做生意的人最喜欢开放的营商环境,也就是说,我的这家公司,只要符合国家的法律,到哪里做生意,都能受到公平的对待,这样就不用为了适配各个地方的规则煞费苦心,只要集中精力优化自己的服务就可以了。
作为Linux操作系统,何尝不是这样。如果下面的硬件环境千差万别,就会很难集中精力做出让用户易用的产品。毕竟天天适配不同的平台,就已经够头大了。x86架构就是这样一个开放的平台。今天我们就来解析一下它。
计算机的工作模式是什么样的?
还记得咱们攒电脑时买的那堆硬件吗?虽然你可以根据经验,把那些复杂的设备和连接线安装起来,但是你真的了解它们为什么要这么连接吗?
现在我就把硬件图和计算机的逻辑图对应起来,带你看看计算机的工作模式。
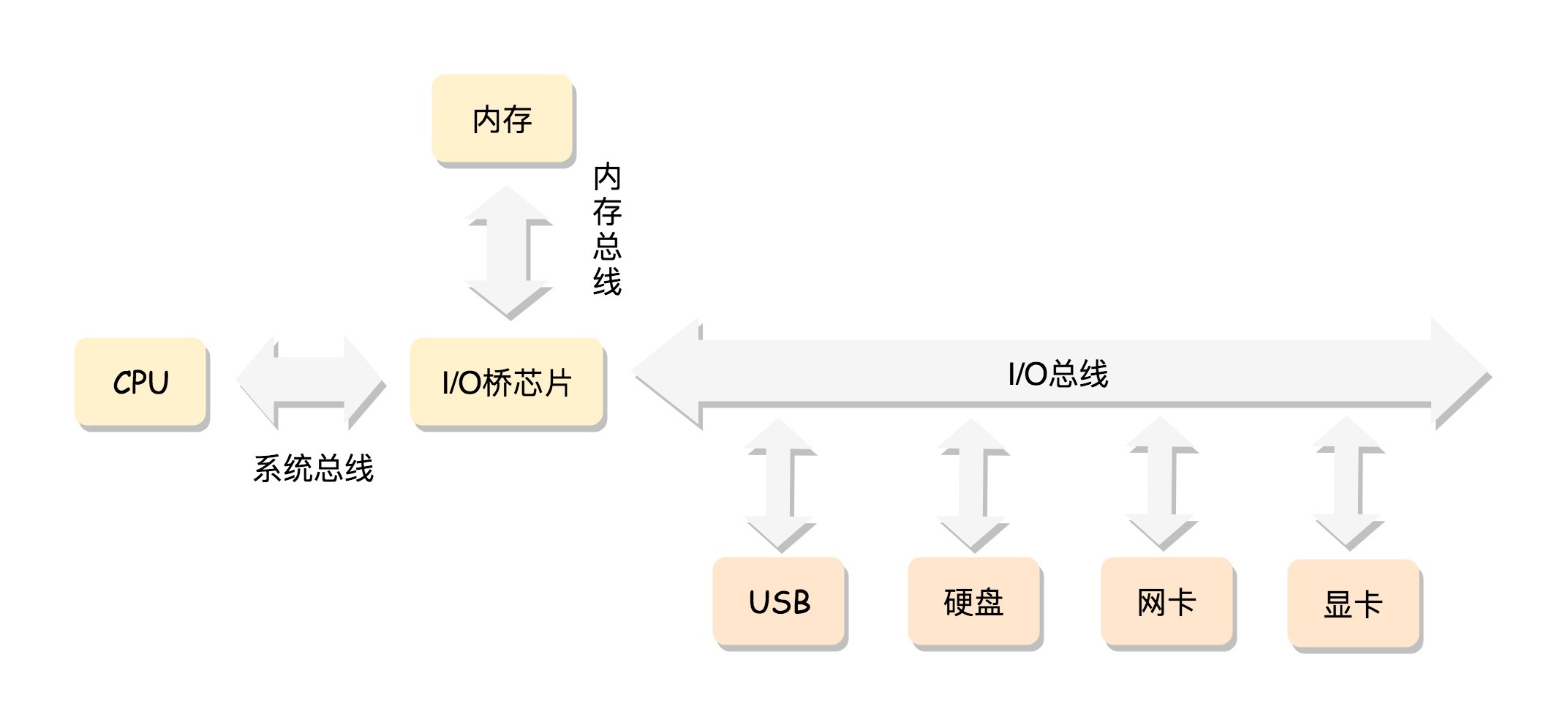
对于一个计算机来讲,最核心的就是CPU(Central Processing Unit,中央处理器)。这是这台计算机的大脑,所有的设备都围绕它展开。
对于公司来说,CPU是真正干活的,将来执行项目都要靠它。
CPU就相当于咱们公司的程序员,我们常说,二十一世纪最缺的是什么?是人才!所以,大量水平高、干活快的程序员,才是营商环境中最重要的部分。
CPU和其他设备连接,要靠一种叫做总线(Bus)的东西,其实就是主板上密密麻麻的集成电路,这些东西组成了CPU和其他设备的高速通道。
在这些设备中,最重要的是内存(Memory)。因为单靠CPU是没办法完成计算任务的,很多复杂的计算任务都需要将中间结果保存下来,然后基于中间结果进行进一步的计算。CPU本身没办法保存这么多中间结果,这就要依赖内存了。
