经过上一讲的学习,你是否已经在自己的电脑上搭建好了“最小化”的HTTP实验环境呢?
我相信你的答案一定是“Yes”,那么,让我们立刻开始“螺蛳壳里做道场”,在这个实验环境里看一下HTTP协议工作的全过程。
使用IP地址访问Web服务器
首先我们运行www目录下的“start”批处理程序,启动本机的OpenResty服务器,启动后可以用“list”批处理确认服务是否正常运行。
然后我们打开Wireshark,选择“HTTP TCP port(80)”过滤器,再鼠标双击“Npcap loopback Adapter”,开始抓取本机127.0.0.1地址上的网络数据。
第三步,在Chrome浏览器的地址栏里输入“http://127.0.0.1/”,再按下回车键,等欢迎页面显示出来后Wireshark里就会有捕获的数据包,如下图所示。
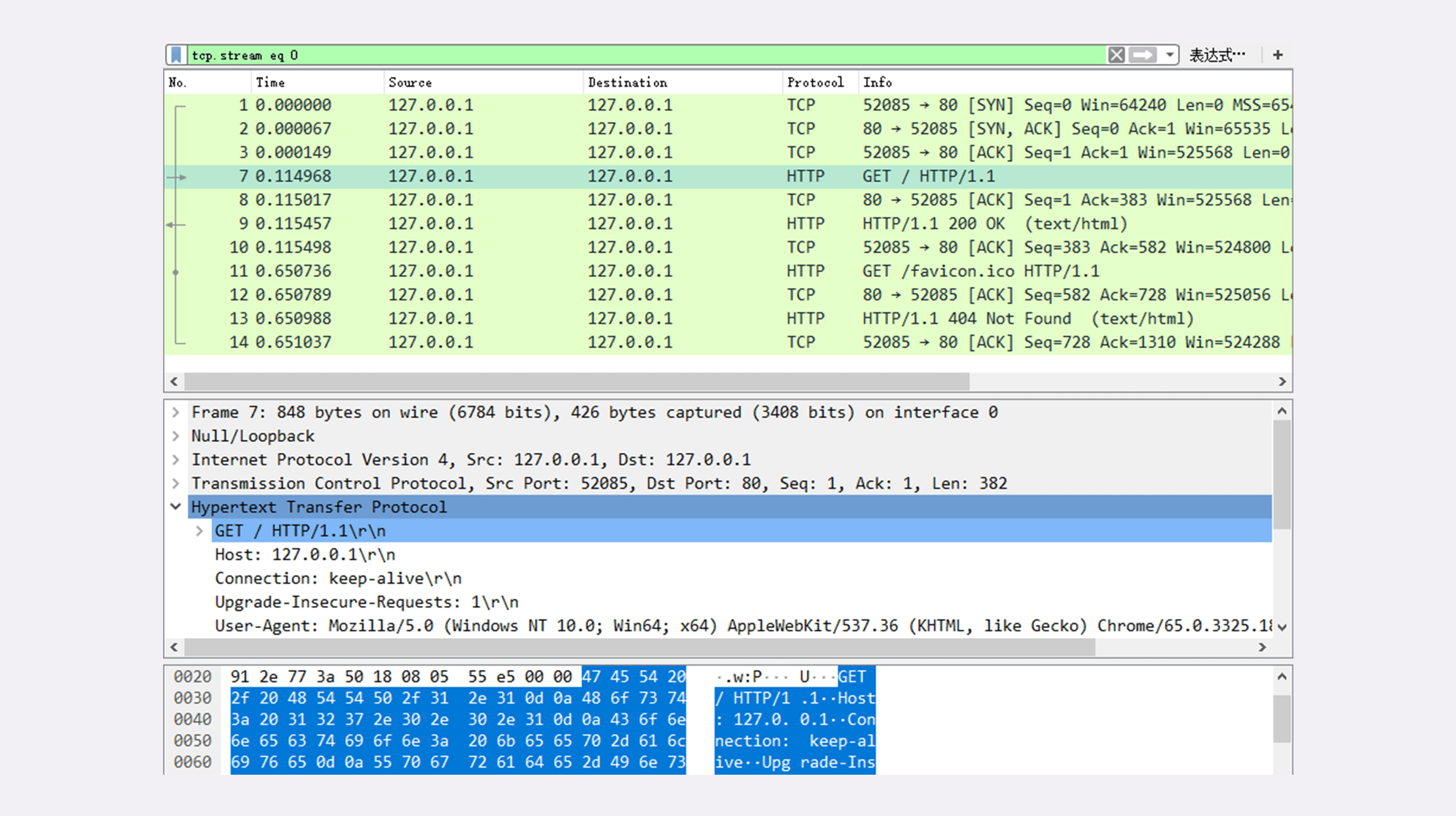
如果你还没有搭好实验环境,或者捕获与本文里的不一致也没关系。我把这次捕获的数据存成了pcap包,文件名是“08-1”,放到了GitHub上,你可以下载到本地后再用Wireshark打开,完全精确“重放”刚才的HTTP传输过程。
抓包分析
在Wireshark里你可以看到,这次一共抓到了11个包(这里用了滤包功能,滤掉了3个包,原本是14个包),耗时0.65秒,下面我们就来一起分析一下"键入网址按下回车"后数据传输的全过程。
通过前面“破冰篇”的讲解,你应该知道HTTP协议是运行在TCP/IP基础上的,依靠TCP/IP协议来实现数据的可靠传输。所以浏览器要用HTTP协议收发数据,首先要做的就是建立TCP连接。
