你好,我是七牛云许式伟。
今天开始,我们进入第三章,谈谈服务端开发。
服务端的发展史
服务端开发这个分工,出现的历史极短。短得让人难以想象。
1946 年,第一台电子计算机问世。1954 年,第一门高级语言 Fortran 发布。整个信息科技发展到今天,大约也就 60~70 年的历史。
1974 年,Internet 诞生。1989 年,万维网(WWW)诞生,但刚开始只限于政府和学术研究用途,1993 年才开始进入民用市场。
从这个角度来说,服务端开发这个分工,从互联网诞生算起也就 40 多年的历史。真正活跃的时段,其实只有 20 多年。
但其发展速度是非常惊人的。我们简单罗列下这些年来的标志性事件。
- 1971 年,电子邮件诞生。
- 1974 年,Internet 诞生。
- 1974 年,第一个数据库系统 IBM System R 诞生。SQL 语言诞生。
- 1989 年,万维网(WWW)诞生。
- 1993 年,世界上第一个 Web 服务器 NCSA HTTPd 诞生,它也是大名鼎鼎的 Apache 开源 Web 服务器的前身。
- 1998 年,Akamai 诞生,提供内容分发网络(CDN)服务。这应该算全球第一个企业云服务,虽然当时还没有云计算这样的概念。
- 2006 年,Amazon 发布弹性计算云(Elastic Compute Cloud),简称 EC2。这被看作云计算诞生的标志性事件。
- 2007 年,Amazon 发布简单存储服务(Simple Storage Service),简称 S3。这是全球第一个对象存储服务。
- 2008 年,Google 发布 GAE(Google App Engine)。
- 2009 年,Go 语言诞生。Derek Collison 曾预言 Go 语言将制霸云计算领域。
- 2011 年,七牛云诞生,发布了 “对象存储+CDN+多媒体处理” 融合的 PaaS 型云存储,为企业提供一站式的图片、音视频等多媒体内容的托管服务。
- 2013 年,Docker 诞生。
- 2013 年,CoreOS 诞生。这是第一个专门面向服务端的操作系统。
- 2014 年,Kubernetes 诞生。当前被认为是数据中心操作系统(DCOS)的事实标准。
通过回顾服务端的发展历史,我们可以发现,它和桌面开发技术迭代的背后驱动力是完全不同的。
桌面开发技术的迭代,是交互的迭代,是人机交互的革命。而服务端开发技术的迭代,虽然一开始沿用了桌面操作系统的整套体系框架,但它正逐步和桌面操作系统分道而行,转向数据中心操作系统(DCOS)之路。
服务端程序的需求
这些演进趋势的根源是什么?
其一是规模。
桌面程序是为单个用户服务的,所以它关注点是用户交互体验的不断升级。