内存就相当于办公室,我们要看看方不方便租到办公室,有没有什么创新科技园之类的。有了共享的、便宜的办公位,公司就有注册地了。
当然总线上还有一些其他设备,例如显卡会连接显示器、磁盘控制器会连接硬盘、USB控制器会连接键盘和鼠标等等。
CPU和内存是完成计算任务的核心组件,所以这里我们重点介绍一下CPU和内存是如何配合工作的。
CPU其实也不是单纯的一块,它包括三个部分,运算单元、数据单元和控制单元。
运算单元只管算,例如做加法、做位移等等。但是,它不知道应该算哪些数据,运算结果应该放在哪里。
运算单元计算的数据如果每次都要经过总线,到内存里面现拿,这样就太慢了,所以就有了数据单元。数据单元包括CPU内部的缓存和寄存器组,空间很小,但是速度飞快,可以暂时存放数据和运算结果。
有了放数据的地方,也有了算的地方,还需要有个指挥到底做什么运算的地方,这就是控制单元。控制单元是一个统一的指挥中心,它可以获得下一条指令,然后执行这条指令。这个指令会指导运算单元取出数据单元中的某几个数据,计算出个结果,然后放在数据单元的某个地方。

每个项目都有一个项目执行计划书,里面是一行行项目执行的指令,这些都是放在档案库里面的。每个进程都有一个程序放在硬盘上,是二进制的,再里面就是一行行的指令,会操作一些数据。
进程一旦运行,比如图中两个进程A和B,会有独立的内存空间,互相隔离,程序会分别加载到进程A和进程B的内存空间里面,形成各自的代码段。当然真实情况肯定比我说的要复杂的多,进程的内存虽然隔离但不连续,除了简单的区分代码段和数据段,还会分得更细。
程序运行的过程中要操作的数据和产生的计算结果,都会放在数据段里面。那CPU怎么执行这些程序,操作这些数据,产生一些结果,并写入回内存呢?
