=1], [1, 2]);
和 Python 不同的是,Range 不支持负数,所以你不能使用 arr[1..-1] 这样的代码。这是因为,Range 的下标上标都是 usize 类型,不能为负数。
下表是 Rust 主要控制流程的一个总结:
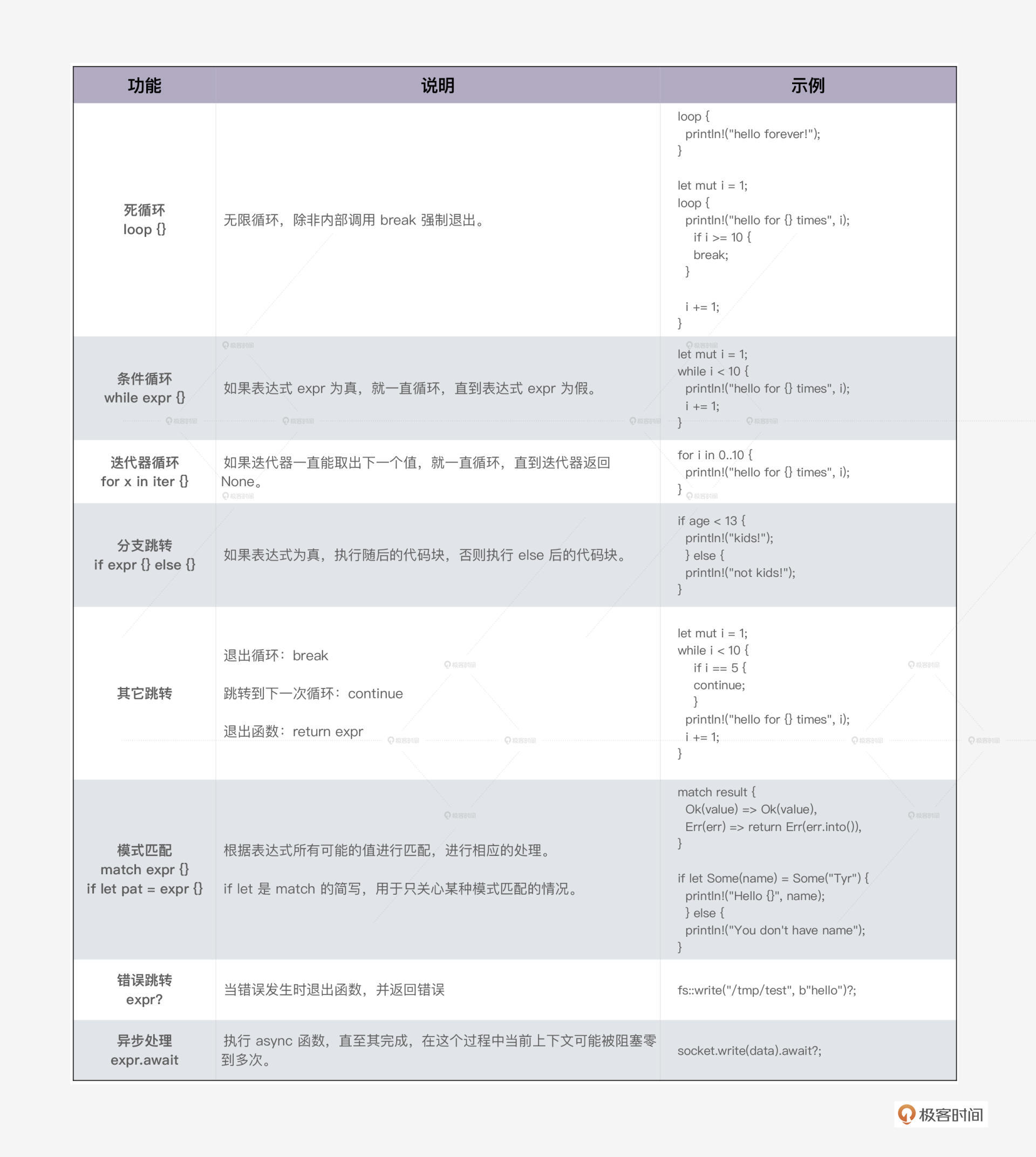
模式匹配
Rust 的模式匹配吸取了函数式编程语言的优点,强大优雅且效率很高。它可以用于 struct / enum 中匹配部分或者全部内容,比如上文中我们设计的数据结构 Event,可以这样匹配(代码):
fn process_event(event: &Event) {
match event {
Event::Join((uid, _tid)) => println!("user {:?} joined", uid),
Event::Leave((uid, tid)) => println!("user {:?} left {:?}", uid, tid),
Event::Message((_, _, msg)) => println!("broadcast: {}", msg),
}
}
从代码中我们可以看到,可以直接对 enum 内层的数据进行匹配并赋值,这比很多只支持简单模式匹配的语言,例如 JavaScript 、Python ,可以省出好几行代码。
除了使用 match 关键字做模式匹配外,我们还可以用 if let / while let 做简单的匹配,如果上面的代码我们只关心 Event::Message,可以这么写(代码):
