上一节课,我们做了一些理论知识的铺垫性讲解,讲到了两种开发模式,基于贫血模型的传统开发模式,以及基于充血模型的DDD开发模式。今天,我们正式进入实战环节,看如何分别用这两种开发模式,设计实现一个钱包系统。
话不多说,让我们正式开始今天的学习吧!
钱包业务背景介绍
很多具有支付、购买功能的应用(比如淘宝、滴滴出行、极客时间等)都支持钱包的功能。应用为每个用户开设一个系统内的虚拟钱包账户,支持用户充值、提现、支付、冻结、透支、转赠、查询账户余额、查询交易流水等操作。下图是一张典型的钱包功能界面,你可以直观地感受一下。
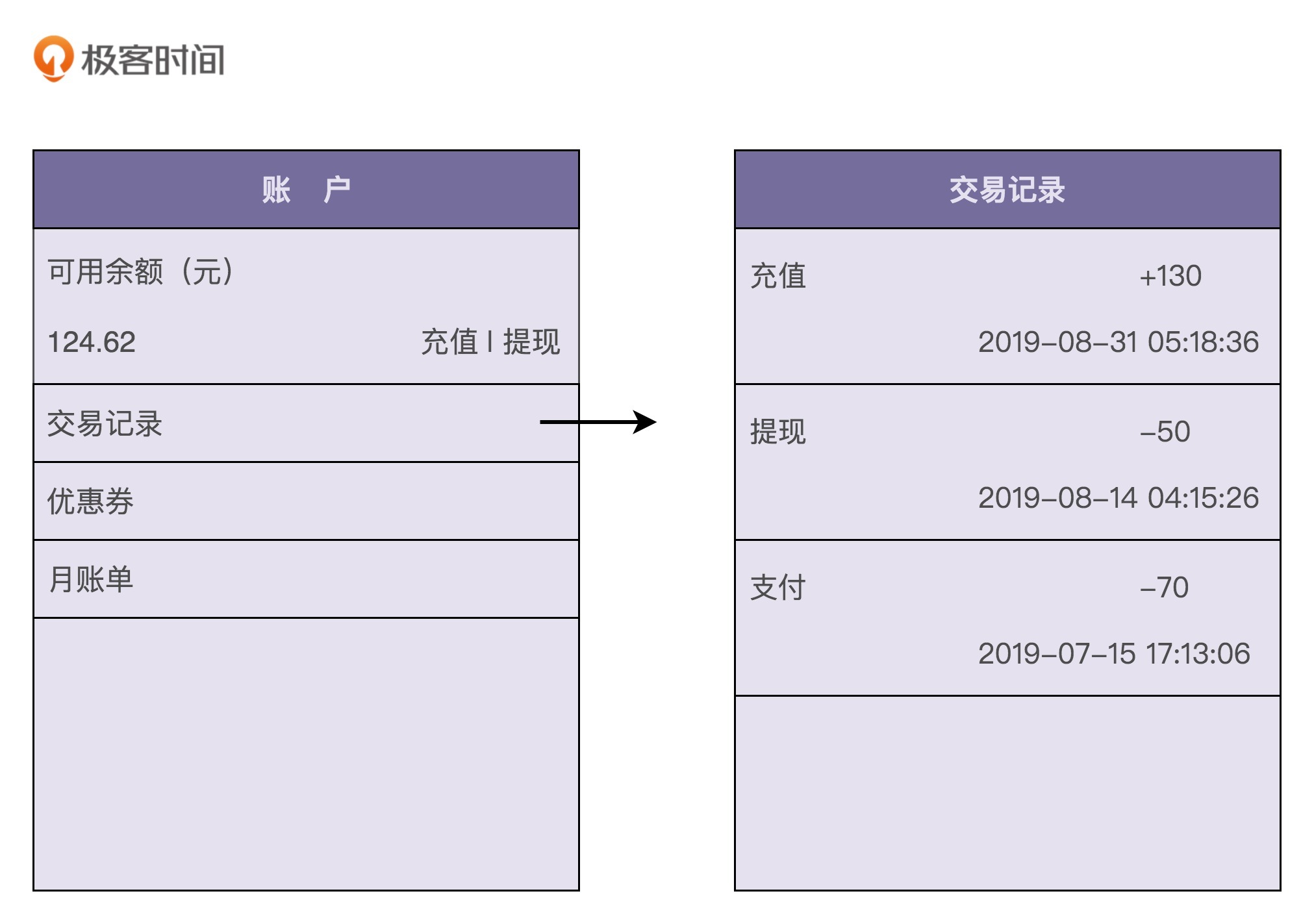
一般来讲,每个虚拟钱包账户都会对应用户的一个真实的支付账户,有可能是银行卡账户,也有可能是三方支付账户(比如支付宝、微信钱包)。为了方便后续的讲解,我们限定钱包暂时只支持充值、提现、支付、查询余额、查询交易流水这五个核心的功能,其他比如冻结、透支、转赠等不常用的功能,我们暂不考虑。为了让你理解这五个核心功能是如何工作的,接下来,我们来一块儿看下它们的业务实现流程。
1.充值
用户通过三方支付渠道,把自己银行卡账户内的钱,充值到虚拟钱包账号中。这整个过程,我们可以分解为三个主要的操作流程:第一个操作是从用户的银行卡账户转账到应用的公共银行卡账户;第二个操作是将用户的充值金额加到虚拟钱包余额上;第三个操作是记录刚刚这笔交易流水。

2.支付
用户用钱包内的余额,支付购买应用内的商品。实际上,支付的过程就是一个转账的过程,从用户的虚拟钱包账户划钱到商家的虚拟钱包账户上。除此之外,我们也需要记录这笔支付的交易流水信息。

3.提现
除了充值、支付之外,用户还可以将虚拟钱包中的余额,提现到自己的银行卡中。这个过程实际上就是扣减用户虚拟钱包中的余额,并且触发真正的银行转账操作,从应用的公共银行账户转钱到用户的银行账户。同样,我们也需要记录这笔提现的交易流水信息。

4.查询余额