CPU的控制单元里面,有一个指令指针寄存器,它里面存放的是下一条指令在内存中的地址。控制单元会不停地将代码段的指令拿进来,先放入指令寄存器。
当前的指令分两部分,一部分是做什么操作,例如是加法还是位移;一部分是操作哪些数据。
要执行这条指令,就要把第一部分交给运算单元,第二部分交给数据单元。
数据单元根据数据的地址,从数据段里读到数据寄存器里,就可以参与运算了。运算单元做完运算,产生的结果会暂存在数据单元的数据寄存器里。最终,会有指令将数据写回内存中的数据段。
你可能会问,上面算来算去执行的都是进程A里的指令,那进程B呢?CPU里有两个寄存器,专门保存当前处理进程的代码段的起始地址,以及数据段的起始地址。这里面写的都是进程A,那当前执行的就是进程A的指令,等切换成进程B,就会执行B的指令了,这个过程叫作进程切换(Process Switch)。这是一个多任务系统的必备操作,我们后面有专门的章节讲这个内容,这里你先有个印象。
到这里,你会发现,CPU和内存来来回回传数据,靠的都是总线。其实总线上主要有两类数据,一个是地址数据,也就是我想拿内存中哪个位置的数据,这类总线叫地址总线(Address Bus);另一类是真正的数据,这类总线叫数据总线(Data Bus)。
所以说,总线其实有点像连接CPU和内存这两个设备的高速公路,说总线到底是多少位,就类似说高速公路有几个车道。但是这两种总线的位数意义是不同的。
地址总线的位数,决定了能访问的地址范围到底有多广。例如只有两位,那CPU就只能认00,01,10,11四个位置,超过四个位置,就区分不出来了。位数越多,能够访问的位置就越多,能管理的内存的范围也就越广。
而数据总线的位数,决定了一次能拿多少个数据进来。例如只有两位,那CPU一次只能从内存拿两位数。要想拿八位,就要拿四次。位数越多,一次拿的数据就越多,访问速度也就越快。
x86成为开放平台历史中的重要一笔
那CPU中总线的位数有没有个标准呢?如果没有标准,那操作系统作为软件就很难办了,因为软件层没办法实现通用的运算逻辑。这就像很多非标准的元器件一样,你烧你的电路板,我烧我的电路板,谁都不能用彼此的。
早期的IBM凭借大型机技术成为计算机市场的领头羊,直到后来个人计算机兴起,苹果公司诞生。但是,那个时候,无论是大型机还是个人计算机,每家的CPU架构都不一样。如果一直是这样,个人电脑、平板电脑、手机等等,都没办法形成统一的体系,就不会有我们现在通用的计算机了,更别提什么云计算、大数据这些统一的大平台了。
好在历史将x86平台推到了开放、统一、兼容的位置。我们继续来看IBM和x86的故事。
IBM开始做IBM PC时,一开始并没有让最牛的华生实验室去研发,而是交给另一个团队。一年时间,软硬件全部自研根本不可能完成,于是他们采用了英特尔的8088芯片作为CPU,使用微软的MS-DOS做操作系统。
谁能想到IBM PC卖得超级好,好到因为垄断市场而被起诉。IBM就在被逼的情况下公开了一些技术,使得后来无数IBM-PC兼容机公司的出现,也就有了后来占据市场的惠普、康柏、戴尔等等。
能够开放自己的技术是一件了不起的事。从技术和发展的层面来讲,它会使得一项技术大面积铺开,形成行业标准。就比如现在常用的Android手机,如果没有开放的Android系统,我们也没办法享受到这么多不同类型的手机。
对于当年的PC机来说,其实也是这样。英特尔的技术因此成为了行业的开放事实标准。由于这个系列开端于8086,因此称为x86架构。
后来英特尔的CPU数据总线和地址总线越来越宽,处理能力越来越强。但是一直不能忘记三点,一是标准,二是开放,三是兼容。因为要想如此大的一个软硬件生态都基于这个架构,符合它的标准,如果是封闭或者不兼容的,那谁都不答应。

从8086的原理说起
说完了x86的历史,我们再来看x86中最经典的一款处理器,8086处理器。虽然它已经很老了,但是咱们现在操作系统中的很多特性都和它有关,并且一直保持兼容。
我们把CPU里面的组件放大之后来看。你可以看我画的这幅图。

我们先来看数据单元。
