你好,我是谢友鹏。
在上一节课中,我们从应用层代码的角度探讨了如何提升单机性能,今天我们将进入单机性能优化的第二个层面,从网络模型和协议的角度进一步提升性能。
打个比方,网络作为数据传输通道,扮演着类似运输货物的角色。发送方和接收方各自有一个“仓库”。网络模型的作用在于如何最大化利用这些仓库空间:发送方能及时发现“发送仓库”有空间,并用数据将其填满,同时在接收方准备好处理数据时,及时从“接收仓库”取出数据,以腾出空间接收更多的数据。
而网络协议优化则着眼于让仓库空间和运输速度尽可能匹配,并在数据丢失时,尽快恢复丢失的数据,确保数据传输的高效与稳定。
网络模型
网络模型是用户态与内核态进程交互的模型。
想要弄明白这些交互过程,需要我们先熟悉一下阻塞、非阻塞以及同步、异步,系统调用的概念。
阻塞和非阻塞是描述系统调用时“等待数据准备好”的方式。在阻塞模式下,应用进程会一直等待直到数据准备好;而在非阻塞模式下,应用进程不会等待,而是立即返回,做其他事情。
同步和异步则涉及“数据从内核到用户空间的复制”。同步模式,内核将数据准备好后,通知应用进程,应用进程随后调用系统函数来读取数据;而异步模式,内核在将数据拷贝到用户空间后,直接通知应用进程,应用进程可以直接使用数据。
I/O模型详解
接下来我们看看网络的I/O模型,《UNIX 网络编程》介绍了五种 I/O 模型。我们以UDP接收文件为例,挨个看看这五种模型的工作方式。
首先是阻塞式I/O模型。
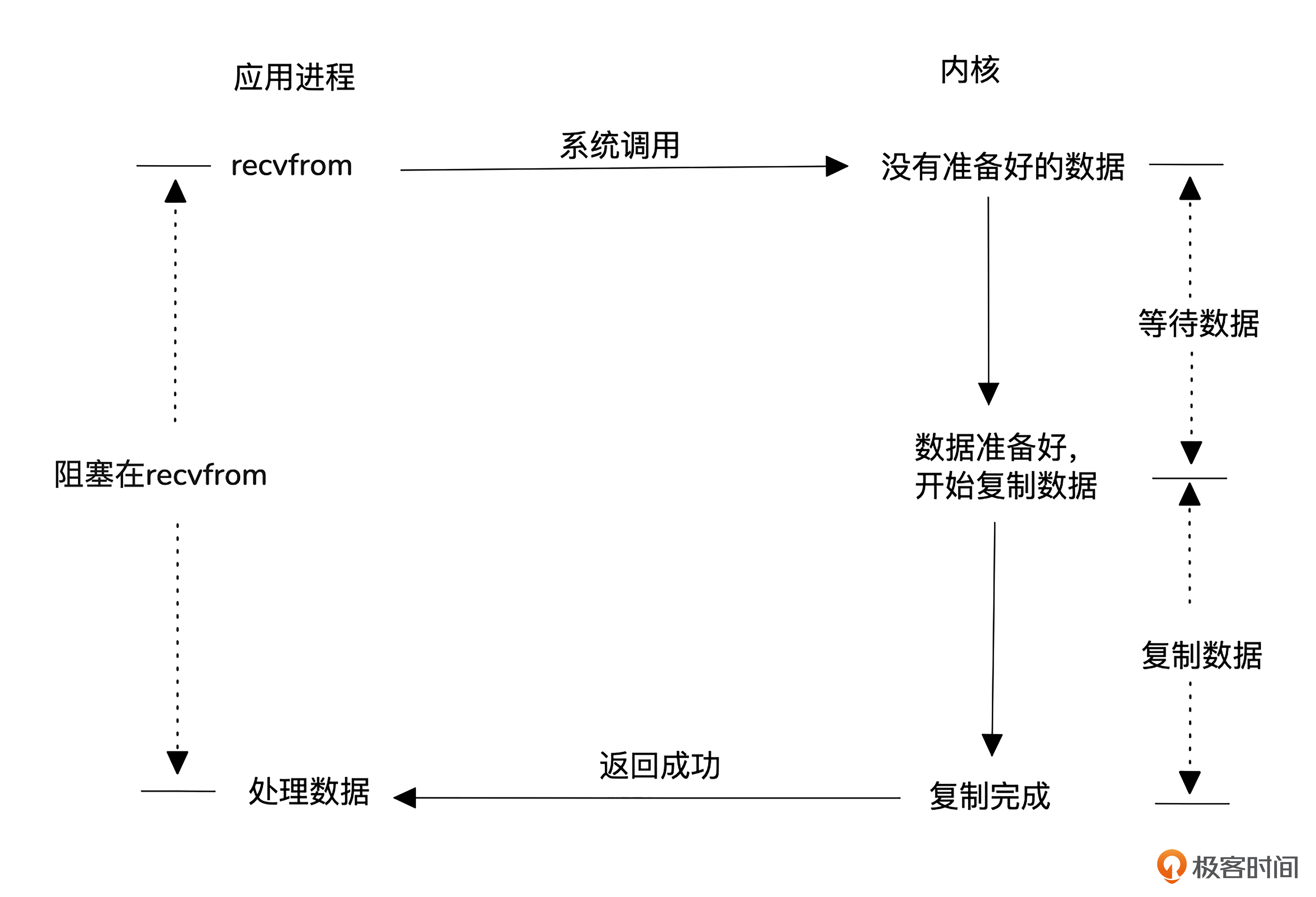
这种模型使用最简单,用户进程发起数据读取后会一直等待,直到内核准备好数据并拷贝到用户空间。但缺点是效率低下,每个请求都需要一个进程或线程,高并发时,系统会面临大量进程调度和上下文切换的开销。
然后是非阻塞式 I/O模型。
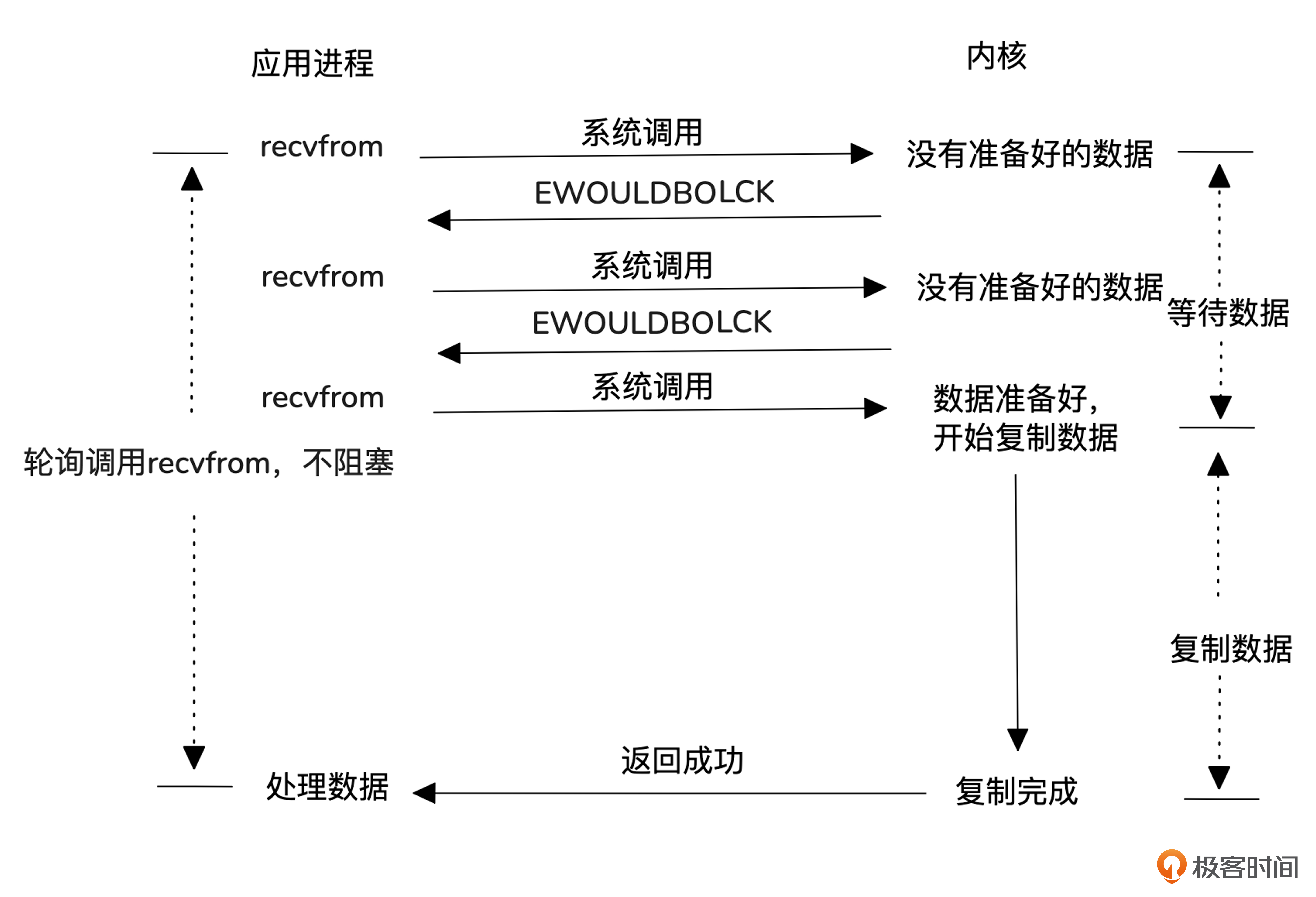
这种模型采用非阻塞方式与内核交互,数据未准备好时立即返回,允许用户进程去做其他事,稍后再尝试读取数据。与阻塞模型相比,它避免了进程空等数据,提高了效率。但每次轮询都涉及系统调用,导致上下文切换增多,性能提升有限。
接下来我们看一下目前常用的一种模型,I/O 复用模型。
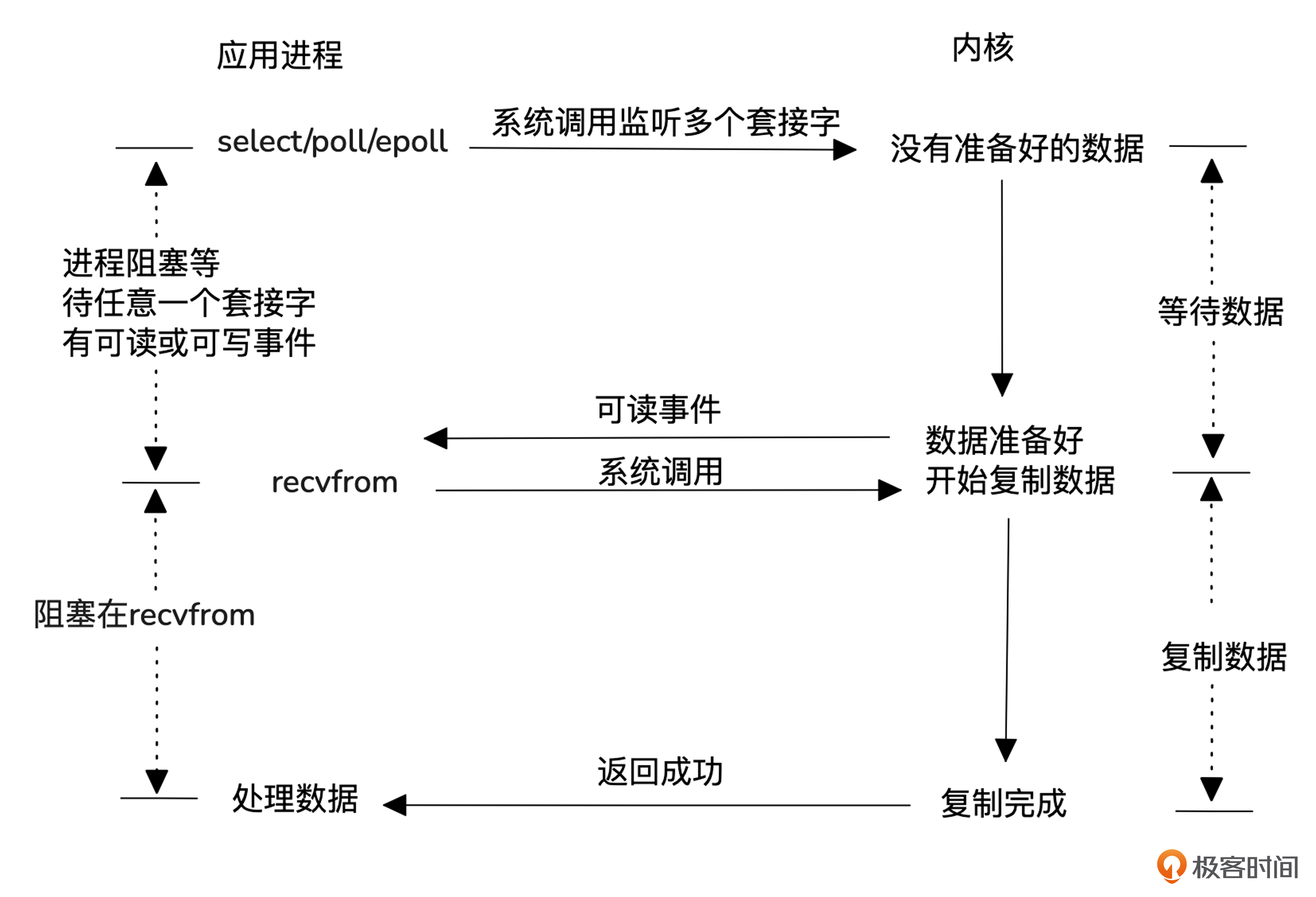
为了避免频繁查询内核而影响性能,I/O复用模型通过注册和通知机制来优化。用户进程将所有I/O事件(如使用select、poll或epoll)注册到内核,内核会在数据准备好时主动通知进程。这样,单个进程或线程就能同时处理多个I/O请求,提高了效率,避免了阻塞和过多的系统调用。需要注意的是,数据准备好后,仍需通过系统调用读取数据。
