你好,我是谢友鹏。
在前面的课程中,我们讨论了通过横向扩展(scale out)的网络架构提升系统性能,但并非所有场景都适合这种方式。
比如“大象流”(在网络中占用大量带宽的长时间持续传输的大数据流量)场景中,如果单台服务器的处理性能不足,那么无论怎么扩展也难以满足需求。还有,近期热门 AI 领域的模型训练网络,虽然可以通过分而治之的算法来并行处理,但大量矩阵运算要求极高的计算关联性,因此除了横向扩展之外,也需要考虑纵向扩展(scale up)。
人们对性能的追求从未停歇,总是希望在任何情况下最大化单台机器的性能表现,让我们从这节课开始提升单机性能之路。
性能优化的三个层次
影响性能的因素可以分为多个层次:
1.代码逻辑性能的第一个瓶颈往往是代码逻辑的效率。低效的代码逻辑,就像一个技术生疏的驾驶员,即使开的是一辆高性能的车,也无法发挥其最大潜力。因此,代码逻辑决定了系统性能的下限。
2.网络模型与协议优化第二个层次是网络模型的选择和网络协议的优化。这就好比一个熟练的驾驶员,不但掌握了驾驶技能,还熟悉车辆原理,能够根据需求对车进行适当配置,使其更加得心应手。
3.单机架构优化第三个层次是架构上的优化。当一个熟练的驾驶员已经将普通车辆的性能发挥到极致,如果想进一步提速,就需要升级到更高性能的车辆。单机架构可以通过 DPDK 、 XDP等技术,减小用户态与内核态切换的开销,也可以通过软硬件结合、RDMA、P4 等技术为 CPU 分担压力。这部分优化决定了单机性能的上限。
在课程中,我们将围绕如何提升单机处理性能,分三节课带你学习性能优化的相关知识,分别对应上述三个优化层次,逐步探讨从代码逻辑到网络模型和协议,再到单机架构的全面优化策略。这节课我们先来关注第一个层面。
常见的低性能逻辑
性能优化并非神秘之事,无非是对系统流程有更深的理解或对某些流程有更强的性能意识,并能够通过合适的手段定位效率低下的环节,从而加以改进。
我们可以主动了解一些常见的误区,提升性能意识,预防低性能代码的产生。后面我梳理了六类影响性能的常见操作,相信了解了这些可以让你日常的应用程序开发工作少踩很多雷点。