fn process_message(event: &Event) {
if let Event::Message((_, _, msg)) = event {
println!("broadcast: {}", msg);
}
}
Rust 的模式匹配是一个很重要的语言特性,被广泛应用在状态机处理、消息处理和错误处理中,如果你之前使用的语言是 C / Java / Python / JavaScript ,没有强大的模式匹配支持,要好好练习这一块。
错误处理
Rust 没有沿用 C++/Java 等诸多前辈使用的异常处理方式,而是借鉴 Haskell,把错误封装在 Result<T, E> 类型中,同时提供了 ? 操作符来传播错误,方便开发。Result<T, E> 类型是一个泛型数据结构,T 代表成功执行返回的结果类型,E 代表错误类型。
今天开始的 scrape_url 项目,其实里面很多调用已经使用了 Result<T, E> 类型,这里我再展示一下代码,不过我们使用了 unwrap() 方法,只关心成功返回的结果,如果出错,整个程序会终止。
use std::fs;
fn main() {
let url = "https://www.rust-lang.org/";
let output = "rust.md";
println!("Fetching url: {}", url);
let body = reqwest::blocking::get(url).unwrap().text().unwrap();
println!("Converting html to markdown...");
let md = html2md::parse_html(&body);
fs::write(output, md.as_bytes()).unwrap();
println!("Converted markdown has been saved in {}.", output);
}
如果想让错误传播,可以把所有的 unwrap() 换成 ? 操作符,并让 main() 函数返回一个 Result<T, E>,如下所示:
use std::fs;
// main 函数现在返回一个 Result
fn main() -> Result<(), Box<dyn std::error::Error>> {
let url = "https://www.rust-lang.org/";
let output = "rust.md";
println!("Fetching url: {}", url);
let body = reqwest::blocking::get(url)?.text()?;
println!("Converting html to markdown...");
let md = html2md::parse_html(&body);
fs::write(output, md.as_bytes())?;
println!("Converted markdown has been saved in {}.", output);
Ok(())
}
关于错误处理我们先讲这么多,之后我们会单开一讲,对比其他语言,来详细学习 Rust 的错误处理。
Rust 项目的组织