查询余额功能比较简单,我们看一下虚拟钱包中的余额数字即可。
5.查询交易流水
查询交易流水也比较简单。我们只支持三种类型的交易流水:充值、支付、提现。在用户充值、支付、提现的时候,我们会记录相应的交易信息。在需要查询的时候,我们只需要将之前记录的交易流水,按照时间、类型等条件过滤之后,显示出来即可。
钱包系统的设计思路
根据刚刚讲的业务实现流程和数据流转图,我们可以把整个钱包系统的业务划分为两部分,其中一部分单纯跟应用内的虚拟钱包账户打交道,另一部分单纯跟银行账户打交道。我们基于这样一个业务划分,给系统解耦,将整个钱包系统拆分为两个子系统:虚拟钱包系统和三方支付系统。

为了能在有限的篇幅内,将今天的内容讲透彻,我们接来下只聚焦于虚拟钱包系统的设计与实现。对于三方支付系统以及整个钱包系统的设计与实现,我们不做讲解。你可以自己思考下。
现在我们来看下,如果要支持钱包的这五个核心功能,虚拟钱包系统需要对应实现哪些操作。我画了一张图,列出了这五个功能都会对应虚拟钱包的哪些操作。注意,交易流水的记录和查询,我暂时在图中打了个问号,那是因为这块比较特殊,我们待会再讲。

从图中我们可以看出,虚拟钱包系统要支持的操作非常简单,就是余额的加加减减。其中,充值、提现、查询余额三个功能,只涉及一个账户余额的加减操作,而支付功能涉及两个账户的余额加减操作:一个账户减余额,另一个账户加余额。
现在,我们再来看一下图中问号的那部分,也就是交易流水该如何记录和查询?我们先来看一下,交易流水都需要包含哪些信息。我觉得下面这几个信息是必须包含的。

从图中我们可以发现,交易流水的数据格式包含两个钱包账号,一个是入账钱包账号,一个是出账钱包账号。为什么要有两个账号信息呢?这主要是为了兼容支付这种涉及两个账户的交易类型。不过,对于充值、提现这两种交易类型来说,我们只需要记录一个钱包账户信息就够了。
整个虚拟钱包的设计思路到此讲完了。接下来,我们来看一下,如何分别用基于贫血模型的传统开发模式和基于充血模型的DDD开发模式,来实现这样一个虚拟钱包系统?