第一,不合适的数据处理尺寸,特别是 I/O 操作的尺寸。每次 I/O 操作都会涉及初始化缓冲区、系统调用、上下文切换和地址映射等开销。如果单次处理的数据量过小,处理次数必然增多,从而导致这些额外开销的累计增加。同样,在非 I/O 操作场景中,如果数据处理的粒度与实际需求不匹配,也会造成流程执行次数过多,进而影响整体效率。
为了让你有个直观印象,我给你举个例子。
一个缓存系统,为了将数据缓存到磁盘,在磁盘中创建了很多存储文件,每个文件划分成若干存储单元,所以一个被存储的对象就会被分配到多个存储单元进行文件读写。同一个对象分配到的存储单元可能是不连续的,所以一次只能处理一个存储单元,因此这个例子中数据单次处理尺寸是存储单元的大小。
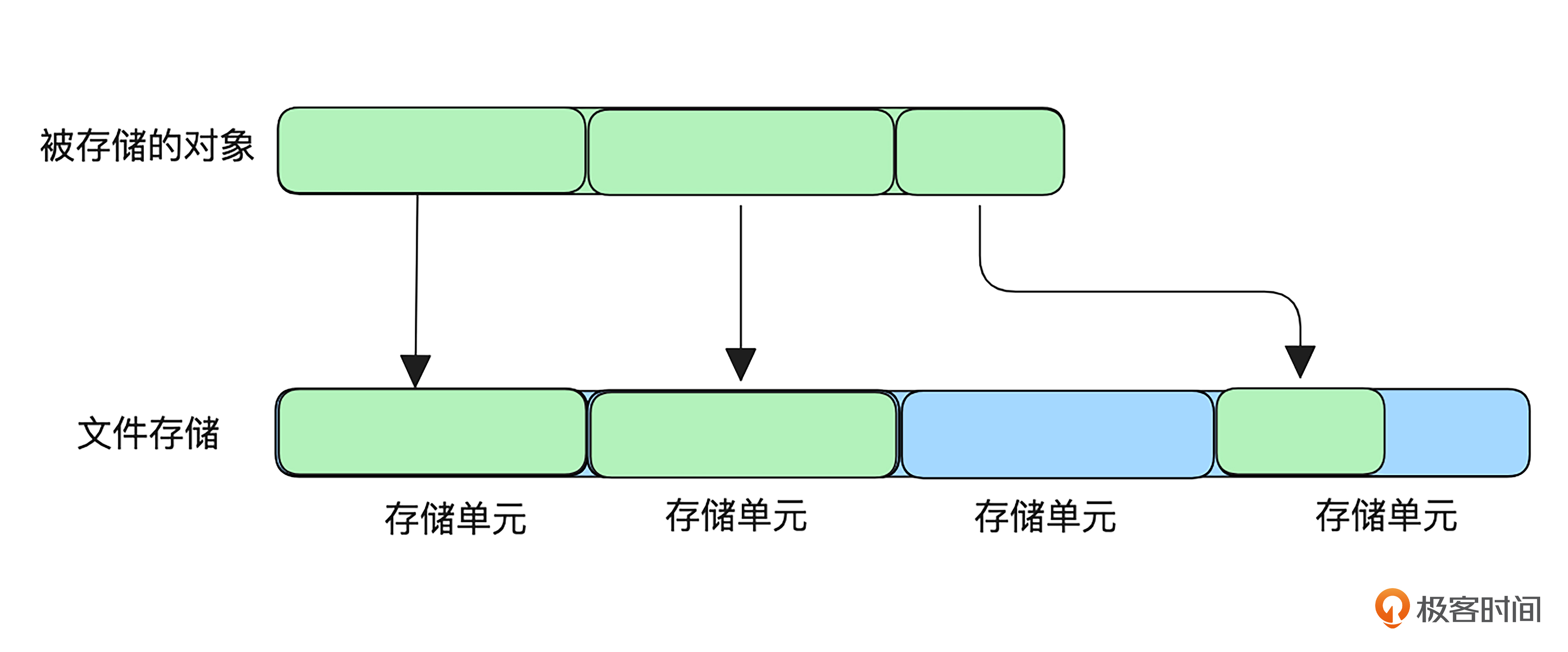
起初,系统主要缓存对象是文本和图片类型,存储单元的尺寸设置较小。随着业务的发展该系统需要缓存视频资源,发现只要同时缓存几个G的视频,CPU就会飙高。原因就和存储单元尺寸有关,如果存储单元设置太小,大文件需要太多次操作,性能下降;如果设置太大,小文件会导致大量空间浪费,因为一旦存储单元被某个对象使用,无论使用了多少,都不能再被其他对象使用。
解决思路就是将大小文件分开缓存,设置不同的存储单元尺寸,性能便会大幅提升。
第二,频繁执行的长遍历。耗时高无非分两种情况,一种是单次执行耗时高,另一种是单次执行耗时不高,但是执行次数非常多。
前者需要我们多关注系统调用,后者要谨防长遍历。如果长遍历指数式爆炸就更恐怖了。
接着刚刚的例子,我们来看一下频繁执行的长遍历会有多么恐怖。我在刚刚缓存的例子中添加了索引,方便我们更直观地分析操作的流程。
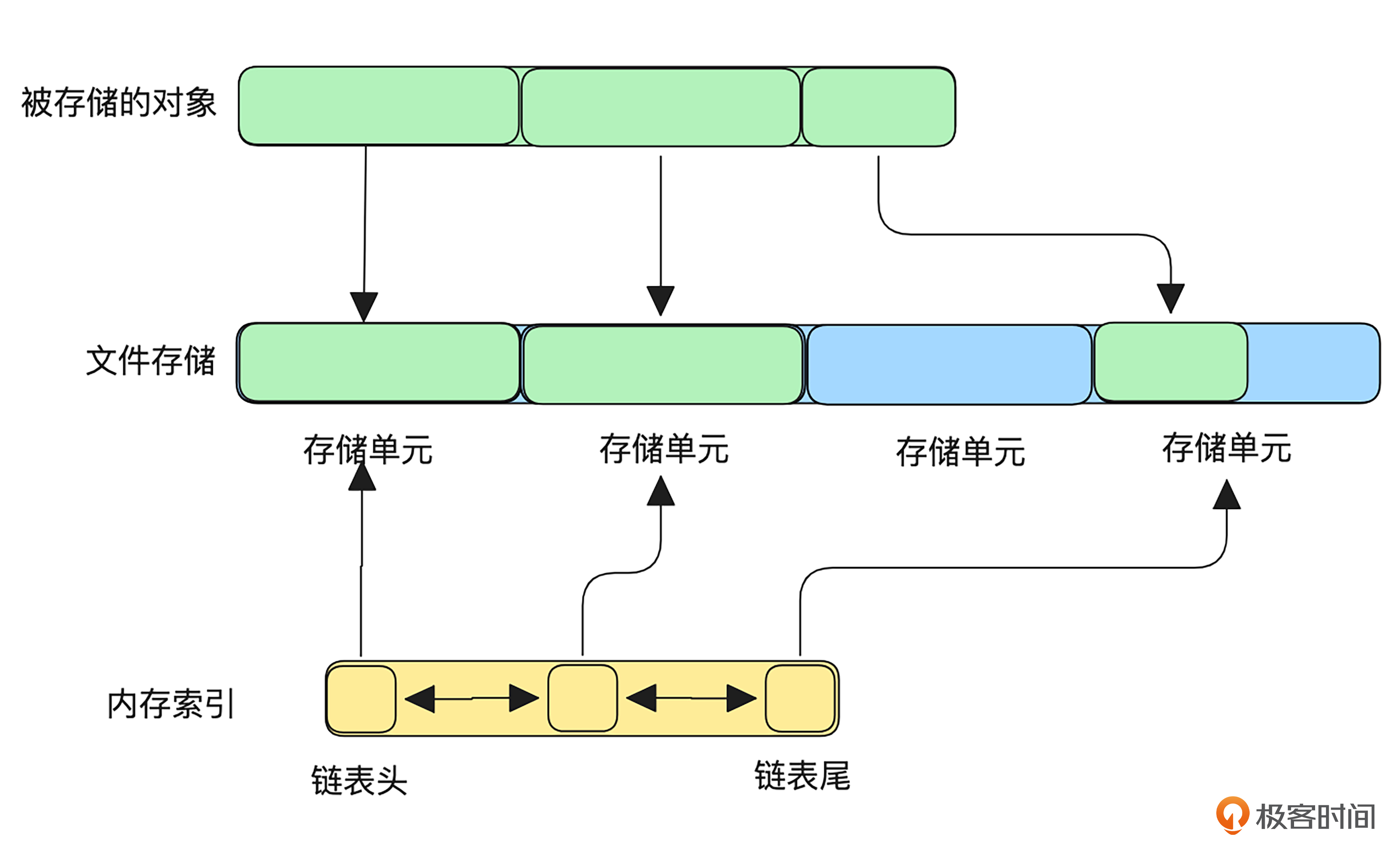
这张图展示了链表的内存结构,链表记录了被存储对象在文件中存储单元的位置,每个节点包含存储单元的大小和索引。