为了暂存数据,8086处理器内部有8个16位的通用寄存器,也就是刚才说的CPU内部的数据单元,分别是AX、BX、CX、DX、SP、BP、SI、DI。这些寄存器主要用于在计算过程中暂存数据。
这些寄存器比较灵活,其中AX、BX、CX、DX可以分成两个8位的寄存器来使用,分别是AH、AL、BH、BL、CH、CL、DH、DL,其中H就是High(高位),L就是Low(低位)的意思。
这样,比较长的数据也能暂存,比较短的数据也能暂存。你可能会说16位并不长啊,你可别忘了,那是在计算机刚刚起步的时代。
接着我们来看控制单元。
IP寄存器就是指令指针寄存器(Instruction Pointer Register),指向代码段中下一条指令的位置。CPU会根据它来不断地将指令从内存的代码段中,加载到CPU的指令队列中,然后交给运算单元去执行。
如果需要切换进程呢?每个进程都分代码段和数据段,为了指向不同进程的地址空间,有四个16位的段寄存器,分别是CS、DS、SS、ES。
其中,CS就是代码段寄存器(Code Segment Register),通过它可以找到代码在内存中的位置;DS是数据段的寄存器,通过它可以找到数据在内存中的位置。
SS是栈寄存器(Stack Register)。栈是程序运行中一个特殊的数据结构,数据的存取只能从一端进行,秉承后进先出的原则,push就是入栈,pop就是出栈。

凡是与函数调用相关的操作,都与栈紧密相关。例如,A调用B,B调用C。当A调用B的时候,要执行B函数的逻辑,因而A运行的相关信息就会被push到栈里面。当B调用C的时候,同样,B运行相关信息会被push到栈里面,然后才运行C函数的逻辑。当C运行完毕的时候,先pop出来的是B,B就接着调用C之后的指令运行下去。B运行完了,再pop出来的就是A,A接着运行,直到结束。
如果运算中需要加载内存中的数据,需要通过DS找到内存中的数据,加载到通用寄存器中,应该如何加载呢?对于一个段,有一个起始的地址,而段内的具体位置,我们称为偏移量(Offset)。例如8号会议室的第三排,8号会议室就是起始地址,第三排就是偏移量。
在CS和DS中都存放着一个段的起始地址。代码段的偏移量在IP寄存器中,数据段的偏移量会放在通用寄存器中。
这时候问题来了,CS和DS都是16位的,也就是说,起始地址都是16位的,IP寄存器和通用寄存器都是16位的,偏移量也是16位的,但是8086的地址总线地址是20位。怎么凑够这20位呢?方法就是“起始地址*16+偏移量”,也就是把CS和DS中的值左移4位,变成20位的,加上16位的偏移量,这样就可以得到最终20位的数据地址。
从这个计算方式可以算出,无论真正的内存多么大,对于只有20位地址总线的8086来讲,能够区分出的地址也就2^20=1M,超过这个空间就访问不到了。这又是为啥呢?如果你想访问1M+X的地方,这个位置已经超过20位了,由于地址总线只有20位,在总线上超过20位的部分根本是发不出去的,所以发出去的还是X,最后还是会访问1M内的X的位置。
那一个段最大能有多大呢?因为偏移量只能是16位的,所以一个段最大的大小是2^16=64k。
是不是好可怜?对于8086CPU,最多只能访问1M的内存空间,还要分成多个段,每个段最多64K。尽管我们现在看来这不可想象得小,根本没法儿用,但是在当时其实够用了。
再来说32位处理器
当然,后来计算机的发展日新月异,内存越来越大,总线也越来越宽。在32位处理器中,有32根地址总线,可以访问2^32=4G的内存。使用原来的模式肯定不行了,但是又不能完全抛弃原来的模式,因为这个架构是开放的。
“开放”,意味着有大量其他公司的软硬件是基于这个架构来实现的,不能为所欲为,想怎么改怎么改,一定要和原来的架构兼容,而且要一直兼容,这样大家才愿意跟着你这个开放平台一直玩下去。如果你朝令夕改,那其他厂商就惨了。
如果是不开放的架构,那就没有问题。硬件、操作系统,甚至上面的软件都是自己搞的,你想怎么改就可以怎么改。
我们下面来说说,在开放架构的基础上,如何保持兼容呢?
首先,通用寄存器有扩展,可以将8个16位的扩展到8个32位的,但是依然可以保留16位的和8位的使用方式。你可能会问,为什么高16位不分成两个8位使用呢?因为这样就不兼容了呀!