因为我们在地址栏里直接输入了IP地址“127.0.0.1”,而Web服务器的默认端口是80,所以浏览器就要依照TCP协议的规范,使用“三次握手”建立与Web服务器的连接。
对应到Wireshark里,就是最开始的三个抓包,浏览器使用的端口是52085,服务器使用的端口是80,经过SYN、SYN/ACK、ACK的三个包之后,浏览器与服务器的TCP连接就建立起来了。
有了可靠的TCP连接通道后,HTTP协议就可以开始工作了。于是,浏览器按照HTTP协议规定的格式,通过TCP发送了一个“GET / HTTP/1.1”请求报文,也就是Wireshark里的第四个包。至于包的内容具体是什么现在先不用管,我们下一讲再说。
随后,Web服务器回复了第五个包,在TCP协议层面确认:“刚才的报文我已经收到了”,不过这个TCP包HTTP协议是看不见的。
Web服务器收到报文后在内部就要处理这个请求。同样也是依据HTTP协议的规定,解析报文,看看浏览器发送这个请求想要干什么。
它一看,原来是要求获取根目录下的默认文件,好吧,那我就从磁盘上把那个文件全读出来,再拼成符合HTTP格式的报文,发回去吧。这就是Wireshark里的第六个包“HTTP/1.1 200 OK”,底层走的还是TCP协议。
同样的,浏览器也要给服务器回复一个TCP的ACK确认,“你的响应报文收到了,多谢”,即第七个包。
这时浏览器就收到了响应数据,但里面是什么呢?所以也要解析报文。一看,服务器给我的是个HTML文件,好,那我就调用排版引擎、JavaScript引擎等等处理一下,然后在浏览器窗口里展现出了欢迎页面。