当 Rust 代码规模越来越大时,我们就无法用单一文件承载代码了,需要多个文件甚至多个目录协同工作,这时我们可以用 mod 来组织代码。
具体做法是:在项目的入口文件 lib.rs / main.rs 里,用 mod 来声明要加载的其它代码文件。如果模块内容比较多,可以放在一个目录下,在该目录下放一个 mod.rs 引入该模块的其它文件。这个文件,和 Python 的 __init__.py 有异曲同工之妙。这样处理之后,就可以用 mod + 目录名引入这个模块了,如下图所示:
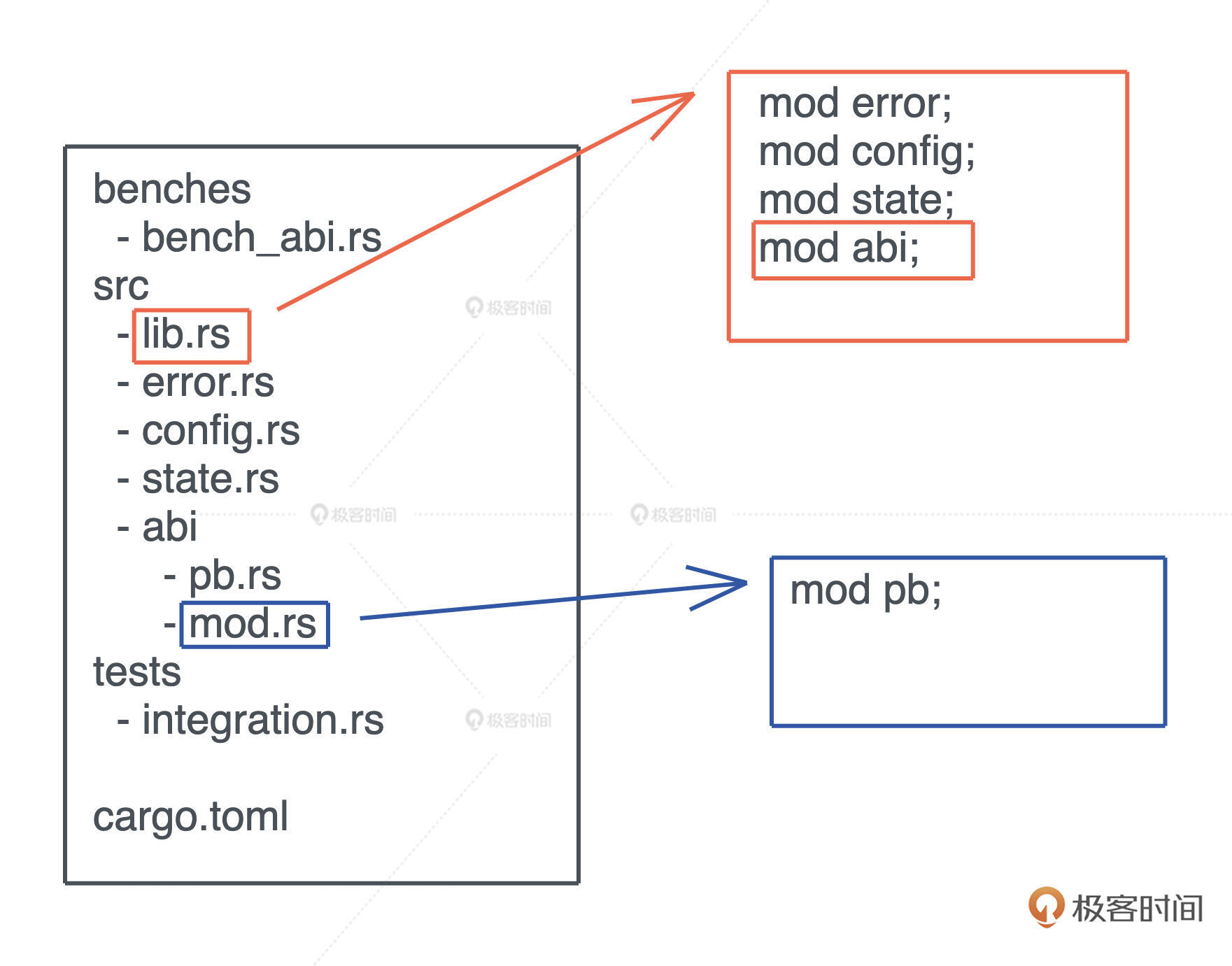
在 Rust 里,一个项目也被称为一个 crate。crate 可以是可执行项目,也可以是一个库,我们可以用 cargo new <name> -- lib 来创建一个库。当 crate 里的代码改变时,这个 crate 需要被重新编译。
在一个 crate 下,除了项目的源代码,单元测试和集成测试的代码也会放在 crate 里。
Rust 的单元测试一般放在和被测代码相同的文件中,使用条件编译 #[cfg(test)] 来确保测试代码只在测试环境下编译。以下是一个单元测试的例子:
#[cfg(test)]
mod tests {
#[test]
fn it_works() {
assert_eq!(2 + 2, 4);
}
}
集成测试一般放在 tests 目录下,和 src 平行。和单元测试不同,集成测试只能测试 crate 下的公开接口,编译时编译成单独的可执行文件。
在 crate 下,如果要运行测试用例,可以使用 cargo test。