然后我们看一个比较冷门的模型,信号驱动式 I/O模型。
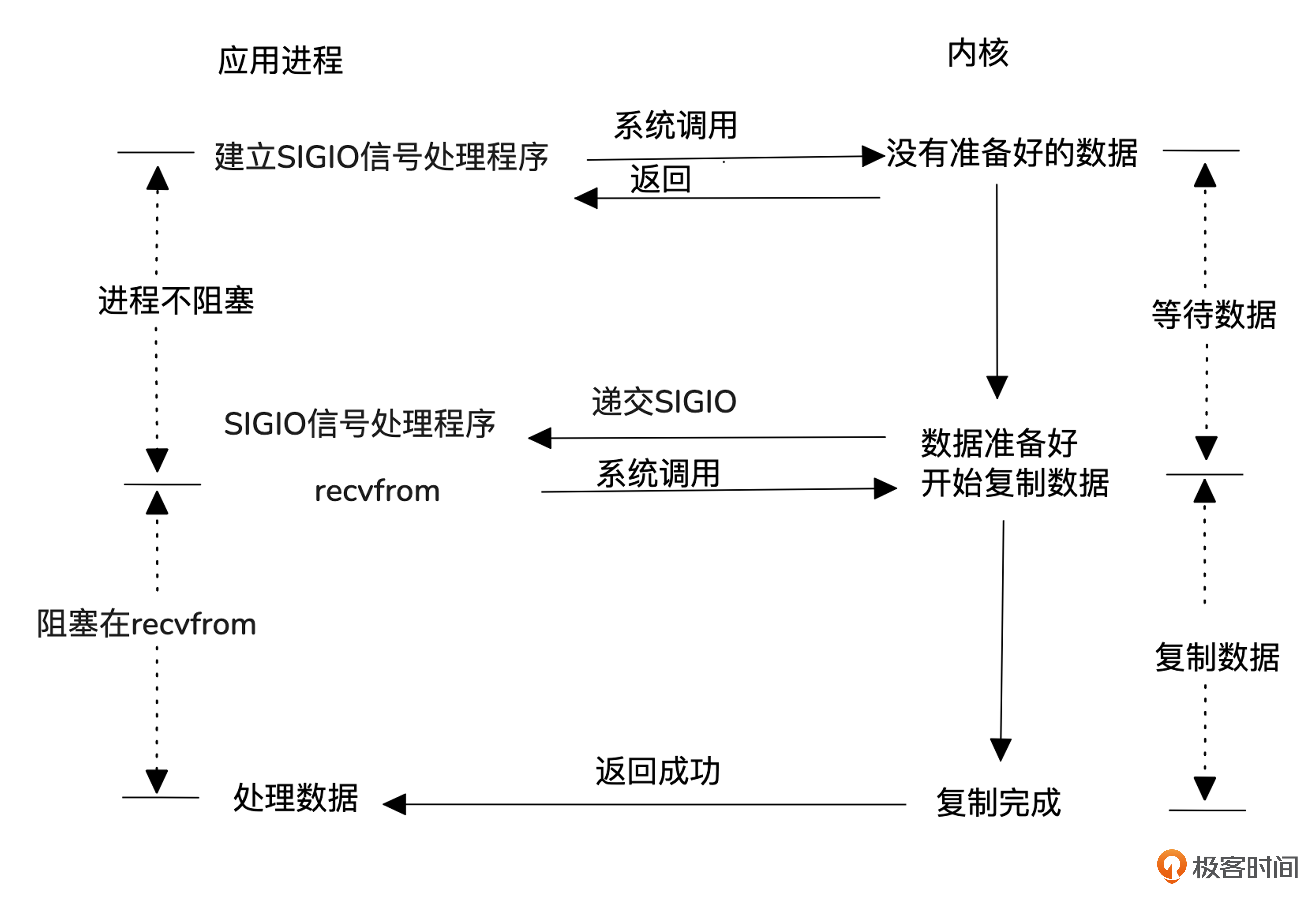
信号驱动式I/O模型不像I/O复用模型那样,用一个进程去内核注册,获取并分发事件,而是每个请求进程自己向内核注册,当数据准备好时,内核通过信号通知进程处理。
这个模型常用于UDP的NTP服务,但在TCP中应用较少,因为TCP会频繁产生信号,且无法明确告知应用程序发生了什么事件。例如,在连接请求完成、断链请求发起或完成、半连接关闭、数据到达或发送、发生异步错误等多种情况下,TCP会都会产生SIGIO信号。
最后我们看一下异步 I/O模型。
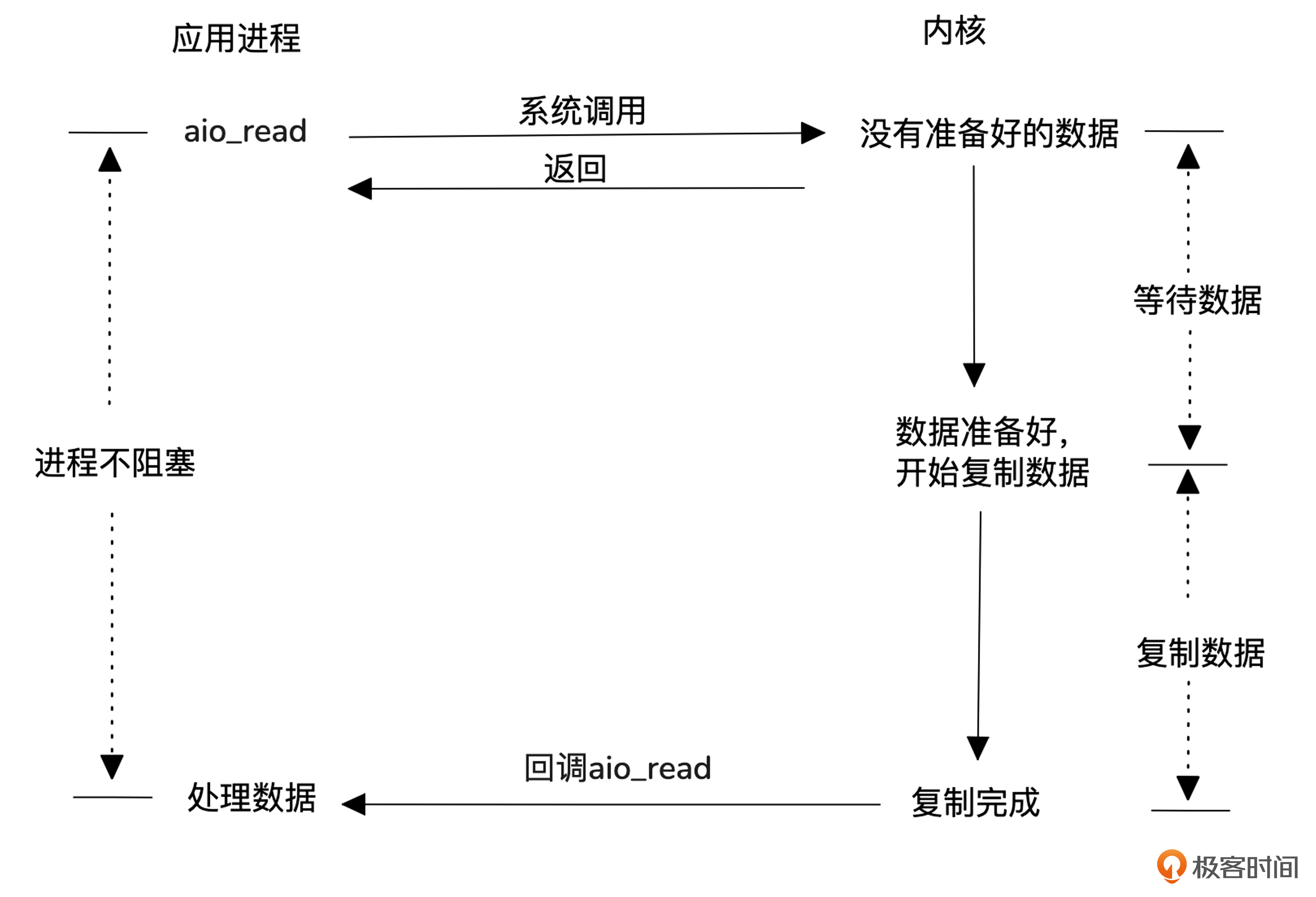
前面几种模型都是同步系统调用,异步I/O模型使用的是异步系统调用,所以省去了用户进程去内核拷贝数据的消耗。
早期Linux内核对异步I/O的支持较差,因此很多服务器采用 I/O 复用(如epoll)。从Linux 5.0版本开始,新增的 io_uring 技术逐渐成熟,越来越多的服务器(如 Nginx)开始支持异步I/O。
至此,我们已学习了五种网络I/O模型。其中,最常用的是基于I/O多路复用的Reactor模型,而Proactor模型则通过异步I/O提供更高的效率。这两种高效的I/O模型能够减少用户态与内核态之间的交互开销,并及时响应内核态的读写事件。
网络协议
接下来,我们将学习网络协议的性能调优。
MTU性能影响
在网络中,MTU(Maximum Transmission Unit)指的是网络层能够传输的单个数据包的最大字节数。如果MTU值设置得过小,数据就需要被拆分成更多的小包来传输。因此,合理的MTU设置对于优化网络性能至关重要。
你可以通过以下命令查看网卡的MTU值。
$ ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.16.253.136 netmask 255.255.255.0 broadcast 172.16.253.255
inet6 fe80::20c:29ff:fe7a:d769 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:7a:d7:69 txqueuelen 1000 (Ethernet)