这之后还有两个来回,共四个包,重复了相同的步骤。这是浏览器自动请求了作为网站图标的“favicon.ico”文件,与我们输入的网址无关。但因为我们的实验环境没有这个文件,所以服务器在硬盘上找不到,返回了一个“404 Not Found”。
至此,“键入网址再按下回车”的全过程就结束了。
我为这个过程画了一个交互图,你可以对照着看一下。不过要提醒你,图里TCP关闭连接的“四次挥手”在抓包里没有出现,这是因为HTTP/1.1长连接特性,默认不会立即关闭连接。
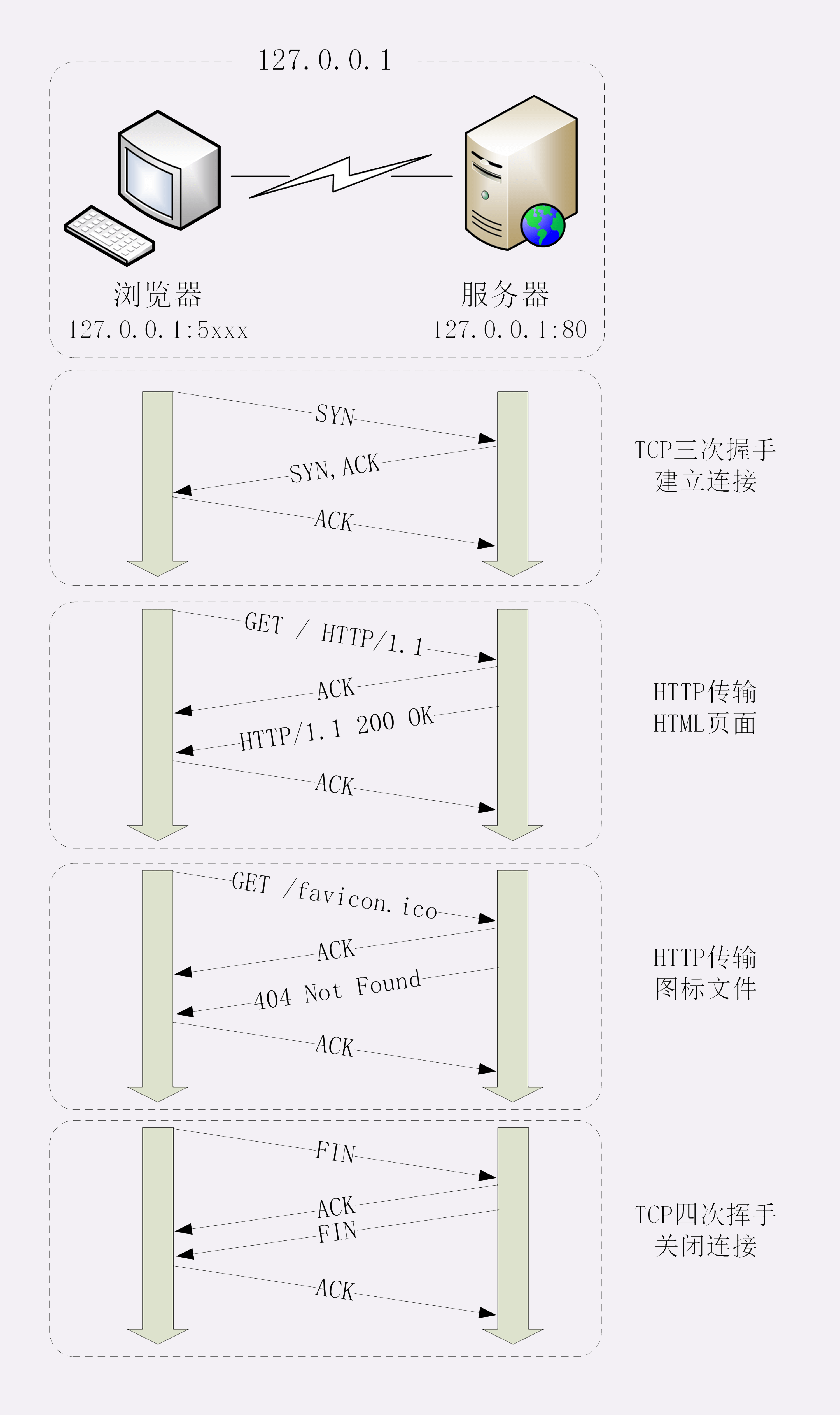
再简要叙述一下这次最简单的浏览器HTTP请求过程:
- 浏览器从地址栏的输入中获得服务器的IP地址和端口号;
- 浏览器用TCP的三次握手与服务器建立连接;
- 浏览器向服务器发送拼好的报文;
- 服务器收到报文后处理请求,同样拼好报文再发给浏览器;
- 浏览器解析报文,渲染输出页面。
使用域名访问Web服务器
刚才我们是在浏览器地址栏里直接输入IP地址,但绝大多数情况下,我们是不知道服务器IP地址的,使用的是域名,那么改用域名后这个过程会有什么不同吗?
还是实际动手试一下吧,把地址栏的输入改成“http://www.chrono.com”,重复Wireshark抓包过程,你会发现,好像没有什么不同,浏览器上同样显示出了欢迎界面,抓到的包也同样是11个:先是三次握手,然后是两次HTTP传输。
这里就出现了一个问题:浏览器是如何从网址里知道“www.chrono.com”的IP地址就是“127.0.0.1”的呢?