基于贫血模型的传统开发模式
实际上,如果你有一定Web项目的开发经验,并且听明白了我刚刚讲的设计思路,那对你来说,利用基于贫血模型的传统开发模式来实现这样一个系统,应该是一件挺简单的事情。不过,为了对比两种开发模式,我还是带你一块儿来实现一遍。
这是一个典型的Web后端项目的三层结构。其中,Controller和VO负责暴露接口,具体的代码实现如下所示。注意,Controller中,接口实现比较简单,主要就是调用Service的方法,所以,我省略了具体的代码实现。
public class VirtualWalletController {
// 通过构造函数或者IOC框架注入
private VirtualWalletService virtualWalletService;
public BigDecimal getBalance(Long walletId) { ... } //查询余额
public void debit(Long walletId, BigDecimal amount) { ... } //出账
public void credit(Long walletId, BigDecimal amount) { ... } //入账
public void transfer(Long fromWalletId, Long toWalletId, BigDecimal amount) { ...} //转账
//省略查询transaction的接口
}
Service和BO负责核心业务逻辑,Repository和Entity负责数据存取。Repository这一层的代码实现比较简单,不是我们讲解的重点,所以我也省略掉了。Service层的代码如下所示。注意,这里我省略了一些不重要的校验代码,比如,对amount是否小于0、钱包是否存在的校验等等。
public class VirtualWalletBo {//省略getter/setter/constructor方法
private Long id;
private Long createTime;
private BigDecimal balance;
}
public Enum TransactionType {
DEBIT,
CREDIT,
TRANSFER;
}
public class VirtualWalletService {
// 通过构造函数或者IOC框架注入
private VirtualWalletRepository walletRepo;
private VirtualWalletTransactionRepository transactionRepo;
public VirtualWalletBo getVirtualWallet(Long walletId) {
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
VirtualWalletBo walletBo = convert(walletEntity);
return walletBo;
}
public BigDecimal getBalance(Long walletId) {
return walletRepo.getBalance(walletId);
}
@Transactional
public void debit(Long walletId, BigDecimal amount) {
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
BigDecimal balance = walletEntity.getBalance();
if (balance.compareTo(amount) < 0) {
throw new NoSufficientBalanceException(...);
}
VirtualWalletTransactionEntity transactionEntity = new VirtualWalletTransactionEntity();
transactionEntity.setAmount(amount);
transactionEntity.setCreateTime(System.currentTimeMillis());
transactionEntity.setType(TransactionType.DEBIT);
transactionEntity.setFromWalletId(walletId);
transactionRepo.saveTransaction(transactionEntity);
walletRepo.updateBalance(walletId, balance.subtract(amount));
}
@Transactional
public void credit(Long walletId, BigDecimal amount) {
VirtualWalletTransactionEntity transactionEntity = new VirtualWalletTransactionEntity();
transactionEntity.setAmount(amount);
transactionEntity.setCreateTime(System.currentTimeMillis());
transactionEntity.setType(TransactionType.CREDIT);
transactionEntity.setFromWalletId(walletId);
transactionRepo.saveTransaction(transactionEntity);
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
BigDecimal balance = walletEntity.getBalance();
walletRepo.updateBalance(walletId, balance.add(amount));
}
@Transactional
public void transfer(Long fromWalletId, Long toWalletId, BigDecimal amount) {
VirtualWalletTransactionEntity transactionEntity = new VirtualWalletTransactionEntity();
transactionEntity.setAmount(amount);
transactionEntity.setCreateTime(System.currentTimeMillis());
transactionEntity.setType(TransactionType.TRANSFER);
transactionEntity.setFromWalletId(fromWalletId);
transactionEntity.setToWalletId(toWalletId);
transactionRepo.saveTransaction(transactionEntity);
debit(fromWalletId, amount);
credit(toWalletId, amount);
}
}
基于充血模型的DDD开发模式
刚刚讲了如何利用基于贫血模型的传统开发模式来实现虚拟钱包系统,现在,我们再来看一下,如何利用基于充血模型的DDD开发模式来实现这个系统?