当代码规模继续增长,把所有代码放在一个 crate 里就不是一个好主意了,因为任何代码的修改都会导致这个 crate 重新编译,这样效率不高。我们可以使用 workspace。
一个 workspace 可以包含一到多个 crates,当代码发生改变时,只有涉及的 crates 才需要重新编译。当我们要构建一个 workspace 时,需要先在某个目录下生成一个如图所示的 Cargo.toml,包含 workspace 里所有的 crates,然后可以 cargo new 生成对应的 crates:
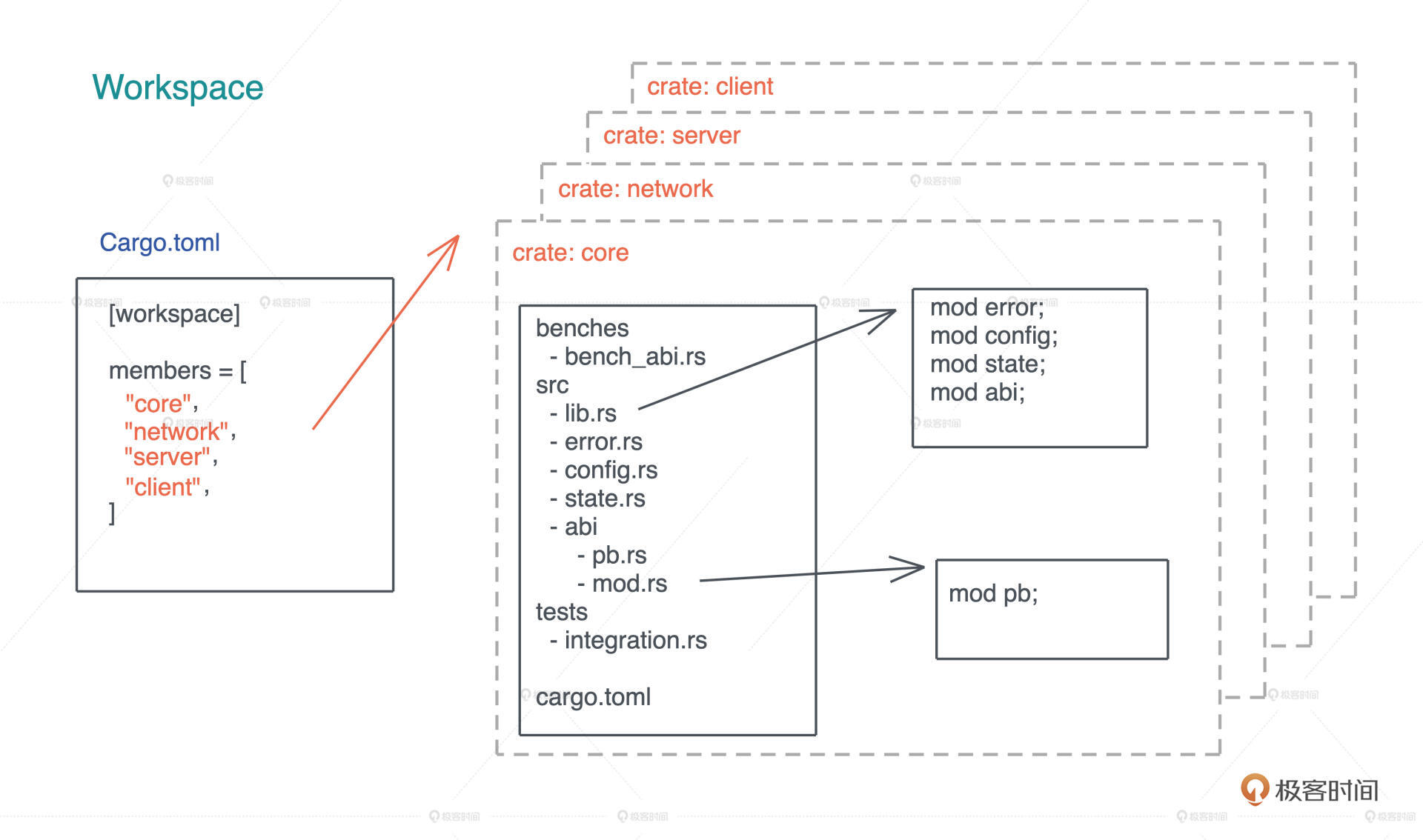
crate 和 workspace 还有一些更高级的用法,在后面遇到的时候会具体讲解。如果你有兴趣,也可以先阅读 Rust book 第 14 章了解更多的知识。
小结
我们简单梳理了 Rust 的基本概念。通过 let/let mut 定义变量、用 fn 定义函数、用 struct / enum 定义复杂的数据结构,也学习了 Rust 的基本的控制流程,了解了模式匹配如何运作,知道如何处理错误。
最后考虑到代码规模问题,介绍了如何使用 mod、crate 和 workspace 来组织 Rust 代码。我总结到图中你可以看看。
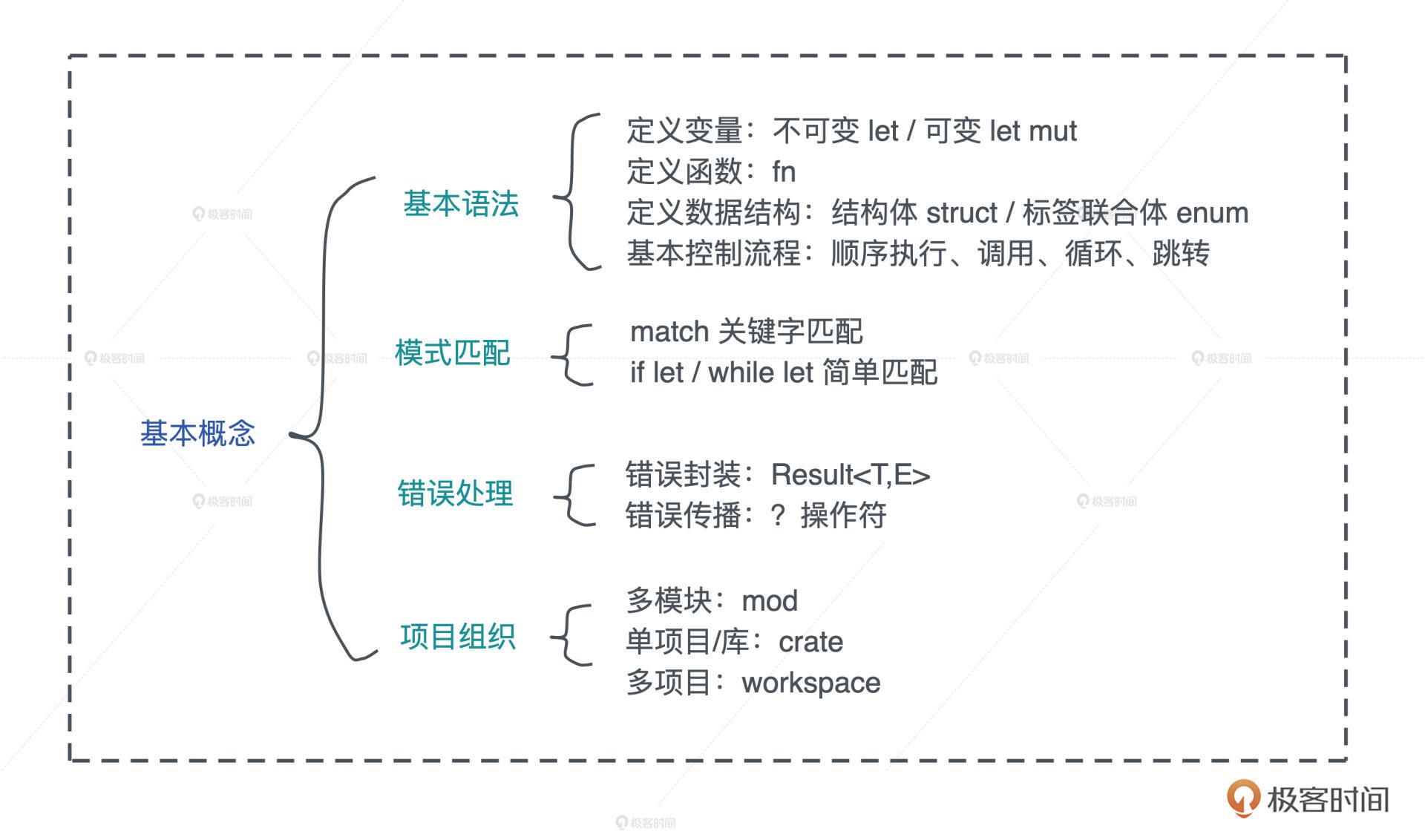
今天是让你对 Rust 形成非常基本的认识,能够开始尝试写一些简单的 Rust 项目。
你也许会惊奇,用 Rust 写类似于 scrape_url 的功能,竟然和 Python 这样的脚本语言的体验几乎一致,太简单了!