RX packets 515461 bytes 34051106 (34.0 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 3139630 bytes 2354811440 (2.3 GB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
在以太网中,常见的MTU值是1500字节。高带宽环境,可以使用“Jumbo Frame”,其MTU值可以达到9000字节左右。
TCP窗口对性能影响
讨论完MTU后,我们再来看看TCP窗口对性能的影响。TCP的窗口对性能的影响主要体现在流量控制的滑动窗口和拥塞控制的拥塞窗口。
流控性能分析
首先,TCP 为了实现可靠传输,采用了确认机制。每个传输的字节都会进行序列号(SEQ)编号。当发送方发送的数据到达接收方时,接收方会在确认消息(ACK)中返回自己已接收的最后一个字节的序列号。这样,发送方就知道接收方已经成功接收的数据位置。
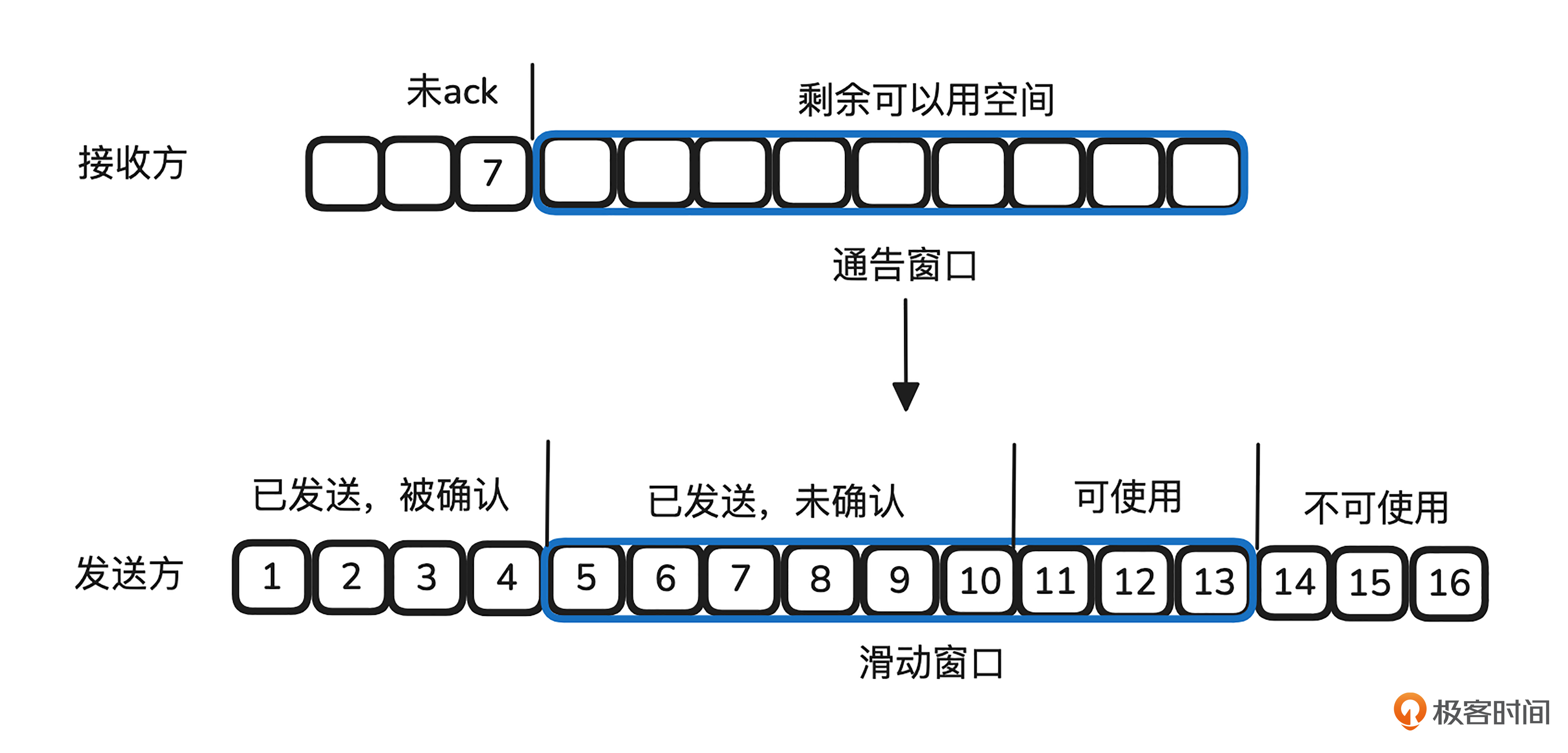
如图所示,为了避免发送方发送数据时接收方没有足够空间存放,TCP 实现了流量控制机制。发送方和接收方各自维护一个缓冲区,作为数据传输的“仓库”。接收方在每次返回 ACK 时,会告诉发送方它的缓冲区剩余空间大小。发送方根据接收到的 ACK 信息,了解对方可用的窗口大小,这个大小等于接收方的总缓冲区空间减去尚未确认的数据量。随着接收方确认新的数据,窗口会随之滑动,腾出空间。
接收方缓冲区存储的数据可以被应用层读取,一旦应用层读取数据,缓冲区空出的空间就会增大,允许接收更多数据。
可以看出,报文的 ACK 速度和接收方窗口的大小决定了发送方能够发送多少数据。ACK 速度可以通过网络中的带宽延迟积(BDP)来衡量。
BDP 是指网络带宽与往返时延(RTT)的乘积,反映了网络中一个连接在给定时延下,能够传输的最大数据量。RTT 越长,BDP 值越大,接收方的窗口也应该相应增大,以保持高速的数据传输。
网络传输本身是动态的,接收方窗口应该如何设置呢?幸运的是,Linux 内核提供了动态调整接收缓冲区的功能,默认情况下Linux是会开启接收缓冲区调整功能的,可以通过下面命令确认:
$ sysctl net.ipv4.tcp_moderate_rcvbuf
net.ipv4.tcp_moderate_rcvbuf = 1
这个值如果是1就是打开了接收缓冲区的调整功能,0是关闭。
接收缓冲区的调整范围,可以通过下面的命令来查看:
$ sysctl net.ipv4.tcp_rmem
net.ipv4.tcp_rmem = 4096 131072 6291456
这三个值分别为最小、默认和最大接收缓冲区的值,单位是字节。
应用程序也可以设置SO_RCVBUF来接收缓冲区的大小(设置的值并不直接等于接收缓冲区大小,这点可以通过手册查看)。一旦应用层设置了接收缓冲区大小,内核的动态调整功能就会失效。因此,除非确认自己设置的值适合当前场景,否则不建议应用层自行设置接收缓冲区大小。有一些性能问题就是因为陈旧的代码设置了较小的接收缓冲区导致的。
值得注意的是在 TCP 协议中,通告窗口(Window Size)只有 16 位,这意味着最大窗口值为 65535 字节,即 64 KB。为了满足现代网络高带宽的需求,TCP 引入了窗口扩展(TCP Window Scaling)机制,对其进行了扩展。
我们在Linux中,通过下面命令即可查看是否开启了窗口扩展功能:
$ sysctl net.ipv4.tcp_window_scaling
net.ipv4.tcp_window_scaling = 1
开启窗口扩展功能后,接收方的实际窗口为window * window size scaling factor。这一点你可以在Wireshark上抓包看出来。
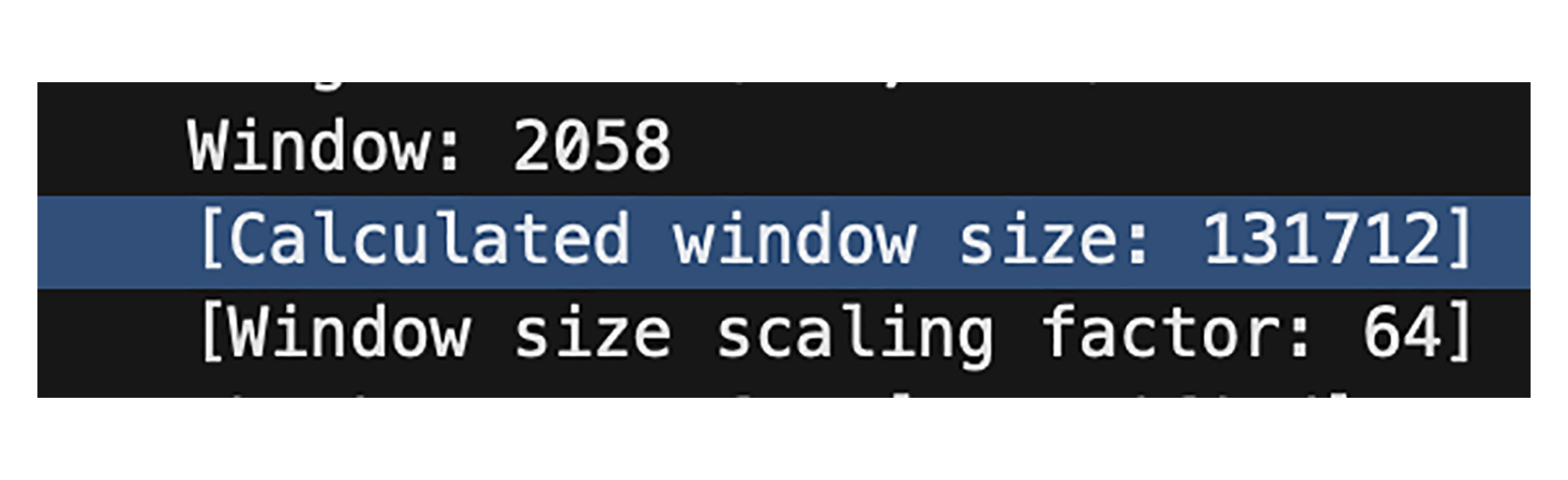
TCP 窗口扩展功能需要发送方和接收方都支持才能生效。在 TCP 握手的初始 SYN 报文中,发送方会携带窗口扩展选项。接收方收到 SYN 后,如果支持窗口扩展,它会在 SYN-ACK 响应报文中返回一个相应的窗口扩展选项,告知对方自己的窗口缩放因子。一旦三次握手完成,双方就可以根据协商的缩放因子来计算实际的窗口大小。注意,有些代理****建连过程中会丢失窗口扩展选项,从而引发性能问题。
上面讨论的前提是发送方的缓冲区足够大,如果发送方的缓冲区本身很小,也会影响速度。同样的,Linux也提供了动态调整发送缓冲区的功能,而且这个功能没有开关,默认就是打开的。发送缓冲区的范围,可以通过下面的方法查看:
$ sysctl net.ipv4.tcp_wmem
net.ipv4.tcp_wmem = 4096 16384 4194304
这三个值分别为最小、默认和最大发送缓冲区的大小,单位是字节。
发送方缓冲区也可以在应用层设置SO_SNDBUF来调整,一旦应用层设置该值,内核的动态调整缓冲区能力将会失效。同样的,除非非常确认自己设置的值适合当前场景,否则不建议应用层自行设置发送缓冲区大小。