对于较大的存储对象都是读写操作都是分批进行的,每一批操作都需要先在内存的链表中找到资源所在存储单元的索引,然后才能定位到文件的位置,这就造成了每一批数据处理都要用到大量遍历,伪代码如下:
func getStartUnitIndex(startRange)
{
currSize = 0;
for (startNode = head; startNode != tail && currSize < startRange; startNode++) {
currSize = currSize + 存储单元尺寸;
}
return startNode->unitIndex; // 假设节点存储了对应的索引
}
我们不妨估算一下,在以下假设数值下,完成这个对象的读取操作要遍历多少次索引的链表?
-
存储对象大小为 1GB,存储单元大小为 1KB,因此链表的总长度为 1G/1K=1M1G / 1K = 1M1G/1K=1M(即 1048576 个节点)。
-
每次读取 1MB 数据并发送,因此总共需要 1G/1M=1K1G / 1M = 1K1G/1M=1K(1024 批)操作。
在每一批次操作中,为了定位数据的存储单元索引,函数 getStartUnitIndex 需要从链表头开始遍历。每批次的遍历节点数量依次递增:
第 1 批:无需遍历节点(起始即第 0 节点)。
第 2 批:遍历 1M/1K=1K1M / 1K = 1K1M/1K=1K 节点。
第 3 批:遍历 2M/1K=2K2M / 1K = 2K2M/1K=2K 节点。
…
第 1K−11K-11K−1 批:遍历 (1K−2)M/1K=(1K−2)K(1K-2)M / 1K = (1K-2)K(1K−2)M/1K=(1K−2)K 节点。
链表遍历次数总计为:
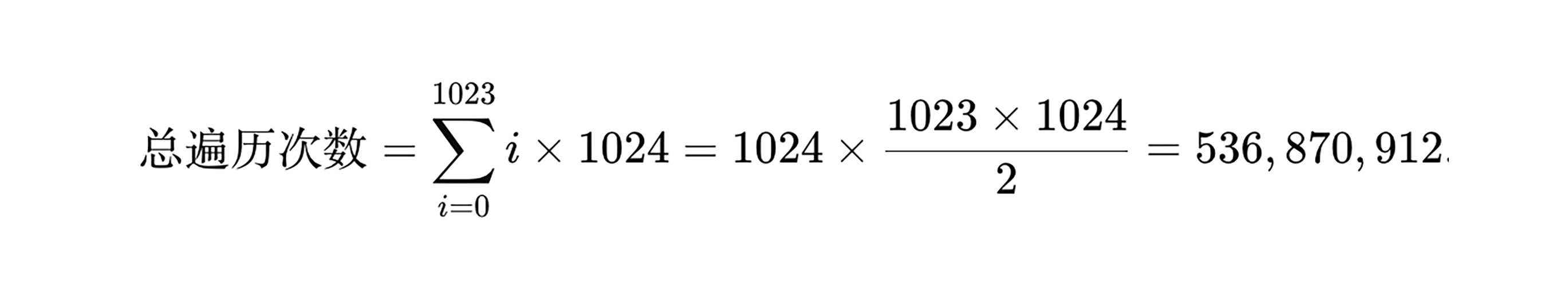
因此,在上述配置下,处理 1GB 数据的链表遍历次数达到 约 5.37 亿次,性能损耗极为严重。
或许你会问,既然为什么不记录最后一次索引的位置,而是从头计算呢?