还记得我们之前讲过的DNS知识吗?浏览器看到了网址里的“www.chrono.com”,发现它不是数字形式的IP地址,那就肯定是域名了,于是就会发起域名解析动作,通过访问一系列的域名解析服务器,试图把这个域名翻译成TCP/IP协议里的IP地址。
不过因为域名解析的全过程实在是太复杂了,如果每一个域名都要大费周折地去网上查一下,那我们上网肯定会慢得受不了。
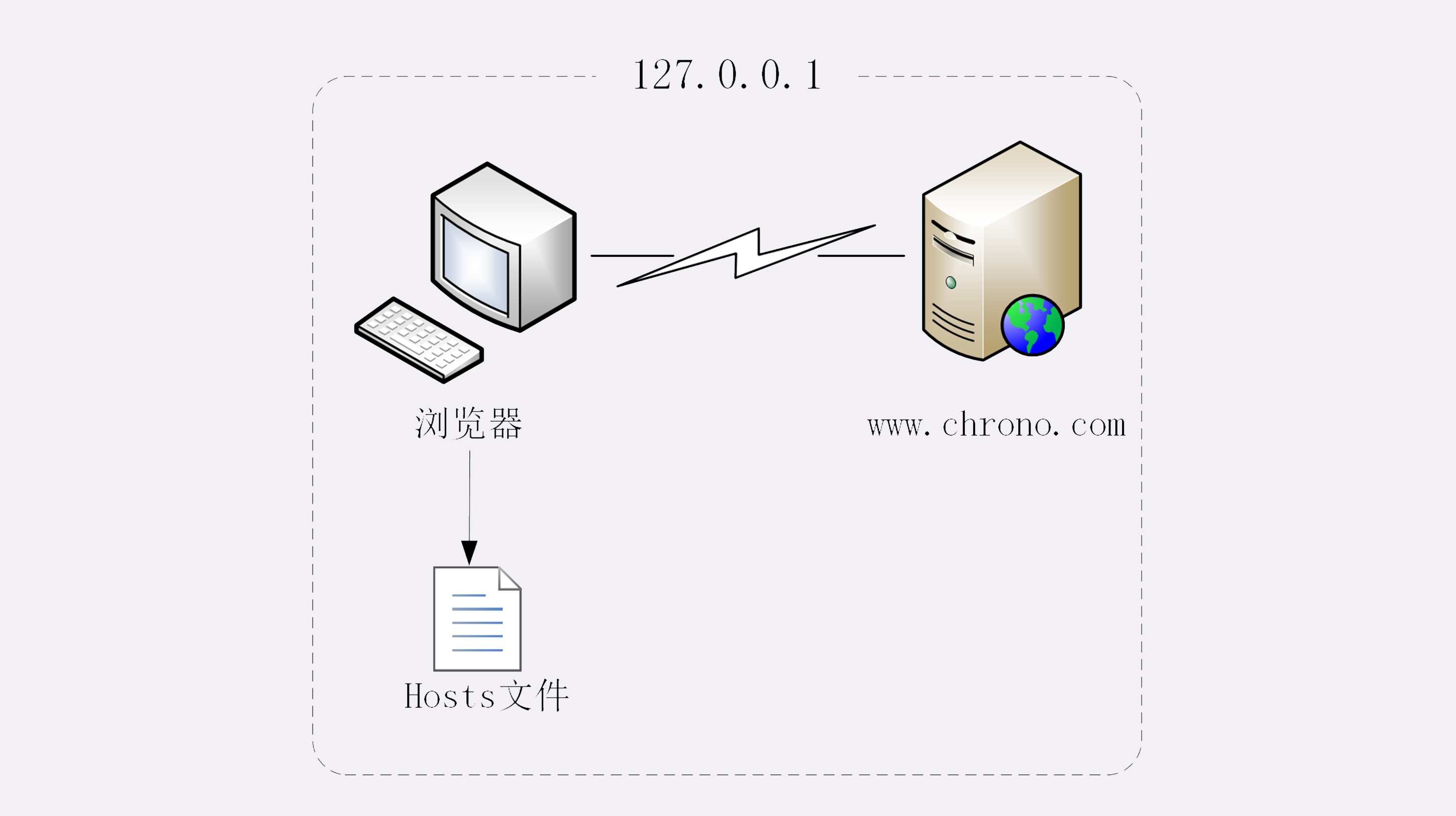
所以,在域名解析的过程中会有多级的缓存,浏览器首先看一下自己的缓存里有没有,如果没有就向操作系统的缓存要,还没有就检查本机域名解析文件hosts,也就是上一讲中我们修改的“C:\WINDOWS\system32\drivers\etc\hosts”。
刚好,里面有一行映射关系“127.0.0.1 www.chrono.com”,于是浏览器就知道了域名对应的IP地址,就可以愉快地建立TCP连接发送HTTP请求了。
我把这个过程也画出了一张图,但省略了TCP/IP协议的交互部分,里面的浏览器多出了一个访问hosts文件的动作,也就是本机的DNS解析。
真实的网络世界
通过上面两个在“最小化”环境里的实验,你是否已经对HTTP协议的工作流程有了基本的认识呢?