其中,指向下一条指令的指令指针寄存器IP,就会扩展成32位的,同样也兼容16位的。

而改动比较大,有点不兼容的就是段寄存器(Segment Register)。
因为原来的模式其实有点不伦不类,因为它没有把16位当成一个段的起始地址,也没有按8位或者16位扩展的形式,而是根据当时的硬件,弄了一个不上不下的20位的地址。这样每次都要左移四位,也就意味着段的起始地址不能是任何一个地方,只是能整除16的地方。
如果新的段寄存器都改成32位的,明明4G的内存全部都能访问到,还左移不左移四位呢?
那我们索性就重新定义一把吧。CS、SS、DS、ES仍然是16位的,但是不再是段的起始地址。段的起始地址放在内存的某个地方。这个地方是一个表格,表格中的一项一项是段描述符(Segment Descriptor)。这里面才是真正的段的起始地址。而段寄存器里面保存的是在这个表格中的哪一项,称为选择子(Selector)。
这样,将一个从段寄存器直接拿到的段起始地址,就变成了先间接地从段寄存器找到表格中的一项,再从表格中的一项中拿到段起始地址。
这样段起始地址就会很灵活了。当然为了快速拿到段起始地址,段寄存器会从内存中拿到CPU的描述符高速缓存器中。
这样就不兼容了,咋办呢?好在后面这种模式灵活度非常高,可以保持将来一直兼容下去。前面的模式出现的时候,没想到自己能够成为一个标准,所以设计就没这么灵活。
因而到了32位的系统架构下,我们将前一种模式称为实模式(Real Pattern),后一种模式称为保护模式(Protected Pattern)。
当系统刚刚启动的时候,CPU是处于实模式的,这个时候和原来的模式是兼容的。也就是说,哪怕你买了32位的CPU,也支持在原来的模式下运行,只不过快了一点而已。
当需要更多内存的时候,你可以遵循一定的规则,进行一系列的操作,然后切换到保护模式,就能够用到32位CPU更强大的能力。
这也就是说,不能无缝兼容,但是通过切换模式兼容,也是可以接受的。
在接下来的几节,我们就来看一下,CPU如何从启动开始,逐渐从实模式变为保护模式的。
总结时刻
这一节,我们讲了x86架构。在以后的操作系统讲解中,我们也是主要基于x86架构进行讲解,只有了解了底层硬件的基本工作原理,将来才能理解操作系统的工作模式。
x86架构总体来说还是很复杂的,其中和操作系统交互比较密切的部分,我画了个图。在这个图中,建议你重点牢记这些寄存器的作用,以及段的工作模式,后面我们马上就能够用到了。

课堂练习
操作这些底层的寄存器往往需要使用汇编语言,操作系统的一些底层的模块也是用汇编语言写的,因而你需要简单回顾一些汇编语言中的一些简单的命令的作用。所以,今天给你留个练习题,简单了解一下这些命令。
mov, call, jmp, int, ret, add, or, xor, shl, shr, push, pop, inc, dec, sub, cmp。
欢迎留言和我分享你的疑惑和见解,也欢迎你收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习、进步。

精选留言
2019-04-08 09:37:22
call和ret :call调用子程序,子程序以ret结尾
jmp :无条件跳
int :中断指令
add a b : 加法,a=a+b
or :或运算
xor :异或运算
shl :算术左移
ahr :算术右移
push xxx :压xxx入栈
pop xxx: xxx出栈
inc: 加1
dec: 减1
sub a b : a=a-b
cmp: 减法比较,修改标志位