这里有两个原因。首先,这个系统最初是针对小对象来设计的。如果把存储对象从1G换成10k推演一下,遍历节点的量级一下子就少了很多,因此,以前并不会暴露出性能问题。
其次,客户端本来就可以发起range请求,这种情况无法根据上一次位置进行记录。根本解决办法是避免过长遍历,比如使用跳表进行优化,同时需要让存储单元的大小和存储对象大小量级相匹配。
第三,耗时且可并发的操作未并发运行。比如CDN处理一批资源的预热任务(将一批资源从源站提前拉取到CDN进行缓存)。如果写成后面这样,就会比较低效:
func 处理一批资源的预推
for 资源 in 遍历资源列表
去源站拉取一个资源并加载
因为“去源站拉取一个资源并加载”这个动作显然是个耗时操作,而且多个资源拉取也没有关联关系。
如果改成这种写法效果就不一样了。
func 处理一批资源的预推
for 资源 in 遍历资源列表
if 获取到并发池的资源
并发 去源站拉取一个资源并加载
等待所有并行操作完成
这里的并发池可以是线程池、协程池等,我们需要注意即使能并发的地方也要用“池”去限制并发大小,而不是无限并发,因为并发单元的调度也是要消耗资源的。
第四,不合适的锁阻碍并发。并发常见我们需要用锁对共享资源做互斥保护,但是如果锁用得不当,就会造成性能瓶颈。常见性能误区为加锁粒度过大,可以用读锁的地方用成了写锁等。另外锁住资源后的一定要避免耗时操作。
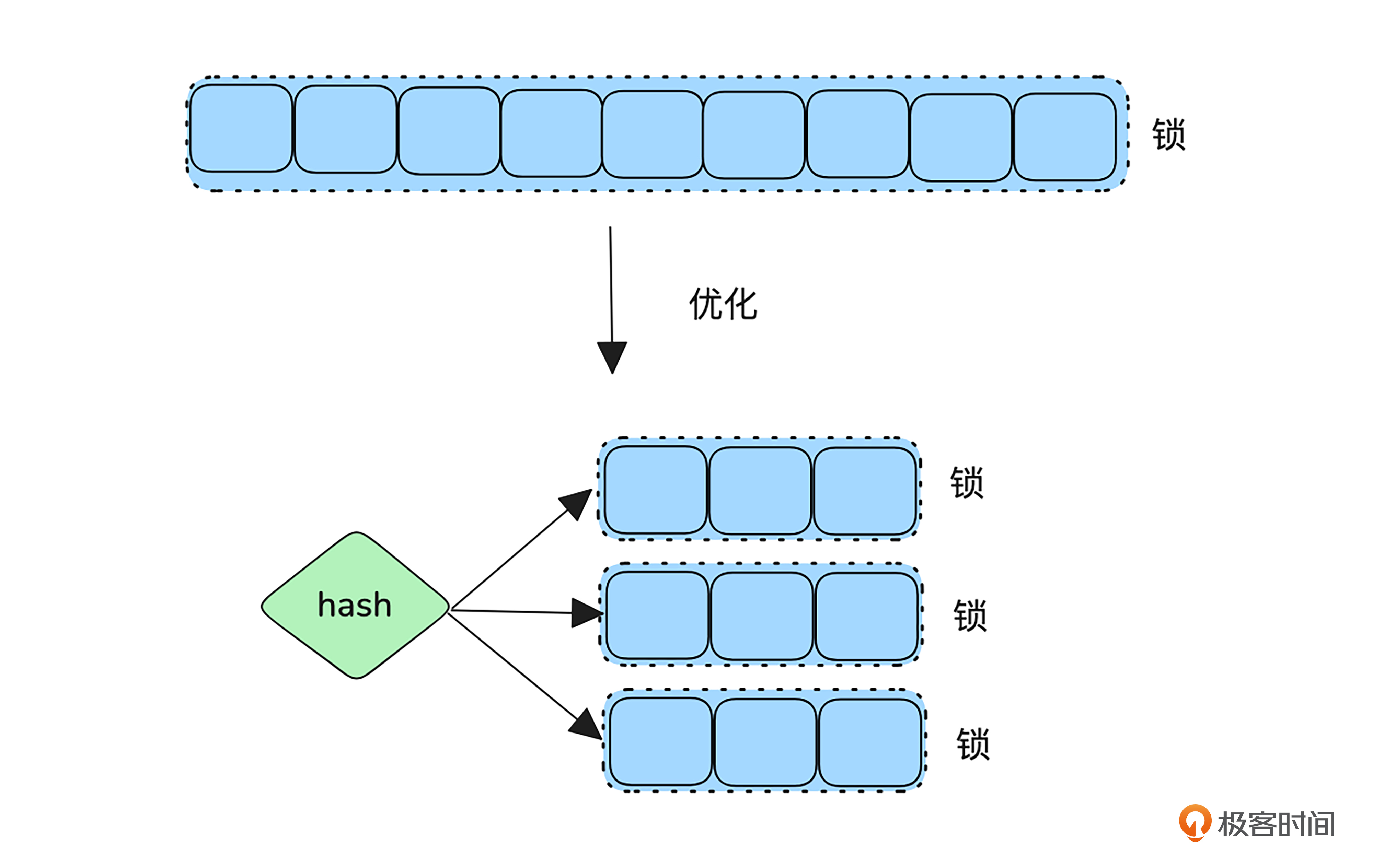
除了避免低级的设计导致锁的粒度过大外,一些场景还可以用分区的方式对锁的粒度进行分散。
第五,大数据未进行流式处理。例如,当一个 CDN 缓存节点处理未命中的大文件时,如果选择将整个文件从源站下载完后再返回给客户端,不仅会延长客户端的等待时间,还会占用大量缓存资源,降低其他请求的命中率。
更高效的方式是采用流式处理。从源站读取一部分数据后立即缓存并同步回复给客户端。这样可以一边加载缓存,一边满足客户端的请求。流式处理不仅减少了客户端的等待时间,还能提高缓存命中率,因为其他请求在下载尚未完成的时候,即可开始命中部分已缓存的数据。
第六,轮询。轮询本质上是重复性地查询某个状态,而大多数查询可能都是无效的,这不仅浪费资源,还可能因为查询间隔错过事件发生的时机,导致额外的等待时间。