在上一节课中,我们讲到,基于充血模型的DDD开发模式,跟基于贫血模型的传统开发模式的主要区别就在Service层,Controller层和Repository层的代码基本上相同。所以,我们重点看一下,Service层按照基于充血模型的DDD开发模式该如何来实现。
在这种开发模式下,我们把虚拟钱包VirtualWallet类设计成一个充血的Domain领域模型,并且将原来在Service类中的部分业务逻辑移动到VirtualWallet类中,让Service类的实现依赖VirtualWallet类。具体的代码实现如下所示:
public class VirtualWallet { // Domain领域模型(充血模型)
private Long id;
private Long createTime = System.currentTimeMillis();;
private BigDecimal balance = BigDecimal.ZERO;
public VirtualWallet(Long preAllocatedId) {
this.id = preAllocatedId;
}
public BigDecimal balance() {
return this.balance;
}
public void debit(BigDecimal amount) {
if (this.balance.compareTo(amount) < 0) {
throw new InsufficientBalanceException(...);
}
this.balance = this.balance.subtract(amount);
}
public void credit(BigDecimal amount) {
if (amount.compareTo(BigDecimal.ZERO) < 0) {
throw new InvalidAmountException(...);
}
this.balance = this.balance.add(amount);
}
}
public class VirtualWalletService {
// 通过构造函数或者IOC框架注入
private VirtualWalletRepository walletRepo;
private VirtualWalletTransactionRepository transactionRepo;
public VirtualWallet getVirtualWallet(Long walletId) {
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
VirtualWallet wallet = convert(walletEntity);
return wallet;
}
public BigDecimal getBalance(Long walletId) {
return walletRepo.getBalance(walletId);
}
@Transactional
public void debit(Long walletId, BigDecimal amount) {
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
VirtualWallet wallet = convert(walletEntity);
wallet.debit(amount);
VirtualWalletTransactionEntity transactionEntity = new VirtualWalletTransactionEntity();
transactionEntity.setAmount(amount);
transactionEntity.setCreateTime(System.currentTimeMillis());
transactionEntity.setType(TransactionType.DEBIT);
transactionEntity.setFromWalletId(walletId);
transactionRepo.saveTransaction(transactionEntity);
walletRepo.updateBalance(walletId, wallet.balance());
}
@Transactional
public void credit(Long walletId, BigDecimal amount) {
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
VirtualWallet wallet = convert(walletEntity);
wallet.credit(amount);
VirtualWalletTransactionEntity transactionEntity = new VirtualWalletTransactionEntity();
transactionEntity.setAmount(amount);
transactionEntity.setCreateTime(System.currentTimeMillis());
transactionEntity.setType(TransactionType.CREDIT);
transactionEntity.setFromWalletId(walletId);
transactionRepo.saveTransaction(transactionEntity);
walletRepo.updateBalance(walletId, wallet.balance());
}
@Transactional
public void transfer(Long fromWalletId, Long toWalletId, BigDecimal amount) {
//...跟基于贫血模型的传统开发模式的代码一样...
}
}
看了上面的代码,你可能会说,领域模型VirtualWallet类很单薄,包含的业务逻辑很简单。相对于原来的贫血模型的设计思路,这种充血模型的设计思路,貌似并没有太大优势。你说得没错!这也是大部分业务系统都使用基于贫血模型开发的原因。不过,如果虚拟钱包系统需要支持更复杂的业务逻辑,那充血模型的优势就显现出来了。比如,我们要支持透支一定额度和冻结部分余额的功能。这个时候,我们重新来看一下VirtualWallet类的实现代码。
public class VirtualWallet {
private Long id;
private Long createTime = System.currentTimeMillis();;
private BigDecimal balance = BigDecimal.ZERO;
private boolean isAllowedOverdraft = true;
private BigDecimal overdraftAmount = BigDecimal.ZERO;
private BigDecimal frozenAmount = BigDecimal.ZERO;
public VirtualWallet(Long preAllocatedId) {
this.id = preAllocatedId;
}
public void freeze(BigDecimal amount) { ... }
public void unfreeze(BigDecimal amount) { ...}
public void increaseOverdraftAmount(BigDecimal amount) { ... }
public void decreaseOverdraftAmount(BigDecimal amount) { ... }
public void closeOverdraft() { ... }
public void openOverdraft() { ... }
public BigDecimal balance() {
return this.balance;
}
public BigDecimal getAvaliableBalance() {
BigDecimal totalAvaliableBalance = this.balance.subtract(this.frozenAmount);
if (isAllowedOverdraft) {
totalAvaliableBalance += this.overdraftAmount;
}
return totalAvaliableBalance;
}
public void debit(BigDecimal amount) {
BigDecimal totalAvaliableBalance = getAvaliableBalance();
if (totoalAvaliableBalance.compareTo(amount) < 0) {
throw new InsufficientBalanceException(...);
}
this.balance = this.balance.subtract(amount);
}
public void credit(BigDecimal amount) {
if (amount.compareTo(BigDecimal.ZERO) < 0) {
throw new InvalidAmountException(...);
}
this.balance = this.balance.add(amount);
}
}
领域模型VirtualWallet类添加了简单的冻结和透支逻辑之后,功能看起来就丰富了很多,代码也没那么单薄了。如果功能继续演进,我们可以增加更加细化的冻结策略、透支策略、支持钱包账号(VirtualWallet id字段)自动生成的逻辑(不是通过构造函数经外部传入ID,而是通过分布式ID生成算法来自动生成ID)等等。VirtualWallet类的业务逻辑会变得越来越复杂,也就很值得设计成充血模型了。
辩证思考与灵活应用
对于虚拟钱包系统的设计与两种开发模式的代码实现,我想你应该有个比较清晰的了解了。不过,我觉得还有两个问题值得讨论一下。
第一个要讨论的问题是:在基于充血模型的DDD开发模式中,将业务逻辑移动到Domain中,Service类变得很薄,但在我们的代码设计与实现中,并没有完全将Service类去掉,这是为什么?或者说,Service类在这种情况下担当的职责是什么?哪些功能逻辑会放到Service类中?