服务端程序是被所有用户所共享,为所有用户服务的。一台物理的机器资源总归是有限的,能够服务的用户数必然存在上限,所以一个服务端程序在用户规模到达一定程度后,需要分布式化,跑在多台机器上以服务用户。
其二是连续服务时长。
桌面程序是为单个用户服务的,用户在单个桌面程序的连续使用时长通常不会太长。
但是服务端程序不同,它通常都是 7x24 小时不间断服务的。当用户规模达到一定基数后,每一秒都会有用户在使用它,不存在关闭程序这样的概念。
其三是质量要求。
每个桌面程序的实例都是为单个用户服务的,有一亿的用户就有一亿个桌面程序的实例。
但是服务端程序不同,不可能有一亿个用户就跑一亿个,每个用户单独用一个,而是很多用户共享使用一个程序实例。
这意味着两者对程序运行崩溃的容忍度不同。
一个桌面程序实例运行崩溃,它只影响一个用户。
但一个服务端程序实例崩溃,可能影响几十万甚至几百万的用户。
这是不可接受的。
一个服务端程序的实例可以崩溃,但是它的工作必须立刻转交给其他的实例重新做,否则损失太大了。
所以服务端程序必须能够实现用户的自动转移。一个实例崩溃了,或者因为需要功能升级而重启了,它正在服务的用户需要转给其他实例来服务。
所以,服务端程序必须是多实例的。单个程序实例的临时不可用状态,要做到用户无感知。
从用户视角看,服务端程序 7x24 小时持续服务,任何时刻都不应该崩溃。就如同水电煤一样。
服务端开发的体系架构
在 “01 | 架构设计的宏观视角” 这一讲中,我们将一个服务端程序完整的体系架构归纳如下:

这个架构体系,是为了方便你和桌面开发的体系架构建立自然的对应关系而画的。
它当然是对的,但它只是从服务端程序的单个实例看的,不是服务端程序体系架构的全部。
在 “15 | 可编程的互联网世界” 这一讲中,我们把 TCP/IP 层比作网络的操作系统,一个网络程序的体系架构如下:
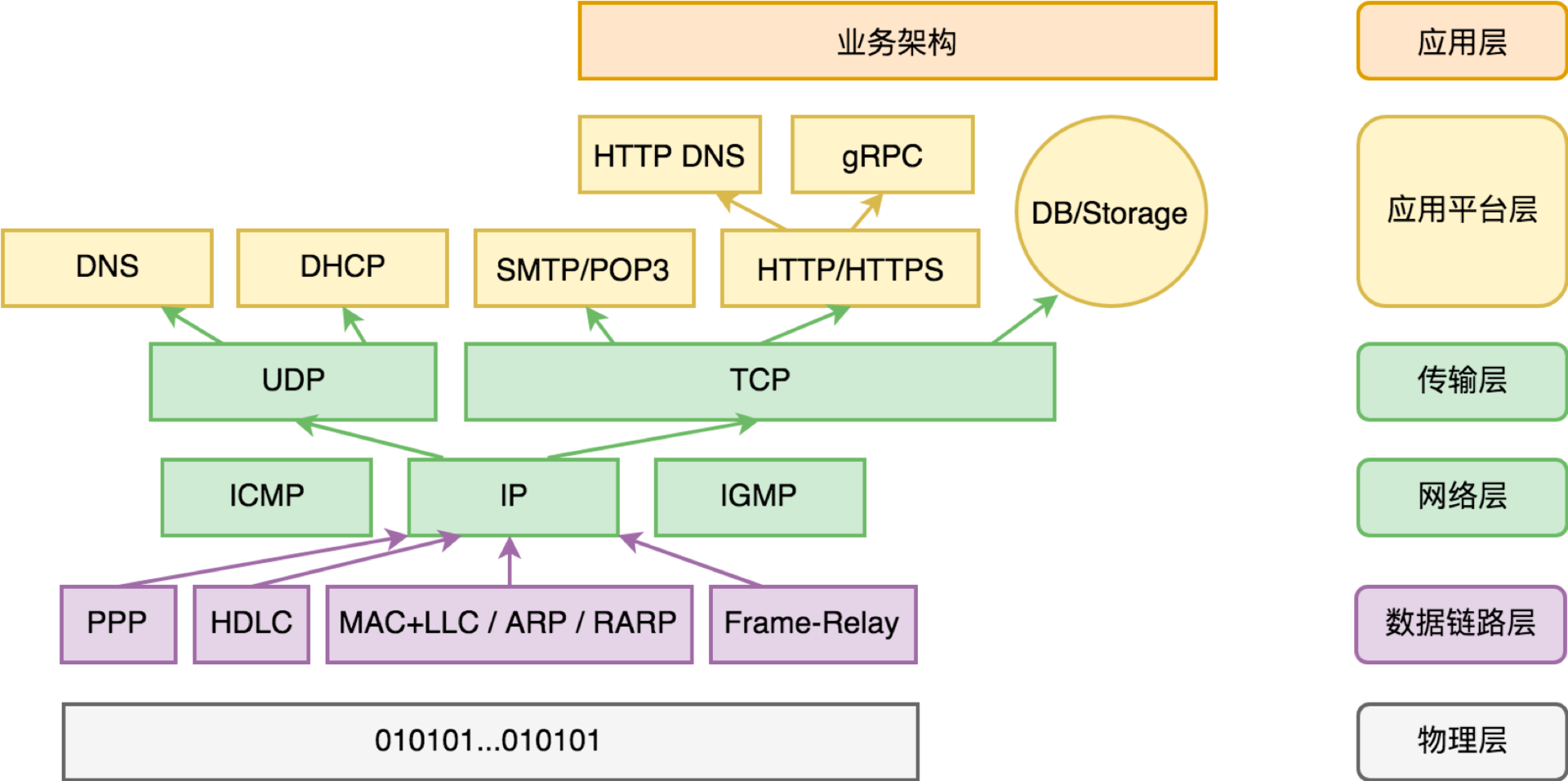
一个服务端程序当然也是一个网络程序,它符合网络程序的体系架构。
但它也不是服务端程序体系架构的全部。
从宏观视角看,一个服务端程序应该首先是一个多实例的分布式程序。其宏观体系架构示意如下:
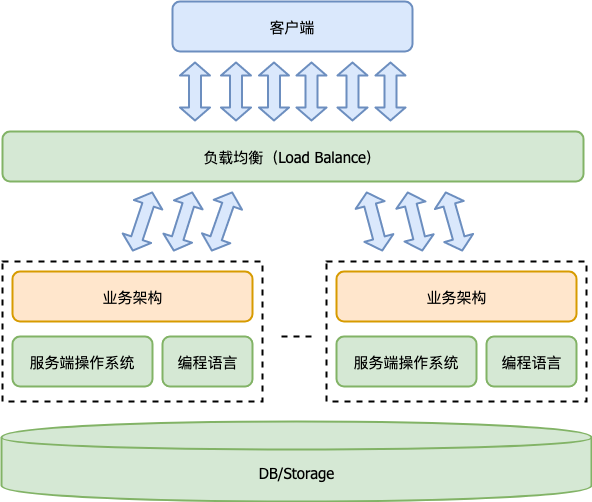
相比桌面程序而言,服务端程序依赖的基础软件不只是操作系统和编程语言,还多了两类:
- 负载均衡(Load Balance);
- 数据库或其他形式的存储(DB/Storage)。
为什么会需要负载均衡(Load Balance)?为什么会需要数据库或其他形式的存储?你可以留言探讨一下。我们在接下来的几讲将聊聊负载均衡和存储。
结语
今天我们从服务端的发展历程、服务端开发的需求谈起,以此方便你理解服务端开发的生态会怎么演化,技术迭代会走向何方。
我们这里探讨的需求和具体业务无关,它属于服务端本身的领域特征。就像桌面的领域特征是强交互,以事件为输入,GDI 为输出一样,服务端的领域特征是大规模的用户请求,以及 24 小时不间断的服务。