更高效的替代方案是采用事件驱动的监听或推送机制。例如,在网络编程中,常用的异步 I/O 多路复用技术(如 epoll)就是这一思路的具体实现。通过监听事件并在触发时立即响应,系统能够显著降低资源消耗,同时提升对事件处理的及时性和整体性能。
刚刚,我列出了代码逻辑中几种常见的低效写法,但低效的逻辑远不止这些。例如,不必要的内存深拷贝、频繁申请和释放内存、主流程调度时出现阻塞,甚至是低级错误导致的死循环等。虽然无法列举所有问题,但希望前面这些示例能提升你的性能意识,激发优化思路。
此外,还有一些常见的性能提升方法,比如使用跳表优化遍历、使用缓存优化查询、使用缓冲区适应前后端网络性能不匹配、处理器绑定以及使用非阻塞IO函数等,我们可以在实际工作中尝试应用这些方法。
怎样定位性能问题
我们前面讨论了这么多低性能的代码逻辑,既是为了预防写出低效的代码,也是希望为你提供一些面对性能问题时的解决思路。
不过这些更多依赖于长年的工作经验,很多时候更让我们头疼的是只能看到系统性能低下,却找不到问题出在哪。因此我们还需要掌握一些性能问题定位的基础知识。
问题定位的基本逻辑通常是:收集信息、做出假设、验证假设,如果做出错误的假设,则重新推断或重复以上步骤。
关于性能定位的方法论,我推荐性能大神Brendan Gregg的USE方法。所谓USE分别对应以下三点内容:
1.Utilization(利用率):反映资源的繁忙程度。例如,大量计算密集型任务可能会导致 CPU 利用率高,这被称为“on-CPU 消耗”。
2.Saturation(饱和度):反映资源的排队情况。除了资源不足以满足需求,导致其他任务无法获得资源外,还可能是任务被锁阻塞,或者系统调度过于频繁等原因。对于 I/O 密集型任务,除了关注利用率外,还需要分析饱和度,这就是 Off-CPU 分析。
3.Errors(错误):反映系统中出现的错误情况。
这里面的利用率和饱和度是系统资源的度量指标,我们常常关注的系统资源包括CPU、内存、网络和磁盘这几项。
USE方法中,错误最为直观,所以遇到性能问题我一般先检查错误,比如通过dmesg查看有没有OOM、segment fault等错误,查看日志有没有错误或意料之外的流程。
其次,我会观察系统资源的利用率,如top,观察CPU的利用率、内存的利用率等。如果是CPU利用率高,还需要进一步查看是用户态高还是内核态高,同时io wait是否变高,并通过perf等采样工具查看究竟是哪些函数导致CPU利用率高。如果问题路径和磁盘有关联,可以df -h,查看磁盘利用率,通过iostat观察IO读写情况等。