第一个实验是最简单的场景,只有两个角色:浏览器和服务器,浏览器可以直接用IP地址找到服务器,两者直接建立TCP连接后发送HTTP报文通信。
第二个实验在浏览器和服务器之外增加了一个DNS的角色,浏览器不知道服务器的IP地址,所以必须要借助DNS的域名解析功能得到服务器的IP地址,然后才能与服务器通信。
真实的互联网世界要比这两个场景要复杂的多,我利用下面的这张图来做一个详细的说明。
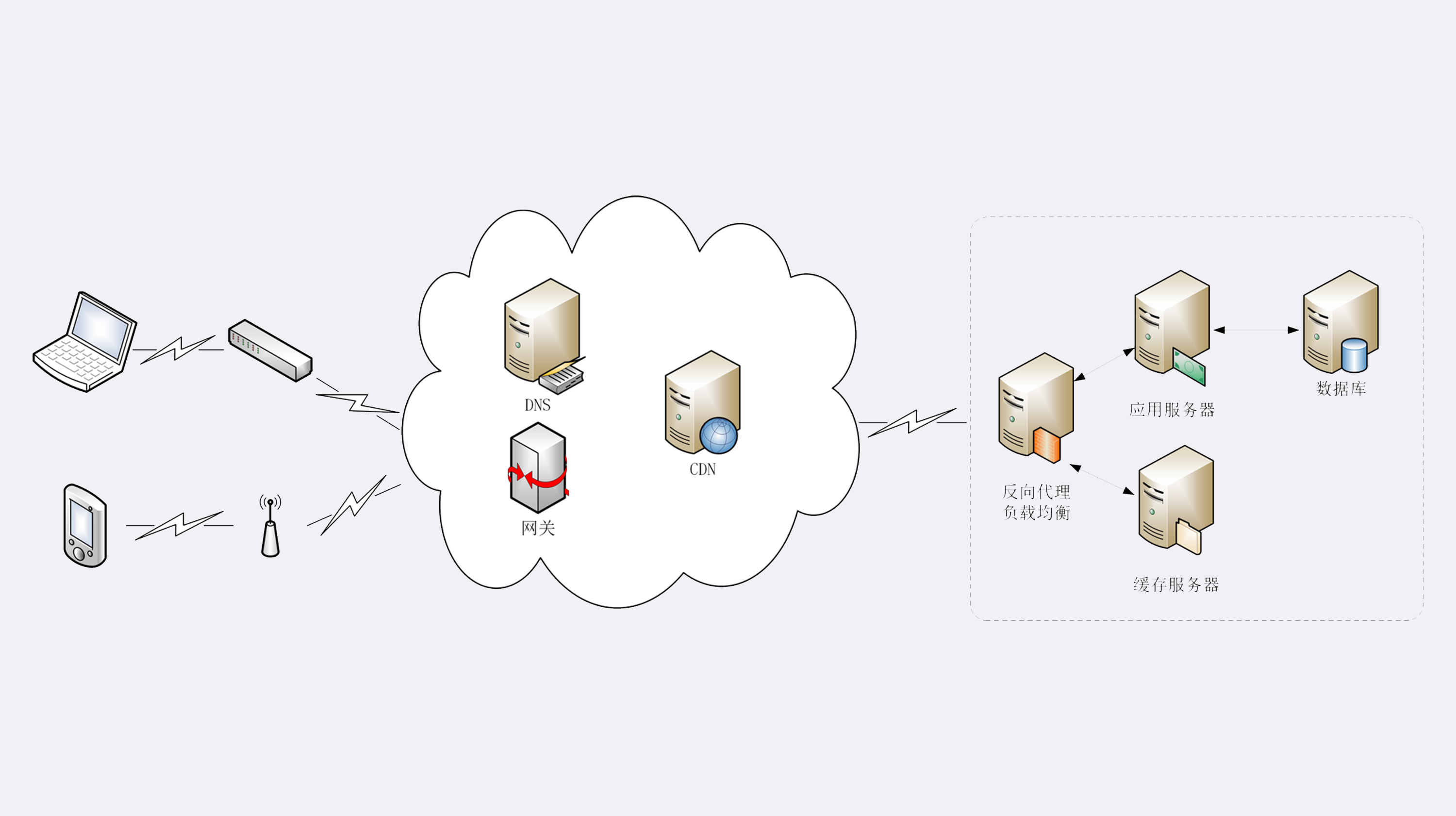
如果你用的是电脑台式机,那么你可能会使用带水晶头的双绞线连上网口,由交换机接入固定网络。如果你用的是手机、平板电脑,那么你可能会通过蜂窝网络、WiFi,由电信基站、无线热点接入移动网络。
接入网络的同时,网络运行商会给你的设备分配一个IP地址,这个地址可能是静态分配的,也可能是动态分配的。静态IP就始终不变,而动态IP可能你下次上网就变了。
假设你要访问的是Apple网站,显然你是不知道它的真实IP地址的,在浏览器里只能使用域名“www.apple.com”访问,那么接下来要做的必然是域名解析。这就要用DNS协议开始从操作系统、本地DNS、根DNS、顶级DNS、权威DNS的层层解析,当然这中间有缓存,可能不会费太多时间就能拿到结果。
别忘了互联网上还有另外一个重要的角色CDN,它也会在DNS的解析过程中“插上一脚”。DNS解析可能会给出CDN服务器的IP地址,这样你拿到的就会是CDN服务器而不是目标网站的实际地址。
因为CDN会缓存网站的大部分资源,比如图片、CSS样式表,所以有的HTTP请求就不需要再发到Apple,CDN就可以直接响应你的请求,把数据发给你。
由PHP、Java等后台服务动态生成的页面属于“动态资源”,CDN无法缓存,只能从目标网站获取。于是你发出的HTTP请求就要开始在互联网上的“漫长跋涉”,经过无数的路由器、网关、代理,最后到达目的地。
目标网站的服务器对外表现的是一个IP地址,但为了能够扛住高并发,在内部也是一套复杂的架构。通常在入口是负载均衡设备,例如四层的LVS或者七层的Nginx,在后面是许多的服务器,构成一个更强更稳定的集群。
负载均衡设备会先访问系统里的缓存服务器,通常有memory级缓存Redis和disk级缓存Varnish,它们的作用与CDN类似,不过是工作在内部网络里,把最频繁访问的数据缓存几秒钟或几分钟,减轻后端应用服务器的压力。