区别于Domain的职责,Service类主要有下面这样几个职责。
1.Service类负责与Repository交流。在我的设计与代码实现中,VirtualWalletService类负责与Repository层打交道,调用Respository类的方法,获取数据库中的数据,转化成领域模型VirtualWallet,然后由领域模型VirtualWallet来完成业务逻辑,最后调用Repository类的方法,将数据存回数据库。
这里我再稍微解释一下,之所以让VirtualWalletService类与Repository打交道,而不是让领域模型VirtualWallet与Repository打交道,那是因为我们想保持领域模型的独立性,不与任何其他层的代码(Repository层的代码)或开发框架(比如Spring、MyBatis)耦合在一起,将流程性的代码逻辑(比如从DB中取数据、映射数据)与领域模型的业务逻辑解耦,让领域模型更加可复用。
2.Service类负责跨领域模型的业务聚合功能。VirtualWalletService类中的transfer()转账函数会涉及两个钱包的操作,因此这部分业务逻辑无法放到VirtualWallet类中,所以,我们暂且把转账业务放到VirtualWalletService类中了。当然,虽然功能演进,使得转账业务变得复杂起来之后,我们也可以将转账业务抽取出来,设计成一个独立的领域模型。
3.Service类负责一些非功能性及与三方系统交互的工作。比如幂等、事务、发邮件、发消息、记录日志、调用其他系统的RPC接口等,都可以放到Service类中。
第二个要讨论问题是:在基于充血模型的DDD开发模式中,尽管Service层被改造成了充血模型,但是Controller层和Repository层还是贫血模型,是否有必要也进行充血领域建模呢?
答案是没有必要。Controller层主要负责接口的暴露,Repository层主要负责与数据库打交道,这两层包含的业务逻辑并不多,前面我们也提到了,如果业务逻辑比较简单,就没必要做充血建模,即便设计成充血模型,类也非常单薄,看起来也很奇怪。
尽管这样的设计是一种面向过程的编程风格,但我们只要控制好面向过程编程风格的副作用,照样可以开发出优秀的软件。那这里的副作用怎么控制呢?