另外,TCP还有一个全局的内存使用限制,可以通过下面的命令查看:
$ sysctl net.ipv4.tcp_mem
net.ipv4.tcp_mem = 44379 59173 88758
这三个值分别表示低阈值、压力阈值和高阈值,单位是 Page(页数),一般是 4K。
它们的具体含义如下:
-
低阈值:当 TCP 使用的内存小于这个值时,它不会限制自己的内存分配。
-
压力阈值:当 TCP 使用的内存超过这个值时,系统会认为发生了内存压力,TCP 会开始限制自己的内存使用,以避免过度消耗内存。
-
高阈值:这是 TCP 可以使用的最大内存限制。当 TCP 使用的内存达到或超过这个值时,内核会强制限制 TCP 的内存分配,不能再超过这个上限。
因此如果你的服务工作在高BDP场景,可以根据机器规格适当调高这些阈值,来提升性能。
拥塞性能分析
学会了流控相关窗口对性能的影响后,我们再来看看拥塞控制TCP对性能的影响。
TCP的拥塞控制是一个典型的负反馈机制,发送方判断出网络出现拥塞的时候,就会减少发送报文的量,以免加剧网络拥塞。
首先我们要掌握拥塞控制有几个关键参数。
-
MSS(Maximum Segment Size):每个TCP段的最大有效负载大小,不包括TCP头部。MSS通常由链路的MTU决定,避免分片。
-
拥塞窗口(cwnd):控制发送数据的量,表示发送方在没有收到ACK确认之前可以发送的最大数据量,单位是多少个MSS。
-
ssthresh(Slow Start Threshold):慢启动阈值,决定了从慢启动阶段到拥塞避免阶段的切换点。
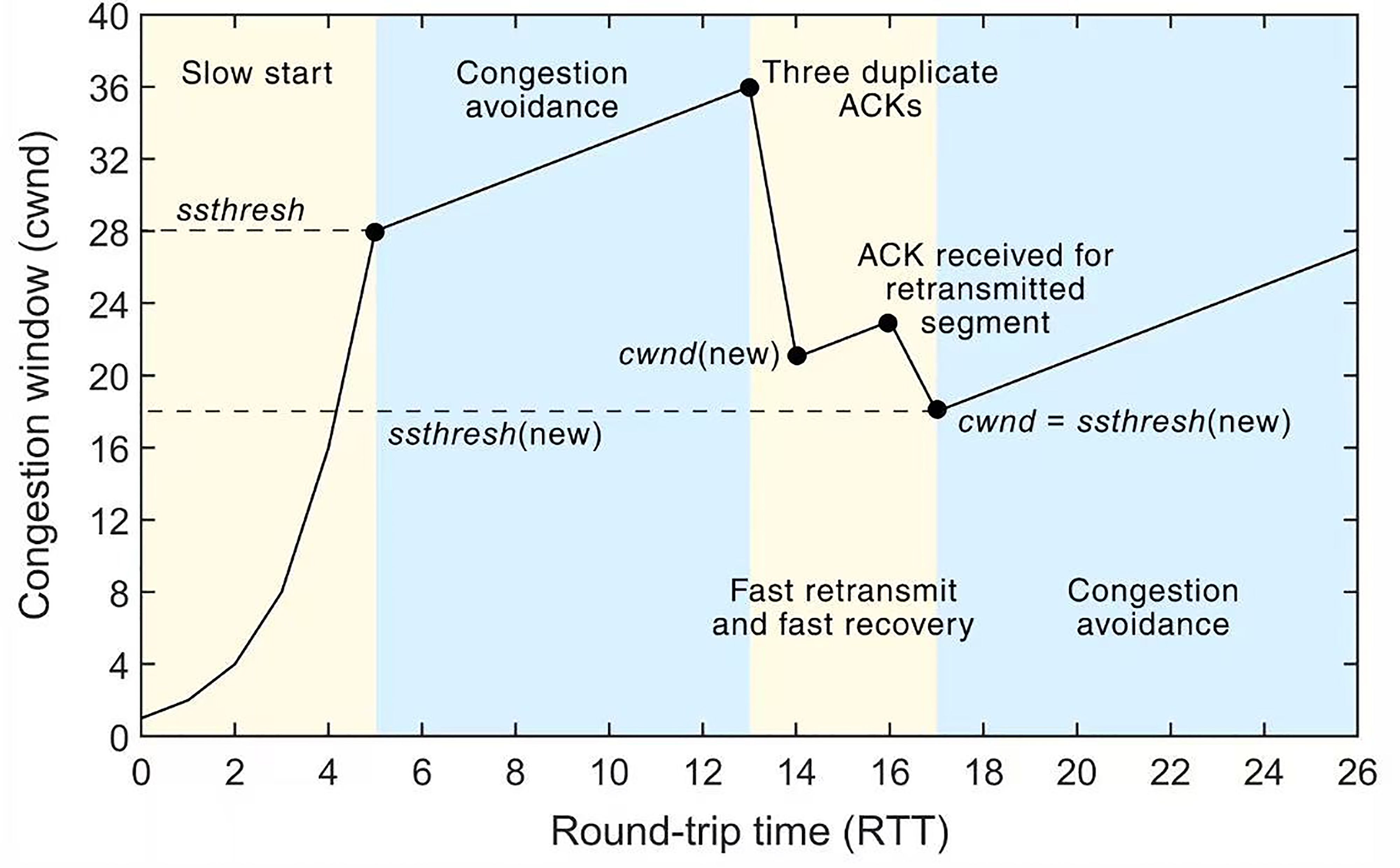
下图是一个基于丢包进行拥塞判断的拥塞控制机制的典型图。
(图片来自:https://encyclopedia.pub/entry/12206)
如图所示,拥塞控制机制会经历以下几个阶段。
- 慢启动(Slow Start):在连接开始时,TCP的拥塞窗口(cwnd)从一个较小的值(通常为1个MSS)开始增长,逐步增加数据的发送量。每当收到一个ACK时,cwnd就会增加1个MSS。这个过程是指数增长,即每收到一个ACK,cwnd就翻倍。慢启动会持续进行,直到cwnd达到ssthresh(慢启动阈值)为止。
2.拥塞避免阶段(Congestion Avoidance):当cwnd达到ssthresh时,TCP进入拥塞避免阶段。在这个阶段,cwnd不再指数增长,而是以线性方式增加:每收到一个ACK,cwnd增加1个MSS/cwnd大小。这使得拥塞窗口的增长速度变得更加平缓,从而避免因为发送过多数据而造成网络拥塞。