这些领域特征直接导致了服务端开发的体系架构和桌面必然是如此的不同。
如果你对今天的内容有什么思考与解读,欢迎给我留言,我们一起讨论。下一讲我们将聊聊负载均衡(Load Balance)。
如果你觉得有所收获,也欢迎把文章分享给你的朋友。感谢你的收听,我们下期再见。
精选留言
2019-10-30 08:49:04
2019-09-05 10:37:59
2019-08-20 10:02:20
2.用户权限控制,用户信息安全。用户操作记录,数据分析。数据持久化在服务端是一个成本比较大的选择。但这对维护用户数据安全,服务提供多用户同一份数据,用户权限控制,后续做战略布局的数据分析,和智能推荐的机器学习啥的都比较重要。
2019-08-20 10:01:56
2、存储提供的是持久化的能力。因为系统中会出现业务数据,不存起来以后就无法拿到这些数据了。各种数据库,比如 MySQL;数据共享,比如发送文件、图片;提高性能,比如Redis做缓存;更基础的概念,比如磁盘,内存,寄存器,没有他们计算机跑不起来。
2019-08-20 09:59:51
2019-08-23 10:46:03
2020-05-09 22:22:16
实现高并发和高可用的必杀技就是:「分布式」
为什么需要负载均衡:解决分布式的分发问题
为什么需要数据库和存储:解决分布式的数据共享问题
当然,负载均衡器和数据库也是分布式的
2019-09-29 19:23:45
2020-09-08 19:43:40
2020-05-23 23:49:15
2019-08-22 22:10:10
2019-08-20 08:28:05
2019-08-20 08:14:19
因为服务器后端需要持久化存储大量的状态数据,为了分布式实例共享数据及尽量去状态,提高数据存取效率及安全性,所以需要集中式的数据库或其他形式的存储。
2019-08-20 07:29:56
2023-09-04 12:31:04
--记下来
2022-09-30 18:10:54
2021-07-30 12:48:12
负载均衡起到分发隔离的作用重启宕机对用户无感知
2021-04-19 22:20:38
为了满足大规模这个需求,服务端的机器从一台变多台,还能够保证个别机器崩溃之后依然能够服务用户。
为了满足几乎不间断服务,负载均衡出现了,它能根据每个服务器自身的吞吐量,给其分配合理的请求数,让能力大的机器处理更多请求,能力小的则相对处理较少的请求,这样既降低了服务器崩溃的风验。
为了满足可靠性,用户的数据都会被存储在数据库中,这些数据由软件商来维护,当用户需要用这些数据的时候,总能够拿到这些数据。
2021-04-19 07:32:32
2021-03-10 09:53:50