就拿Repository的Entity来说,即便它被设计成贫血模型,违反面向对象编程的封装特性,有被任意代码修改数据的风险,但Entity的生命周期是有限的。一般来讲,我们把它传递到Service层之后,就会转化成BO或者Domain来继续后面的业务逻辑。Entity的生命周期到此就结束了,所以也并不会被到处任意修改。
我们再来说说Controller层的VO。实际上VO是一种DTO(Data Transfer Object,数据传输对象)。它主要是作为接口的数据传输承载体,将数据发送给其他系统。从功能上来讲,它理应不包含业务逻辑、只包含数据。所以,我们将它设计成贫血模型也是比较合理的。
重点回顾
今天的内容到此就讲完了。我们一块来总结回顾一下,你应该重点掌握的知识点。
基于充血模型的DDD开发模式跟基于贫血模型的传统开发模式相比,主要区别在Service层。在基于充血模型的开发模式下,我们将部分原来在Service类中的业务逻辑移动到了一个充血的Domain领域模型中,让Service类的实现依赖这个Domain类。
在基于充血模型的DDD开发模式下,Service类并不会完全移除,而是负责一些不适合放在Domain类中的功能。比如,负责与Repository层打交道、跨领域模型的业务聚合功能、幂等事务等非功能性的工作。
基于充血模型的DDD开发模式跟基于贫血模型的传统开发模式相比,Controller层和Repository层的代码基本上相同。这是因为,Repository层的Entity生命周期有限,Controller层的VO只是单纯作为一种DTO。两部分的业务逻辑都不会太复杂。业务逻辑主要集中在Service层。所以,Repository层和Controller层继续沿用贫血模型的设计思路是没有问题的。
课堂讨论
这两节课中对于DDD的讲解,都是我的个人主观看法,你可能会有不同看法。
欢迎在留言区说一说你对DDD的看法。如果觉得有帮助,你也可以把这篇文章分享给你的朋友。
精选留言
2019-11-29 11:48:01
在维护性上来说,如果项目新进了开发人员,如果是贫血模型的service代码,无论代码如何清晰,注释如何完备,代码结构设计得如何优雅,都没有办法第一时间理解系统的核心业务逻辑,但是如果是充血模型,直接阅读充血模型的行为方法,起码能够很快理解70%左右的业务逻辑,因为充血模型可以说是业务的精准抽象,我想,这就是领域模型驱动能够达到"驱动"效果的由来吧
2019-11-29 06:22:59
DDD第一原则:将数据和操作结合。(贫血模型将数据和操作分离,违反OOP的原则。)
DDD第二原则:界限上下文。这是将“单一指责”应用于我们的领域模型。
DDD is nothing more than OOP applied to business models. DDD其实就是把OOP应用于业务模型。
实现:
1、使用通用语言(Ubiquitous Language):类、方法、字段的命名,要符合业务。使用业务语言命名,以后在和客户或者其他团队交流时能够更顺畅。
2、理解系统业务:例如做一个理财系统,要亲自去和银行卖理财产品的人聊聊或者买个理财产品之后,那些数据库中对你来说毫无意义的字段才变得有血有肉。
介绍一篇博客吧:DDD101 https://medium.com/the-coding-matrix/ddd-101-the-5-minute-tour-7a3037cf53b8
最后,是时候祭出大杀器了:《领域驱动设计》Eric Evans (反正我也没看)
2019-11-30 12:44:07
真正的业务逻辑都放在充血的领域对象中,与具体使用什么框架(比如Spring,MyBatis),具体使用什么数据库无关。这样有利于保护领域对象中的数据,比如钱包中的余额,当有入账和出账操作时,余额在领域对象中自动执行加减操作,而不是将余额暴露在Service中直接操作(这样很容易出错可能导致帐不平衡,余额应该封装保护起来),当然“余额自动增减”这只是一个简单的业务逻辑例子,业务逻辑越复杂就越应该封装到领域对象中。
1. Service层只是一个中间层,起到连接和组合作用。
用于支持领域模型层和Repository层的交互(连接作用),利用各种领域对象执行业务逻辑(组合作用)。
比如通过Repository查出数据,将数据转换为领域模型对象,利用领域模型对象执行业务逻辑(核心),然后调用Repository更新领域模型中的数据。
2. Service类还负责一些非功能性及与三方系统交互的工作。
比如幂等、事务、发邮件、发消息、记录日志、调用其他系统的 RPC 接口等。
不允许Service中的逻辑过于复杂,如果Service中的组合的业务逻辑过于复杂,我们就要将这业务逻辑抽取出一个新的领域对象进行封装,通过调用这个领域对象来进行这些复杂的操作。
由于controller和Repository层中本身没有什么业务逻辑,controller中的Vo对象实际上只是传输数据使用(数据从系统传输数据到外部调用方),Repository中的Entity本质上也只是传输数据(数据从数据库中传输数据到系统),所以用贫血模型不会带来副作用,是没有问题的。
2019-11-29 08:16:20
2019-11-30 13:22:57
从用户的虚拟钱包转90到商家虚拟钱包应该就完了,不应该再从应用公共银行卡再划钱到商家银行卡。如果要即时划转到商家银行卡,就要记得把商家的虚拟钱包减少90。
好像是这样吧?
2019-12-02 18:55:38
争哥说了很多交易流水表的设计,明明已经详细介绍了字段冗余的表1要明显优于表2,但为何在虚拟钱包的交易流水表的设计里,使用的又是字段紧凑的表2呢?