下一讲我们会继续写一写代码,从实用的小工具的编写中真实感受 Rust 的魅力。
思考题
1.在上面的斐波那契数列的代码中,你也许注意到计算数列中下一个数的代码在三个函数中不断重复。这不符合 DRY(Don’t Repeat Yourself)原则。你可以写一个函数把它抽取出来么?
2.在 scrape_url 的例子里,我们在代码中写死了要获取的 URL 和要输出的文件名,这太不灵活了。你能改进这个代码,从命令行参数中获取用户提供的信息来绑定 URL 和文件名么?类似这样:
cargo run -- https://www.rust-lang.org rust.md
提示一下,打印一下 std::env::args() 看看会发生什么?
for arg in std::env::args() {
println!("{}", arg);
}
欢迎在留言区分享你的思考。恭喜你完成了 Rust 学习的第三次打卡,我们下一讲见!
参考资料
- TOML
- static 关键字
- lazy_static
- unit 类型
- How to write tests
- More about cargo and crates.io
- Rust 支持声明宏(declarative macro)和过程宏(procedure macro),其中过程宏又包含三种方式:函数宏(function macro),派生宏(derive macro)和属性宏(attribute macro)。println! 是函数宏,是因为 Rust 是强类型语言,函数的类型需要在编译期敲定,而 println! 接受任意个数的参数,所以只能用宏来表达。
精选留言
2021-08-27 01:39:39
文中的"Rust 没有语句(statement),只有表达式(expression)"表述我认为是错误的,
我猜这里想表达的内容应该类似于《Rust程序设计语言中》的如下语句
"Rust 是一门基于表达式(expression-based)的语言,这是一个需要理解的(不同于其他语言)重要区别"
但是我的观点是:Rust既存在语句也存在表达式
我的依据为书中接下来的内容
"语句(Statements)是执行一些操作但不返回值的指令。表达式(Expressions)计算并产生一个值"
书中还附带了一个简单的例子,在这里我大体描述一下
`let y = 6;`中,6为一个表达式,它计算出的值是 6,`let y = 6;`做为一个整体是一条语句,他并不返回值,所以我们不能在Rust中这样书写`let x = (let y = 6);`
关于这个问题还有来自交流群内"Tai Huei"提供的截图中的文字作为依据
"Statements are instructions that do something, they do not return a value. Expressions evaluate to a value, they return that value"
"Rust is an expression-oriented language. This means that most things are expressions, and evaluate to some kind of value. However, there are also statements. -Steve Klabnik(member if the Rust core team)"
2021-08-27 09:58:01
export RUSTUP_UPDATE_ROOT=https://mirrors.sjtug.sjtu.edu.cn/rust-static/rustup
rust国内安装必备环境配置
2022-12-28 21:10:06
如果你是在windows环境下cargo run课程中的代码发现出现以下错误:
error: linking with `x86_64-w64-mingw32-gcc` failed: exit code: 1
网上解决方案是安装x86_64-pc-windows-msvc,但是你已经成功安装,却依然报错。
原因是除了安装msvc工具链以外,你还需要切换rust当前默认的工具链。
# 显示当前安装的工具链信息
rustup show
# 设置当前默认工具链
rustup default stable-x86_64-pc-windows-msvc
这样你就可以正常编译运行了。
2021-08-27 07:53:27
Copy 和 Clone 两者的区别和联系有:
Copy内部没有方法,Clone内部有两个方法。
Copy trait 是给编译器用的,告诉编译器这个类型默认采用 copy 语义,而不是 move 语义。Clone trait 是给程序员用的,我们必须手动调用clone方法,它才能发挥作用。
Copy trait不是你想实现就实现,它对类型是有要求的,有些类型就不可能 impl Copy。Clone trait 没有什么前提条件,任何类型都可以实现(unsized 类型除外)。
Copy trait规定了这个类型在执行变量绑定、函数参数传递、函数返回等场景下的操作方式。即这个类型在这种场景下,必然执行的是“简单内存拷贝”操作,这是由编译器保证的,程序员无法控制。Clone trait 里面的 clone 方法究竟会执行什么操作,则是取决于程序员自己写的逻辑。一般情况下,clone 方法应该执行一个“深拷贝”操作,但这不是强制的,如果你愿意,也可以在里面启动一个人工智能程序,都是有可能的。
链接:https://zhuanlan.zhihu.com/p/21730929
2021-09-03 12:19:16
let args = std::env::args().collect::<Vec<String>>();
if let [_path, url, output, ..] = args.as_slice() {
println!("url: {}, output: {}", url, output);
} else {
eprintln!("参数缺失");
}
2021-08-27 22:57:32
问题一:
重复的abc计算代码可以重构为如下函数:
```rust
fn next_fib(a: &mut i32, b: &mut i32) {
let c = *a + *b;
*a = *b;
*b = c;
}
```
以for in循环为例,用法如下:
```rust
fn fib_for(n: u8) {
let (mut a, mut b) = (1, 1);
for _i in 2..n {
next_fib(&mut a, &mut b);
println!("next val is {}", b);
}
}
```
问题二:
```rust