3.快重传(Fast Retransmit):当TCP接收到三个重复的ACK时,会立刻进行快重传,不再等待超时。这个阶段不直接影响cwnd的大小,但会触发cwnd的缩小。TCP会根据重复的ACK确认丢失的数据包,并重新传输。
4.快恢复(Fast Recovery):在快重传之后,TCP会进入快恢复阶段。在这个阶段,cwnd不会回到慢启动的初始值,而是被减半,然后线性增加。具体来说,cwnd会设置为ssthresh的值,再加上丢失的数据段数。快恢复使得TCP在丢包后不会完全放弃之前的传输速率,而是较为平稳地恢复到正常状态。
可以看出当发送丢包或者乱序的时候,就会减少拥塞窗口的值。然而,基于丢包来判断拥塞的方式存在两个主要问题:
- 丢包并不等于拥塞:在无线网络或“长肥”网络中,丢包可能是由于其他因素(如链路质量差)造成的,而非拥塞。将丢包误判为拥塞会导致不必要的窗口缩减,进而影响性能。
- 不丢包并不等于没有拥塞:在许多现代网络中,当路由器处理不过来时,它可能将数据包缓存到缓冲区中,而不会丢包。这种做法虽然避免了丢包,但却可能导致网络的严重抖动,影响整体的传输效率。
为了应对这些问题,Google在2016年提出了BBR(Bottleneck Bandwidth and RTT)拥塞控制算法。BBR并不依赖丢包来判断拥塞,而是通过交替测量网络的带宽和时延,并计算带宽-时延积(BDP)来控制数据包的发送速率。这种算法特别适用于带宽大且延迟高的网络环境,可以显著提高性能。
在Linux中,BBR算法可以通过以下命令启用:
#查看当前tcp拥塞算法
$ sysctl net.ipv4.tcp_congestion_control
net.ipv4.tcp_congestion_control = cubic
#将拥塞算法设置为bbr
$ sysctl -w net.ipv4.tcp_congestion_control=bbr
拥塞窗口可以通过下面命令进行观察:
$ sudo ss -itn
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
ESTAB 0 3634480 172.16.253.136:8080 172.16.253.140:57304