2019-04-08 15:12:35
2019-04-10 12:03:55
- 运算单元 不知道算哪些数据, 结果放哪
- 数据单元 包括 CPU 内部缓存和寄存器, 暂时存放数据和结果
- 控制单元 获取下一条指令, 指导运算单元取数据, 计算, 存放结果
- 进程包含代码段, 数据段等, 以下为 CPU 执行过程:
- 控制单元 通过指令指针寄存器(IP), 取下一条指令, 放入指令寄存器中
- 指令包括操作和目标数据
- 数据单元 根据控制单元的指令, 从数据段读数据到数据寄存器中
- 运算单元 开始计算, 结果暂时存放到数据寄存器
- 两个寄存器, 存当前进程代码段和数据段起始地址, 在进程间切换
- 总线包含两类数据: 地址总线和数据总线
---
- x86 开放, 统一, 兼容
- 数据单元 包含 8个 16位通用寄存器, 可分为 2个 8位使用
- 控制单元 包含 IP(指令指针寄存器) 以及 4个段寄存器 CS DS SS ES
- IP 存放指令偏移量
- 数据偏移量存放在通用寄存器中
- `段地址<<4 + 偏移量` 得到地址
---
- 32 位处理器
- 通用寄存器 从 8个 16位拓展为 8个 32位, 保留 16位和 8位使用方式
- IP 从 16位扩展为 32位, 保持兼容
- 段寄存器仍为 16位, 由段描述符(表格, 缓存到 CPU 中)存储段的起始地址, 由段寄存器选择其中一项
- 保证段地址灵活性与兼容性
---
- 16位为实模式, 32位为保护模式
- 刚开机为实模式, 需要更多内存切换到保护模式
2019-04-08 00:29:48
2019-04-08 17:26:24
问题1:程序编译成二进制代码的时候,包含有指令起始地址吗?若包含那么后续每一行指令的涉及到的指令地址是计算出来的? 或者说加载进程的程序的时候才会确定起始地址?很好奇这个指令的指针寄存器里的值是什么时候、怎么放进去的?
问题2: CPU两个寄存器处理保存当前进程代码段的起始地址,已经数据起始地址。切换进程时会将这两个寄存器里的值一并切换,那么同一个进程出现多线程的时候了?
问题3:数据总线拿数据的时候没有限制大小吗,若数据很大,数据单元里的数据寄存器放不下怎么办的?
2019-04-08 14:47:59
这句话感觉有点语义不通啊,能否详细解释下???
2019-04-08 17:14:06
2019-04-08 16:29:09
2019-04-09 10:14:05
2019-04-08 09:59:16
2019-04-10 17:29:52
2019-10-17 21:35:31
1. 实模式下, 地址总线最大可寻地址空间大小仍为1M
2. 实模式下, 虽然通用寄存器和 IP寄存器在32CPU里已经扩展成32位, 但仍然只使用低16位
3. 实模式下, CS,DS,SS,ES寄存器仍段起始地址, 而在保护模式下实际指向的是段描述符位置
4. 实模式下, 没有特权等级和访问边界校验
5. 实模式下, 是直接对物理地址进行寻址, 没有虚拟地址和分页
2019-04-08 07:37:43
求问老师,左移四位,如何理解?
2020-06-17 11:37:37
1.cpu的组成:
运算单元,数据单元,控制单元构成
运算单元负责程序代码段的运算;
数据单元由cpu内部缓存和寄存器组成,存储运算单元计算的需要的临时数据和运算结果;
控制单元控制运算单元执行哪条代码段指令,指导计算单元取数据、计算以及存放结果;
2.cpu如何执行程序、操作程序数据、产生结果并写回内存呢?