如果缓存服务器里也没有,那么负载均衡设备就要把请求转发给应用服务器了。这里就是各种开发框架大显神通的地方了,例如Java的Tomcat/Netty/Jetty,Python的Django,还有PHP、Node.js、Golang等等。它们又会再访问后面的MySQL、PostgreSQL、MongoDB等数据库服务,实现用户登录、商品查询、购物下单、扣款支付等业务操作,然后把执行的结果返回给负载均衡设备,同时也可能给缓存服务器里也放一份。
应用服务器的输出到了负载均衡设备这里,请求的处理就算是完成了,就要按照原路再走回去,还是要经过许多的路由器、网关、代理。如果这个资源允许缓存,那么经过CDN的时候它也会做缓存,这样下次同样的请求就不会到达源站了。
最后网站的响应数据回到了你的设备,它可能是HTML、JSON、图片或者其他格式的数据,需要由浏览器解析处理才能显示出来,如果数据里面还有超链接,指向别的资源,那么就又要重走一遍整个流程,直到所有的资源都下载完。
小结
今天我们在本机的环境里做了两个简单的实验,学习了HTTP协议请求-应答的全过程,在这里做一个小结。
- HTTP协议基于底层的TCP/IP协议,所以必须要用IP地址建立连接;
- 如果不知道IP地址,就要用DNS协议去解析得到IP地址,否则就会连接失败;
- 建立TCP连接后会顺序收发数据,请求方和应答方都必须依据HTTP规范构建和解析报文;
- 为了减少响应时间,整个过程中的每一个环节都会有缓存,能够实现“短路”操作;
- 虽然现实中的HTTP传输过程非常复杂,但理论上仍然可以简化成实验里的“两点”模型。
课下作业
- 你能试着解释一下在浏览器里点击页面链接后发生了哪些事情吗?
- 这一节课里讲的都是正常的请求处理流程,如果是一个不存在的域名,那么浏览器的工作流程会是怎么样的呢?
欢迎你把自己的答案写在留言区,与我和其他同学一起讨论。如果你觉得有所收获,也欢迎把文章分享给你的朋友。

精选留言
2019-06-14 10:02:35
2019-08-06 19:16:25
DNS域名解析不需要发请求,建立连接吗?本地缓存的dns除外。
比如我第一次访问一个域名abc.com,那这第一次不是需要从dns服务器上拿真正的IP吗,去拿IP的这个过程不是应该也是一个请求吗?这个请求又是什么请求呢?