fn main() -> Result<(), Box<dyn std::error::Error>> {
let args: Vec<String> = env::args().collect();
if args.len() < 3 {
println!("Usage: url outpath");
return Ok(())
}
args.iter().for_each(|arg| {
println!("{}", arg);
});
let url = &args[1];
let output = &args[2];
println!("Fetching url: {}", url);
let body = &reqwest::blocking::get(url)?.text()?;
println!("Converting html to markdown...");
let md = html2md::parse_html(body);
fs::write(output, md.as_bytes())?;
println!("Converted markdown has been saved in {}.", output);
Ok(())
}
```
好歹是跑起来了……装了智能提示真不错,有better impl的建议 :)
2021-08-27 11:16:18
use structopt::StructOpt;
#[derive(StructOpt, Debug)]
#[structopt(name="scrape_url")]
struct Opt {
#[structopt(help="input url")]
pub url: String,
#[structopt(help="output file, stdout if not present")]
pub output: Option<String>,
}
fn main() {
let opt = Opt::from_args();
let url = opt.url;
let output = &opt.output.unwrap_or("rust.md".to_string());
println!("Fetching url: {}", url);
let body = reqwest::blocking::get(url).unwrap().text().unwrap();
println!("Converting html to markdown...");
let md = html2md::parse_html(&body);
fs::write(output, md.as_bytes()).unwrap();
println!("Converted markdown has been saved in {}.", output);
}
2021-08-27 14:02:22
2021-08-27 23:33:42
2. 在 scrape_url 的例子里,我们在代码中写死了要获取的 URL 和要输出的文件名,这太不灵活了。你能改进这个代码,从命令行参数中获取用户提供的信息来绑定 URL 和文件名么?类似这样:
```rust
use std::env;
use std::error;
use std::fs;
use std::process;
const NOT_ENOUGH_ARGS_CODE: i32 = 1;
const NOT_GET_HTTP_DATA_CODE: i32 = 2;
const CAN_NOT_CONVERT_MD_CODE: i32 = 3;
#[derive(Debug)]
struct Config {
url: String, //网址
output: String, //输出文件名
}
impl Config {
fn new(url: String, output: String) -> Config {
Config { url, output }
}
fn curl_url(&self) -> Result<String, Box<dyn error::Error>> {
println!("Fetching url: {}", self.url);
let body = reqwest::blocking::get(&self.url)?.text()?;
Ok(body)
}
fn convert_md_file(&self, body: String) -> Result<(), Box<dyn error::Error>> {
println!("Converting html to markdown...");
let md = html2md::parse_html(&body);
fs::write(&self.output, md.as_bytes())?;
println!("Converted markdown has been saved in {}.", self.output);
Ok(())
}
}
fn parse_args(args: &[String]) -> Result<Config, &str> {
if args.len() < 3 {
return Err("Not enough arguments!");
}
let url = args[1].clone();
let output = args[2].clone();
Ok(Config::new(url, output))
}
fn main() {
let args: Vec<String> = env::args().collect();
match parse_args(&args) {
Err(err) => {
println!("Error: {}", err);
process::exit(NOT_ENOUGH_ARGS_CODE);
}
Ok(cfg) => match cfg.curl_url() {
Err(err) => {
println!("Error: {}", err.to_string());
process::exit(NOT_GET_HTTP_DATA_CODE);
}
Ok(body) => {
let result = cfg.convert_md_file(body);
if result.is_err() {
println!("Error: Can NOT write data to {}", cfg.output);
process::exit(CAN_NOT_CONVERT_MD_CODE);
}
}
},
}
}
```
2021-09-08 23:23:34
1.首先把函数作为参数这里,例如a(1,b(2))这样的,那么和先调用b得到结果再填入a中有什么本质区别吗?我不理解的是,分开调用好像也没什么问题,有什么场景下需要函数作为参数这样调用的?