通过cpu控制单元中的指令指针寄存器(IP),不断取下一条内存代码段指令,放入指令寄存器。
指令分为两部分,一部分是指示操作类型(加,减等),一部分目标数据在数据段的地址;
要执行一条指令,就把操作交给运算单元,把对象数据地址交给数据单元。
数据单元根据控制单元指令,从内存中的数据段读数据到的寄存器,然后运算单元进行运算。
产生的结果暂存数据单元的寄存器,最后控制单元根据指令将数据写回内存中的数据段;
3.cpu进程切换
cpu有两个寄存器,存放当前进程代码段起始地址、数据段的起始地址,当前进程A就存放A的,切换到B就存的是B的;
4.总线包括数据总线和地址总线
5.x86 16位8086经典cpu,现在cpu大部分兼容继承它。
数据单元 包含8个16位通用寄存器(AX、BX、CX、DX、SP、BP、SI、DI),用于计算过程中暂存数据,前4个可分为高低两个8位使用。
控制单元 包含 IP(指令指针寄存器) 以及 4个16位段寄存器 CS DS SS ES;
IP 寄存器,存放指令偏移量,指向下一条指令位置。
CS 代码段寄存器,存代码段开始地址;DS是数据段寄存器,存数据段开始地址;
SS 是栈寄存器,栈是程序运行中特殊数据结构,先进后出,函数调用就是栈的结构。
CS DS存放各自开始地址,代码段偏移量在IP寄存器中,数据段偏移地址存放通用寄存器中;
8086地址总线20位,CS,DS都是16位,通过“起始地址 *16+ 偏移量”来支持
6.x86 32位cpu,可访问2^32=4G内存
通用寄存器 从 8个 16位拓展为 8个 32位, 保留 16位和 8位使用方式
IP 寄存器从 16位扩展为 32位, 保持兼容
变化最大的段寄存器,为兼容仍是16位,但不再是段起始地址,段起始地址在内存中以表格存在,
表格中是段描述符,这里面才是真正段其实地址,而段寄存器中保存选择子指明是哪个描述符。
为了加速拿到其实地址,段寄存器会从内存中拿到 CPU 的描述符到高速缓存器中。
7.实模式、保护模式
16位为实模式, 32位为保护模式;
刚开机为实模式,当运行需要更多内存和更多操作时候就是保护模式,通过切换模式实现cpu兼容
2019-04-08 07:24:35
2021-03-16 08:15:46
BH&BL=BX(base)基址寄存器
CH&CL=CX(count)计数寄存器
DH&DL=DX(data)数据寄存器
SP(Stack Pointer)堆栈指针寄存器
BP(Base Pointer)基址指针寄存器
SI(Source Pointer)源变址寄存器
DI(Destination Index)目的变址寄存器
IP(Instruction Pointer)指令指针寄存器
CS(Code Segment)代码段寄存器
DS(Data Segment)数据段寄存器
SS(Stack Segment)堆栈段寄存器
ES(Extra Segment)附加段寄存器
2019-04-11 08:40:41
2019-04-08 10:38:52
2019-04-08 18:35:54
MOV: load value. this instruction name is misnomer, resulting in some confusion (data is not movedbut copied), in other architectures the same instructions is usually named “LOAD” and/or “STORE”or something like that.One important thing: if you set the low 16-bit part of a 32-bit register in 32-bit mode, the high 16bits remains as they were. But if you modify the low 32-bit part of the register in 64-bit mode, thehigh 32 bits of the register will be cleared.Supposedly, it was done to simplify porting code to x86-64.
CALL:call another function:PUSH address_after_CALL_instruction; JMP label.
JMP: jump to another address. The opcode has ajump offset.
INT(M):INT x is analogous to PUSHF; CALL dword ptr [x*4]in 16-bit environment. It was widely used in MS-DOS, functioning as a syscall vector. The registers AX/BX/CX/DX/SI/DI were filled with the arguments and then the flow jumped to the address in the Interrupt Vector Table (located at thebeginning of the address space). It was popular because INT has a short opcode (2 bytes) and the program which needs some MS-DOS services is not bother to determine the address of the service’sentry point. The interrupt handler returns the control flow to caller using the IRET instruction.The most busy MS-DOS interrupt number was 0x21, serving a huge part of itsAPI. In the post-MS-DOS era, this instruction was still used as syscall both in Linux and Windows (6.3 onpage 750), but was later replaced by the SYSENTER or SYSCALL instructions.
RET: return from subroutine:POP tmp; JMP tmp.
In fact, RET is an assembly language macro, in Windows and *NIX environment it is translated into RETN (“return near”) or, in MS-DOS times, where the memory was addressed differently, into RETF (“return far”).
RET can have an operand. Then it works like this:
POP tmp; ADD ESP op1; JMP tmp.RETwith an operand usually ends functions in the stdcall calling convention.
2019-04-12 15:55:21