最后,我会观察系统资源的饱和度。如通过vmstat观察cpu的饱和程度,其中r后面的数字表示 可运行的进程数(包括正在运行或等待运行的任务)。b后面的数字表示被阻塞的进程数(等待 I/O 完成的任务)。
关于USE的各种指标查看方法我就不一一列举了,大家可以参考该方法创作者总结的Linux上使用USE方法指标观察的 Checklist。
另外,我列出《性能之巅》中关于Linux性能定位60s的建议命令,供你参考:
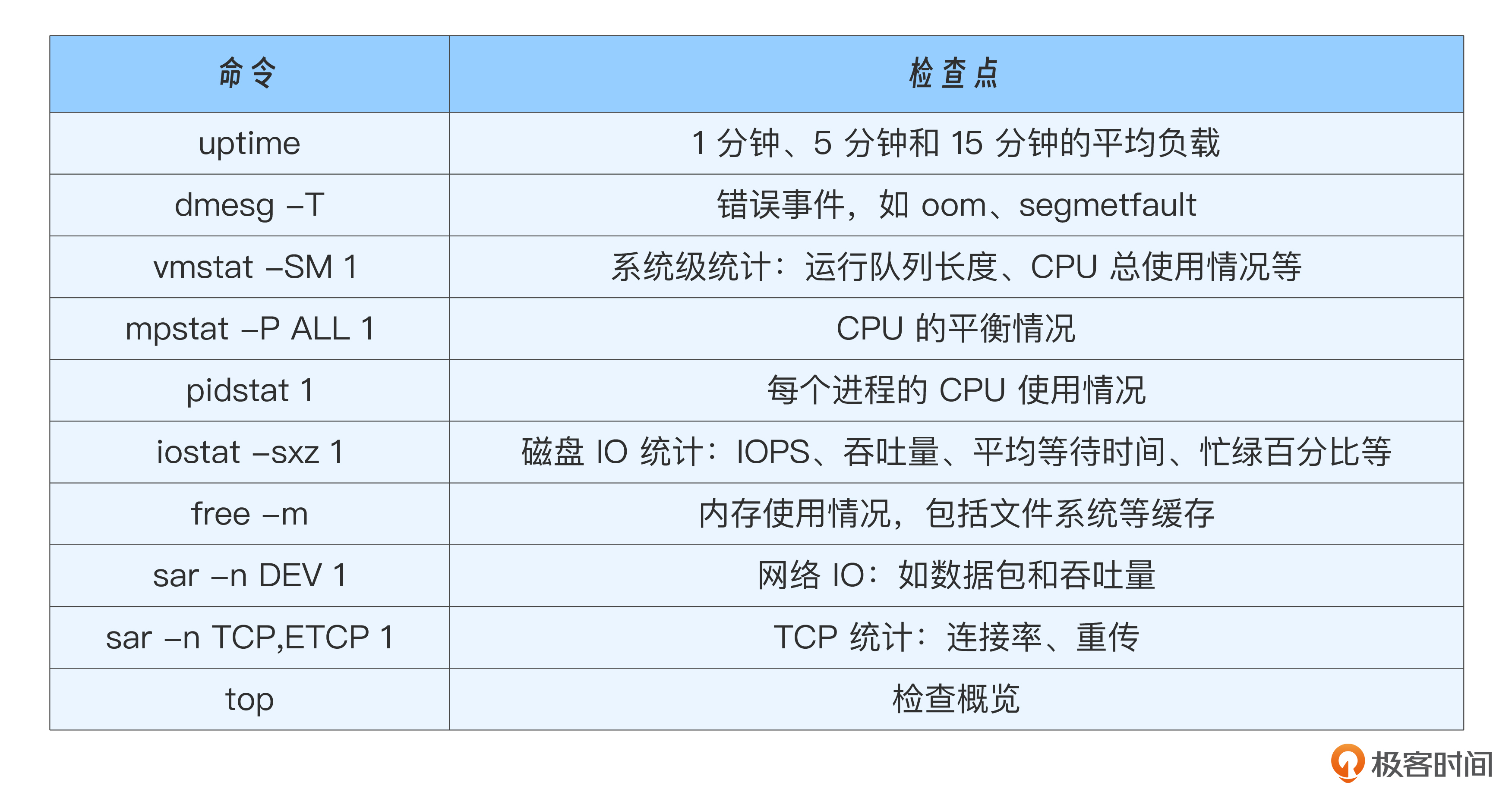
市面上的性能分析工具太多了,我再按照功能给你列举几个我自己常用的工具:
-
采样工具:perf 配合 FlameGraph 可以生成火焰图,直观展示 CPU 使用情况。
-
快速观察系统调用情况:strace 。
-
快速观察堆栈情况:pstack。
-
网络状况快速查看工具,如ss、netstat、ifconfig、httpstat等。
-
网络分析最不可缺少的工具:Wireshark 。
另外一些高级语言有特定的性能分析工具,如 Golang的pprof,在采样生成火焰图、观察堆栈情况时候更加方便。
关于问题定位,我要提醒你注意要多进行信息收集,防止误导性的数据导致定位方向跑偏。尤其是使用采样类工具的时候,注意多采集几次再做出假设。
定位低性能代码实战
光说不练假把式,原理和方法的充电环节告一段落,为了让你学以致用,加深印象,我们来进行一些实战练习。
优化前耗时测试
首先请你下载并编译后面的代码(这段代码我特意留下了一堆坑),链接是 before_optimization/boring_http_server.c 。然后我们启动server,该server监听http80端口,收到客户端请求时会生成1G文件发送给客户端。
#编译
gcc boring_http_server.c -o boring_http_server -lm
#启动
sudo ./boring_http_server
然后我们测试一下请求耗时,发现耗时长达7分多钟。
$ time curl -o /dev/null -v http://172.16.253.135/test
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0* Trying 172.16.253.135:80...