2.派生宏这里#[derive(Debug)],这个例子中实现的是什么功能不太理解?
3.println! 这里的语法多了一个感叹号,很多语言都有println,多了这个感叹号封装多了一些什么吗?看过一些资料也不太理解
多谢了
2021-08-27 11:17:59
2021-09-08 17:17:17
Compiling openssl-sys v0.9.66
error: failed to run custom build command for `openssl-sys v0.9.66`
折腾了大半天还是不行
2021-08-30 21:06:40
第二个在RPL中有个I/O Project的例子,用了 Config,不过感觉捕捉一下 Err 就可以了:
```rust
let args: Vec<String> = env::args().collect();
let (url, output) = parse_config(&args);
if let Err(e) = scrape_url::scrape(url, output) {
println!("{}", e);
}
```
课程真心不错~深入浅出不啰嗦~
2021-08-27 23:33:28
1) 定义一个loop_calc:
```rust
fn loop_calc(mut first_num: i32, mut second_num: i32, limit: u8) {
for _i in 2..limit {
let sum_num = first_num + second_num;
first_num = second_num;
second_num = sum_num;
println!("next val is {}", sum_num);
}
}
```
2) 在三个函数:fib_loop, fib_while, fib_for分别调用loop_calc(a, b, n)即可
完整版本:
```rust
fn loop_calc(mut first_num: i32, mut second_num: i32, limit: u8) {
for _i in 2..limit {
let sum_num = first_num + second_num;
first_num = second_num;
second_num = sum_num;
println!("next val is {}", sum_num);
}
}
fn fib_loop(n: u8) {
let a = 1;
let b = 1;
loop_calc(a, b, n);
}
fn fib_while(n: u8) {
let (a, b) = (1, 1);
loop_calc(a, b, n);
}
fn fib_for(n: u8) {
let (a, b) = (1, 1);
loop_calc(a, b, n);
}
fn main() {
let n = 10;
fib_loop(n);
fib_while(n);
fib_for(n);
}
```
2021-09-23 04:17:41
use std::fs;
fn print_usage_prompt_and_exit() {
println!("USAGE: cargo run -- url file.md");
std::process::exit(-1);
}
fn main() {
let args: Vec<String> = std::env::args().skip(1).collect();
if args.len() != 2 {
print_usage_prompt_and_exit();
}
let (url, output) = (&args[0], &args[1]);
println!("Fetching url: {}", url);
let body = reqwest::blocking::get(url).unwrap().text().unwrap();
println!("Converting html to markdown...");
let md = html2md::parse_html(&body);
fs::write(output, md.as_bytes()).unwrap();
println!("Converted markdown has been saved in {}.", output);
}
2021-08-27 07:55:25
2021-08-28 20:12:39
2021-08-27 11:35:45
let args: Vec<String> = env::args().collect();
let url = &args[1];
不查资料真是想不到怎样正确获取命令行参数
2022-01-13 23:02:18
use std::fs;
fn main() -> Result<(), Box<dyn std::error::Error>>{
// 先判判断参数长度是否足够
if env::args().len() < 2 {
println!("Not Enought Arguments");
}
// 转为数组进行操作
let args: Vec<String> = env::args().collect();
// 从第二个开始是参数
let url = &args[1];
let output = &args[2];
println!("fetching url:{}", url);
let body = reqwest::blocking::get(url)?.text()?;
println!("Converting html to markdown...");
let md = html2md::parse_html(&body);
fs::write(output, md.as_bytes())?;
println!("Converted markdown has been saved in {}.", output);
Ok(())
}
2022-01-13 02:02:27
不过我记得老版书的方法和课程中介绍的是一致的。
现在的大概是
一个 hello.rs 与 文件夹hello
使用hello的地方可以直接申明 mod hello