2019-06-14 08:35:59
1. 浏览器判断这个链接是要在当前页面打开还是新开标签页,然后走一遍本文中的访问过程:拿到ip地址和端口号,建立tcp/ip链接,发送请求报文,接收服务器返回并渲染。
2. 先查浏览器缓存,然后是系统缓存->hosts文件->局域网域名服务器->广域网域名服务器->顶级域名服务器->根域名服务器。这个时间通常要很久,最终找不到以后,返回一个报错页面,chrome是ERR_CONNECTION_ABORTED
2019-06-14 21:33:31
2019-06-17 20:48:18
2、通过中间各种路由器的转发,找到了最终服务器,进行tcp三次握手,数据请求,请求分两种一种是uri请求,一种是浏览器咸吃萝卜淡操心的请求网站图标ico的资源请求,然后服务端收到请求后进行请求分析,最终返回http报文,再通过tcp这个连接隧道返回给用户端,用户端收到后再告诉服务端已经收到结果的信号(ack),然后客户端有一套解析规则,如果是html,可能还有额外的外部连接请求,是跟刚才的请求流程是同理的(假设是http1.1),只不过没有了tcp三次握手的过程,最终用户看到了百度的搜索页面。当然如果dns没解析成功,浏览器直接就报错了,不会继续请求接下来的资源
2019-06-14 08:25:23
我的理解是本地系统有可能有缓存,DNS解析前先查看本地有没有缓存,如果没有缓存,再进行本地DNS解析,本地DNS解析就是查找系统里面的hosts文件的对应关系。不知道这里理解的对不对。
还有一个疑问。
什么是权威DNS呢,我一般是在万网购买域名,然后用A记录解析到我的服务器,这个A记录提交到哪里保存了呢,这里的万网扮演的是什么角色呢?它和权威DNS有关系吗?
上次我提到了一个问题,就是域名和ip的对应关系,没接触这个课程以前,我的理解是一个域名只能解析到一个ip地址,但是一个ip地址可以绑定多个域名,就像一个人只有一个身份证号码,但是可以有多个名字,但是我在用ping命令 ping‘ baidu.com’ 时,发现 可以返回不同的ip,结合本课程前面的文章,我理解是百度自己的服务器本质是一台DNS服务器,用DNS做了负载均衡,当我访问baidu.com时,域名解析过程中,有一个环节是到达了百度的DNS服务器,然后DNS服务器根据负载均衡操作,再将我的请求转发给目标服务器。不知道理解的对不对,或者哪里有偏差。
2019-07-30 21:35:59
浏览器点击页面请求后,正常网络中都是域名,那么浏览器会先用DNS解析一下,拿到服务器的ip和端口,去请求服务器前会先找一下缓存,浏览器自己的缓存-操作系统缓存-本地缓存(Hosts),都没有的话就会到根域名服务器-顶级-权威,当然中间可能有类似CDN这样的代理,那它就可以取CDN中的服务器地址,总的来说,其实就是个“走近道”的过程,就近原则,在DNS不错的情况下,先从离自己近的查起,再一级一级往下。
2.这一节课里讲的都是正常的请求处理流程,如果是一个不存在的域名,那么浏览器的工作流程会是怎么样的呢?
如果是一个不存在的域名,那浏览器还是会从DNS那解析一下,发现,自己,操作系统,本地的缓存都没有,CDN里也没有,根域名,顶级域名,权威域名,非权威域名里
都没有,那它就放弃了,不会建立链接,返回错误码,可能是4××类的客户端请求错误。
2019-11-27 22:10:53
1.如果在TCP连接保持的情况下某一方突然断电了,没有机会进行TCP 四次挥手,会出现什么情况呢?
2.如果不主动关浏览器,TCP连接好像一直存在着,会有超时时间吗?中间是否会保活?
3.若server端负载较高,当它收到client的SYN包时,是否要过一段时间才会回应SYN,ACK?
2019-06-27 09:16:00
2020-06-08 22:27:10
2.如1中所说DNS解析顺序,当请求DNS服务器进行域名解析时,发现没有找到对应的ip,会导致解析失败,无法建立tcp/ip链接,导致浏览器建立连接时间过长,最终建立连接失败,浏览器停止建立连接动作。
2019-08-17 22:26:15
我在本地测试了一下,结果有点不解
1、浏览器上访问了一次127.0.0.1,发起了两次:三次握手,四次握手;但没有访问/favicon.ico;对应端口分别是52181->80、52182->80。
2、52181在四次挥手是服务端先发起了:[FIN,ACK],客户端:[ACK],[FIN,ACK],服务端:[ACK],和你画的四次挥手顺序不对,52182和52181四次挥手顺序保持一致。
2019-08-16 14:30:59
2019-08-06 22:08:34
2019-08-01 19:56:36
2019-07-13 11:43:54
2019-06-15 08:01:51
"这就要用 DNS 协议开始从操作系统、本地 DNS、根 DNS、顶级 DNS、权威 DNS 的层层解析"。
而我看前几天的内容总结的是,请求会在进入网络后先到达非权威DNS、权威DNS、顶级…、最后才是到达根DNS去解析,那么本文怎么是先从根DNS开始的呢?