* Connected to 172.16.253.135 (172.16.253.135) port 80
> GET /test HTTP/1.1
> Host: 172.16.253.135
> User-Agent: curl/8.5.0
> Accept: */*
>
0 0 0 0 0 0 0 0 --:--:-- 0:00:10 --:--:-- 0< HTTP/1.1 200 OK
< Content-Type: application/octet-stream
< Content-Length: 1073741824
<
0 1024M 0 0 0 0 0 0 --:--:-- 0:00:10 --:--:-- 0{ [920 bytes data]
100 1024M 100 1024M 0 0 2303k 0 0:07:35 0:07:35 --:--:-- 2221k
* Connection #0 to host 172.16.253.135 left intact
real 7m35.211s
user 0m20.640s
sys 2m20.674s
你可以先结合前面所学,考虑一下这些代码我们该如何优化,然后再继续往下看,这样更容易找到自己的疏漏点。
性能分析
按照前面的方法,我们首先要使用 top查看系统概览。
top - 14:00:18 up 3:21, 4 users, load average: 0.98, 0.77, 0.53
Tasks: 229 total, 2 running, 227 sleeping, 0 stopped, 0 zombie
%Cpu(s): 10.3 us, 29.8 sy, 0.0 ni, 49.4 id, 0.0 wa, 0.0 hi, 10.5 si, 0.0 st
MiB Mem : 3868.2 total, 1852.0 free, 806.3 used, 1456.9 buff/cache
MiB Swap: 1962.0 total, 1962.0 free, 0.0 used. 3061.9 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2462 root 20 0 1051260 249704 1280 R 100.0 6.3 3:48.77 boring_http_ser
从load average一行能看出系统1分钟、5分钟和15分钟的平均负载,这里的经验值是平均load大于0.7 * CPU核数才需要引起重视,而我的是2核系统,所以都并不算高。
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2462 root 20 0 1051260 249704 1280 R 100.0 6.3 3:48.77 boring_http_ser
从这一行可以看出进程 boring_http_server(进程名字太长被top时候截断了) 使用了 100% 的 CPU。
%Cpu(s): 10.3 us, 29.8 sy, 0.0 ni, 49.4 id, 0.0 wa, 0.0 hi, 10.5 si, 0.0 st
这一行在分析CPU性能问题时候非常重要,我们依次梳理一下这些缩写的含义:
-
us (user): 10.3% - CPU 正在执行用户空间进程的时间。相对较低,表明系统中的大部分计算是由内核空间进程占用。
-
sy (system):29.8% - CPU 正在执行内核空间进程的时间。这个值相对较高,说明系统正频繁进行系统调用或处理内核操作(如 I/O、文件系统操作)。
-
ni (nice):0.0% - 优先级调整过的进程所占用的 CPU 时间。
-
id (idle):49.4% - CPU 空闲时间。差不多有一半的时间 CPU 没有被使用。
-
wa (waiting):0.0% - CPU 等待 I/O 操作的时间。
-
hi (hardware interrupts):0.0% - 处理硬件中断的 CPU 时间。
-
si (software interrupts):10.5% - CPU 用于处理软件中断的时间。软件中断通常由内核生成,用于处理一些事件,如网络请求等,较高的值可能表明有频繁的系统调用。
-
st (steal): 0.0% - 虚拟化环境中,其他虚拟机占用的 CPU 时间。
综合上面的指标我们可以看出,系统的负载适中,但内核层面的操作(29.8% 的系统 CPU 使用)占用了较多 CPU 时间,可能和io操作有关。尤其要注意的是boring_http_server占用了大量CPU,需要我们进一步分析。