cubic wscale:7,7 rto:298 rtt:97.382/7.668 ato:40 mss:1448 pmtu:1500 rcvmss:536 advmss:1448 cwnd:1669 ssthresh:1426 bytes_sent:315981184 bytes_retrans:1042560 bytes_acked:312542184 bytes_received:86 segs_out:218225 segs_in:6477 data_segs_out:218224 data_segs_in:1 send 198534596bps lastsnd:3 lastrcv:11775 lastack:3 pacing_rate 238241512bps delivery_rate 181858904bps delivered:215850 busy:11774ms rwnd_limited:10ms(0.1%) unacked:1655 retrans:0/720 rcv_space:14600 rcv_ssthresh:64076 notsent:1238040 minrtt:0.516 snd_wnd:4613120
其中,cwnd的值就是拥塞窗口了。
至此,我们学完了TCP窗口相关的性能影响。总结一下,就是TCP能发送的数据会收到发送缓冲区大小、接收缓冲区大小、网络的BDP以及网络拥塞情况的影响,而且存在木桶效应,哪一个先出现瓶颈,都会影响性能。
除了窗口外,TCP性能还受其他多种机制的影响。例如:开启SACK(Selective Acknowledgment)可以减少丢包导致的重传量,适合丢包率高的网络。启用MTU探测可以自动调整传输路径中的最大传输单元,避免因路径MTU不匹配而导致的分段。开启TCP_NODELAY选项,可以关闭Nagle算法,避免小包延迟,提升实时应用性能。
HTTP性能改进
除了 TCP 调优之外,HTTP 协议演进过程也做了不少性能优化,我列个表格比较了h1、h2和h3的性能改进点。
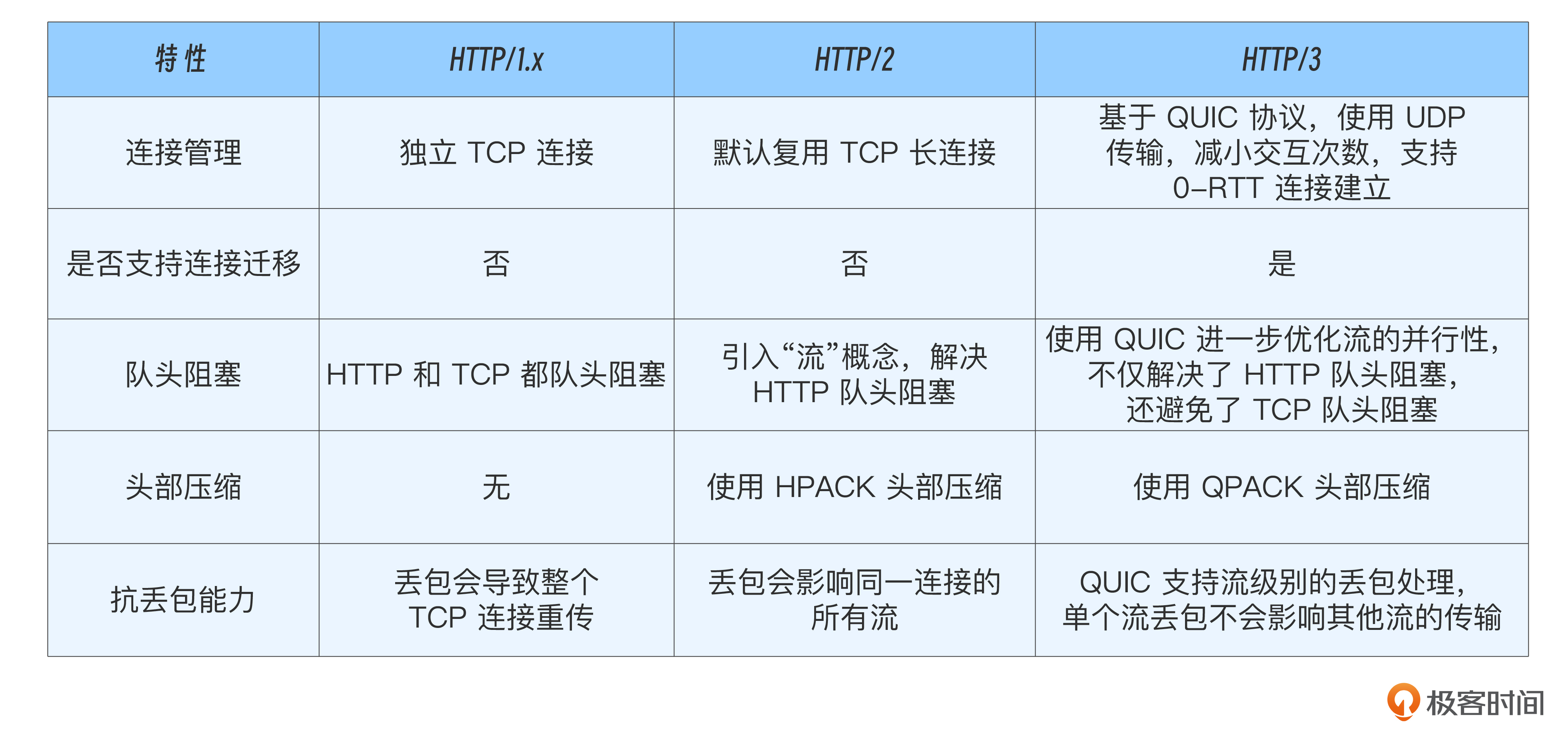
对照表格不难看出,升级到较新的 HTTP 协议版本可以在一定程度提升性能。
实验
接下来我们进入实验环节。
实验设计
我们今天通过实验观察一下 MTU 和 TCP 窗口扩展对性能的影响。
开始实验
我写了个脚本 http_server.py,监听8080端口,接收到http get请求后会返回1G大小的数据。我们先将脚本下载到实验环境,并启动server。
$ sudo python3 http_server.py
Starting HTTP server on port 8080...