那么,在底层虚拟钱包的交易流水表里,同样会存在数据不一致的情况呀?A转出被记录下来了,B转入失败。
2019-11-29 00:50:04
2019-11-30 23:12:05
DDD战术设计是一种实施的方法论,但是因为他是看的见、摸得着(有真正所谓的代码结构可以参考)的,吸引了更多的关注点,如果没有背后的战略设计的思想,生搬硬套,甚至可能会适得其反。
DDD最重要的还是设计思想,也就是战略设计,而不是他的模式或者分层方式,也就是战术设计!
2019-11-29 07:36:04
2019-11-29 10:51:49
2019-12-06 10:50:10
2019-11-29 11:32:49
2019-11-29 10:41:28
2019-12-18 11:24:48
2019-11-29 09:13:56
同时我有如下几个疑问:
1.具体上 domain 和 entity 属性和结构上有哪些不同呢?(在我看来好像能写成一样的)
2.在贫血模型下 bo 的作用好像没有那么明显了,多写一层 bo 能给我们带来什么好处呢?
3. entity bo vo 类属性上好像有很多重合,貌似在实际编写的过程会出现很多重复代码,并且要为每一层编写转换代码,代码量好像又增加了,对于这种情况应该怎么优化和权衡呢?
2019-12-03 18:55:36
* 充血模型把业务逻辑放到 Domain 中处理,满足了 OOP 的规则,数据和行为封装为一体。
类似于 CPU 主管计算,而对于数据转换之类的工作不应该交由 Domain 去做。
* 把外围事务交给 Service 管理,比如接口传入的数据封装,底层数据库数据的读写,就好像 CPU 从来不关心 IO 的差异;比如把日志和消息幂等性等工作交给 Service 处理,CPU 也从来不负责监控和容错。
自己的感受:
这种业务相关性和业务无关性的分离,其实就是遵循了高内聚、低耦合,保证了业务和框架的独立性和重用性。
问题:
* 无论 vo 还是 Entity 在我看来都是 dto ,这么多dto会不会导致类爆炸?
大概4、5年前,我用过两天 aws 的 sdk ,我记得所有的接口都会有对应的 dto ,所以这种类爆炸是必要的类爆炸,还是也是要自己权衡?
类似关联查询返回的结果也算是 Entity 吧,Entity 未必和表一一对应吧(额,感觉不应该在这章提问)?
其他:
* 有人想要完整代码,我觉得没有太大必要,因为代码是示意代码,并非正式项目代码。
而且课程目标不是要做出一个完整小项目,实战往往和理论不是一一匹配的,而且需要大量额外工作。
* 如果老师真的打算代码上 github ,那我的建议是用接口和抽象类来完成即可,即便如此我把老师的例子完成也写了14个文件。
老师还是应该把精力放到刀刃上,如果真的非要完成个小项目,我觉得也可以延迟到栏目结束,这种限时又定量的事,作为非全职讲师一定很难吧。
* 关于问题的回复,我建议对于需要回复的问题,老师可以告知在后续章节会讲到,或者到答疑中统一提问,免得有人觉得回复不及时,而老师的一一回复既耗精力也很难普惠大家。
当然我也希望评论区功加上评论、提问、点赞几个选项,老师以后可以只看提问类型的留言,或者只看没有人回复的提问。
2020-12-30 19:57:15
1. Service CPU
2. Repository 磁盘
3. VIEW 显示器
4. RPC/三方数据 网卡
5. REDIS调用, 内存
等等, 这些不同模块的实现可以分别计算机的某一模块, 咱们的代码则是操作系统
2021-05-21 11:02:58
关于这句话,个人有不同的见解;现实中基本上所有的业务逻辑都得操作数据库,我认为实体中的动作与数据库操作是强关联的,实体类应该要操作数据对象。与开发框架进行解耦,可以交给Dao层。实体类访问Dao层,Dao层做数据适配操作持久化数据对象,当开发框架发生变化时,修改Dao层就好了。 按作者给出的架构,当开发框架发生变化后同样还得修改domain Service 。如果后期增加了冻结,透支等功能,它的本质还是去修改数据库,而实体的操作特别简单,修改下自己的属性然后传给外部domain service,domain service进行数据操作,这样的实体行为个人认为是一种伪充血模型。还不如在实体行为中去操作dao层呢,操作dao层就是实体行为之一,这样才算正真的充血。
呃呃,字数不够用了
2021-01-20 23:21:51
2019-12-02 17:37:07