2022-11-04 14:36:07
1. 浏览器输入url,判断是不是一个域名
2. 开始DNS解析动作
3. 查找浏览器缓存
4. 查找操作系统缓存
5. 查找本地hosts文件
6. 查找野生DNS服务器缓存
7. 查找根域名服务器
8. 查找顶级域名服务器
9. 查找权威域名服务器
10. 查找dns过程中可能会拿到cdn缓存资源
11. 如果以上都没有, 说明这个地址不存在, 不会建立连接, 不会走接下来的TCP请求, 如果以上过程查找到了, 那么会建立TCP连接
12. 客户端向服务端发送第一个数据包,表示要建立连接 (seq = 0)建立第一次握手
13. 服务端收到客户端请求发送来的第一个包,表示确认建立连接(seq = 0, ack = 1)建立第二次握手
14. 客户端收到服务端发送的第二个包,同时向服务端发送 (seq = 1, ack = 1)确认建立连接, 开始数据传输
15. 客户端向服务端请求资源, 服务端收到请求资源后先转发给负载均衡设备, 读取服务端缓存
16. 如果服务端缓存也没有, 负载均衡设备会将请求转发给服务器
17. 服务器端获取到返回结果 , 会将结果返回给负载均衡设备, 并且可能会往缓存服务器里放一份
18. 原路返回, 同时可能会对这次结果做cdn缓存
19. 客户端收到请求回来的资源, 进行渲染页面操作
2021-05-26 16:52:52
1.红色的RST/ACK的包,
2.三次握手之后立马发送了[TCP Window Update]
对于问题1,查到的资料说是RST是复位标识,异常关闭连接
问题2,就没有找到明确的答案,麻烦老师解答下 为什么三次握手之后又发送了一个[TCP Window Update] ?
2021-03-08 20:32:58
1. 页面链接是一个个URL,点击链接相当于在浏览器输入目标服务器的IP及端口后按下回车(有时候是域名及端口。端口http默认是80,https默认是443,这两个端口默认不写。)
2. 此时浏览器作为user agent发起http请求,这时候会先和目标服务器通过“三次握手”建立TCP连接
3. 建立连接后,服务器接收到浏览器的报文,解析浏览器发起的请求要访问什么资源。如果报文解析正确,知晓浏览器要访问的资源,则返回http返回码和所请求内容;如其他情况,返回其他http状态码进行告知。
4. 浏览器接收返回的信息,使用http模板引擎、JS、CSS等引擎将静态网页和资源渲染出来。
5. 如果是链接是带域名的,在建立TCP连接前,会进行域名解析的步骤:先访问本地缓存(浏览器缓存,然后是操作系统缓存、host文件)找不到则再逐级DNS(野生DNS服务器-根-顶级-权威)查找。域名如果是CDN的域名,可能先访问CDN的缓存资源,找不到再去源站。
作业2. 如果是一个不存在的域名,那么浏览器的工作流程会是怎么样的呢?
不存在的域名也会去解析,先执行域名解析的步骤:先访问本地缓存(浏览器缓存,然后是操作系统缓存、host文件)找不到则再逐级DNS(野生DNS服务器-根-顶级-权威),都执行完还是找不到就报错。
2021-01-09 15:59:30
favicon.ico问题,貌似是chrome偷摸自动发的一个http请求,源文件里没有,所以报404,再刷新就不请求了
304问题,刷新一次,用了浏览器缓存,所以报304
ctrl+f5强制刷新,可以看到200,404
2个tcp连接问题,还是favicon.ico的问题,chrome开了2个tcp连接,源端口号不同,注意区分
wireshark过滤问题,缺省的过滤弹性不够好,可以用下面2个过滤策略
看tcp包
ip.addr==127.0.0.1 and tcp
只看http包
ip.addr==127.0.0.1 and http
辅助http连接验证可以用netstat
netstat -ano | find "127.0.0.1:80"