接下来我们先测试个基准数据。一般情况下,MTUU使用默认值1500,TCP window scale默认打开,如果你的环境不是这两个值也没关系,可以按照下面操作进行调整。
#查看mtu值,一般为默认1500。
#如果不是使用sudo ip link set dev ens33 mtu 1500设置,注意替换网卡名。
$ ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.16.253.136 netmask 255.255.255.0 broadcast 172.16.253.255
inet6 fe80::20c:29ff:fe7a:d769 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:7a:d7:69 txqueuelen 1000 (Ethernet)
RX packets 499 bytes 294454 (294.4 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 283 bytes 57902 (57.9 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
#查看TCP window scale是否已经开启,默认是开启的。
#如果未开启使用$ sudo sysctl -w net.ipv4.tcp_window_scaling=1打开。
$ sysctl net.ipv4.tcp_window_scaling
net.ipv4.tcp_window_scaling = 1
然后测试请求耗时,作为对比的基线数据。
$ time curl -o /dev/null -v http://172.16.253.136:8080/test
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0* Trying 172.16.253.136:8080...
* Connected to 172.16.253.136 (172.16.253.136) port 8080
> GET /test HTTP/1.1
> Host: 172.16.253.136:8080
> User-Agent: curl/8.7.1
> Accept: */*
>
* Request completely sent off
* HTTP 1.0, assume close after body
< HTTP/1.0 200 OK
< Server: BaseHTTP/0.6 Python/3.12.3
< Date: Mon, 18 Nov 2024 16:08:46 GMT
< Content-Type: application/octet-stream
< Content-Length: 1073741824
<
{ [8688 bytes data]
100 1024M 100 1024M 0 0 79.3M 0 0:00:12 0:00:12 --:--:-- 61.5M
* Closing connection
real 0m12.919s
user 0m0.716s
sys 0m2.608s
可以看出,我这里mtu设置为1500,打开TCP window scale的情况下,下载1G文件耗时12s。
MTU 对性能的影响
将mtu设置为500,TCP window scale保持打开状态,然后进行请求观察耗时。
#将mtu修改为500
$ sudo ip link set dev ens33 mtu 500
$ ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 500
inet 172.16.253.136 netmask 255.255.255.0 broadcast 172.16.253.255
ether 00:0c:29:7a:d7:69 txqueuelen 1000 (Ethernet)
RX packets 103426 bytes 6849826 (6.8 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 742645 bytes 1122801166 (1.1 GB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 92 bytes 7288 (7.2 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 92 bytes 7288 (7.2 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
#发起请求
$ time curl -o /dev/null -v http://172.16.253.136:8080/test
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0* Trying 172.16.253.136:8080...
* Connected to 172.16.253.136 (172.16.253.136) port 8080
> GET /test HTTP/1.1
> Host: 172.16.253.136:8080
> User-Agent: curl/8.7.1
> Accept: */*
>
* Request completely sent off
* HTTP 1.0, assume close after body
< HTTP/1.0 200 OK
< Server: BaseHTTP/0.6 Python/3.12.3
< Date: Mon, 18 Nov 2024 16:11:23 GMT
< Content-Type: application/octet-stream
< Content-Length: 1073741824
<
{ [2240 bytes data]
100 1024M 100 1024M 0 0 35.4M 0 0:00:28 0:00:28 --:--:-- 35.7M
* Closing connection
real 0m28.883s
user 0m1.796s
sys 0m7.423s
#mtu修改回1500。
$ sudo ip link set dev ens33 mtu 1500
$ ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.16.253.136 netmask 255.255.255.0 broadcast 172.16.253.255
inet6 fe80::20c:29ff:fe7a:d769 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:7a:d7:69 txqueuelen 1000 (Ethernet)
RX packets 515461 bytes 34051106 (34.0 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 3139630 bytes 2354811440 (2.3 GB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 92 bytes 7288 (7.2 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 92 bytes 7288 (7.2 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
可以看出MTU改为500后,同样下载1G的文件,耗时为28s,相比于基准数据明显增加**。MTU测试结束后,别忘了将MTU改回原来的值**。
TCP window scale 对性能的影响
接下来我们测试一下 TCP window scale对性能的影响,我们设置MTU为1500,然后观察该情况下关闭 TCP window scale 的请求耗时。
#关闭tcp_window_scaling
$ sudo sysctl -w net.ipv4.tcp_window_scaling=0
net.ipv4.tcp_window_scaling = 0
#发起请求
$ time curl -o /dev/null -v http://172.16.253.136:8080/test
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0* Trying 172.16.253.136:8080...
* Connected to 172.16.253.136 (172.16.253.136) port 8080
> GET /test HTTP/1.1
> Host: 172.16.253.136:8080
> User-Agent: curl/8.7.1
> Accept: */*
>
* Request completely sent off
* HTTP 1.0, assume close after body
< HTTP/1.0 200 OK
< Server: BaseHTTP/0.6 Python/3.12.3
< Date: Mon, 18 Nov 2024 16:14:08 GMT
< Content-Type: application/octet-stream
< Content-Length: 1073741824
<
{ [4344 bytes data]
100 1024M 100 1024M 0 0 32.3M 0 0:00:31 0:00:31 --:--:-- 28.8M
* Closing connection
real 0m31.723s
user 0m1.622s
sys 0m3.431s
#实验结束别忘了打开tcp_window_scaling
$ sudo sysctl -w net.ipv4.tcp_window_scaling=1
可以看到相同MTU下,关闭TCP window scale,请求耗时为31s,相比基线数据也是明显增加。
小结
今天的内容就是这些,我给你准备了一个思维导图回顾要点。

这节课我们从网络模型和协议的角度,探讨了提升性能的方法。
首先,我们分析了五种常见的I/O模型——阻塞式I/O、非阻塞式I/O、I/O复用、信号驱动式I/O和异步I/O。
接着,我们转向网络协议方面,学习了MTU(最大传输单元)和TCP窗口的性能调优。合理的MTU设置能够避免数据分片,从而提高网络传输效率;而TCP的流量控制和拥塞控制机制,如滑动窗口和拥塞窗口,直接影响网络吞吐量。TCP的缓冲区与网络带宽延迟积(BDP)和RTT都是影响性能的重要因素。
此外,我们还讲解了TCP的拥塞控制算法。BBR算法突破了传统的基于丢包的拥塞控制方法,采用带宽和RTT测量,在长肥网络能更有效地提升网络性能。
随后,我们回顾了HTTP/1到HTTP/3的发展过程有哪些性能提升。
最后,通过实验,我们观察了MTU和TCP窗口扩展对性能的影响,进一步加深了对这些网络参数如何优化性能的理解。
思考题
-
TCP 窗口扩展是怎样工作的,你能说出其交互和计算的方法吗?
-
什么是队头阻塞?
欢迎你在留言区和我交流互动,如果这节课对你有启发,也推荐你分享给身边更多朋友。
精选留言
2025-03-05 23:37:33
2025-03-02 17:56:22