既然是和boring_http_server操作内核相关CPU消耗较高,我们可以先通过strace观察一下系统调用情况。这里可以看出4.951745s的采样期间,sendto系统调用被执行了264596次,平均执行时间为18微秒,没有发生错误。
#这个命令从执行下去就开始采样,知道ctrl+c结束,结束采样,显示统计。
$ sudo strace -c -p $(pidof boring_http_server)
strace: Process 3443 attached
^Cstrace: Process 3443 detached
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
100.00 4.951745 18 264596 sendto
------ ----------- ----------- --------- --------- ----------------
100.00 4.951745 18 264596 total
这里的重点是带你体验性能排查的完整过程,所以我们假设采样到了足够的信息,且确定了下一步排查方向就是boring_http_server。不过真实的业务场景里情况可能更为复杂,课后你可以多尝试一些命令收集信息练练手。
好,我们回到正题。既然已经知道了boring_http_server占用CPU较多,我们可以直接用perf采样分析一下boring_http_server进程。
先来安装perf。
#ubuntu上安装perf,并查看版本
$ sudo apt install linux-tools-$(uname -r)
$ perf -v
perf version 6.8.12
然后使用perf观察一下boring_http_server进程哪些函数出现频率高。
#使用perf找出这个进程中占用较高的函数调用栈。
sudo perf top -g -p $(pidof boring_http_server)
这里面我们可以看到一些这样的[kernel] 内核的函数,它们可以帮我们看清楚是哪些流程占用的CPU高。
93.66% 0.07% [kernel] [k] tcp_sendmsg
另外,也需要持续找一些和我们进程相关的函数,看是哪些流程调用导致内核函数占用CPU变高的。比如后面两个函数。
19.75% 0.20% boring_http_server [.] handle_get_request
#这个函数不是总能看到,要多观察一会,注意抓取信息
1.49% 0.60% boring_http_server [.] write_file_char_by_char
注意这时观察到数据是动态的,每个时刻观察的函数可能不同,需要耐心多观察一段时间。如果你幸运地的发现,一些函数不应该出现在这,恭喜你,可能快找到优化点了,可以分析代码,然后验证了。
如果流程比较复杂,我们还可以生成火焰图来观察。
#对boring_http_server进程进行60s的采样。
sudo perf record -F 99 -p $(pidof boring_http_server) -g -- sleep 60
#这时候sudo perf report 可以查看分析结果,不过没有火焰图直观。
#将采样数据转换成格式
sudo perf script > out.perf
#下载工具
git clone https://github.com/brendangregg/FlameGraph.git
#生成火焰图
cd FlameGraph/
./stackcollapse-perf.pl out.perf > out.folded
./flamegraph.pl out.folded > test.svg
#用chrome打开test.svg
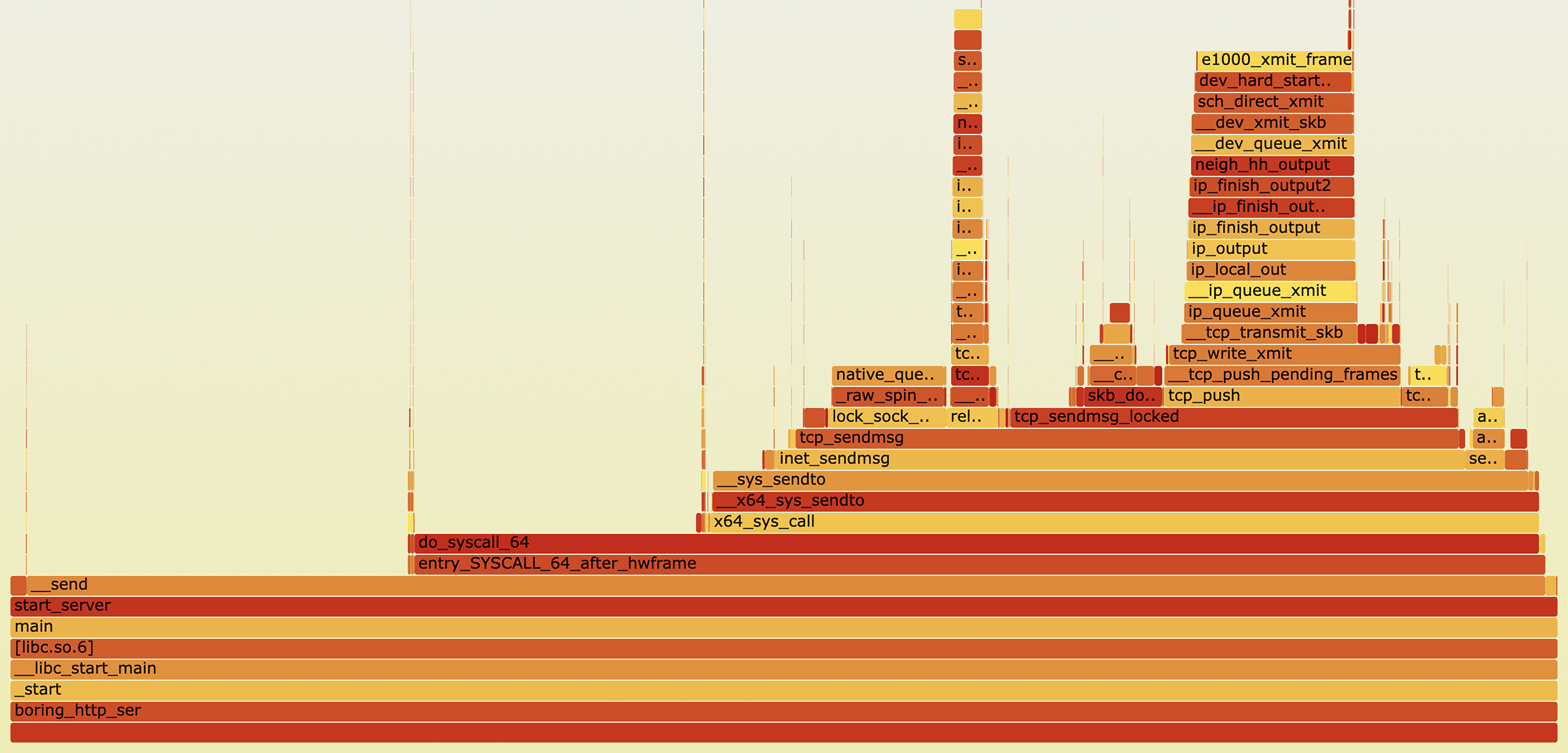
观察火焰图以后,我们可能并未发现什么异常,而且流程都在send上,所以我们下一步就需要看看send相关代码。
可以发现send的buf只有128字节,这个设置太小了,我们将它调整成64k再测试看看。
首次优化
调整为#define BUF_SIZE (64 * 1024) 之后,重复上面流程,可以发现请求耗时大幅下降到几十秒了。如果观察仔细的话,可以发现请求开始一段时间cpu使用率接近100%,后面突然大幅下降。
$ time curl -o /dev/null -s http://172.16.253.135/test
real 0m25.979s
user 0m0.990s
sys 0m3.357s
为了让采样信息更有效,同时争取点动手操作的时间,我们顺序请求100次。
seq 1 100 | xargs -I {} curl -o /dev/null -s http://172.16.253.135/test
然后进行perf采样,并生成火焰图。
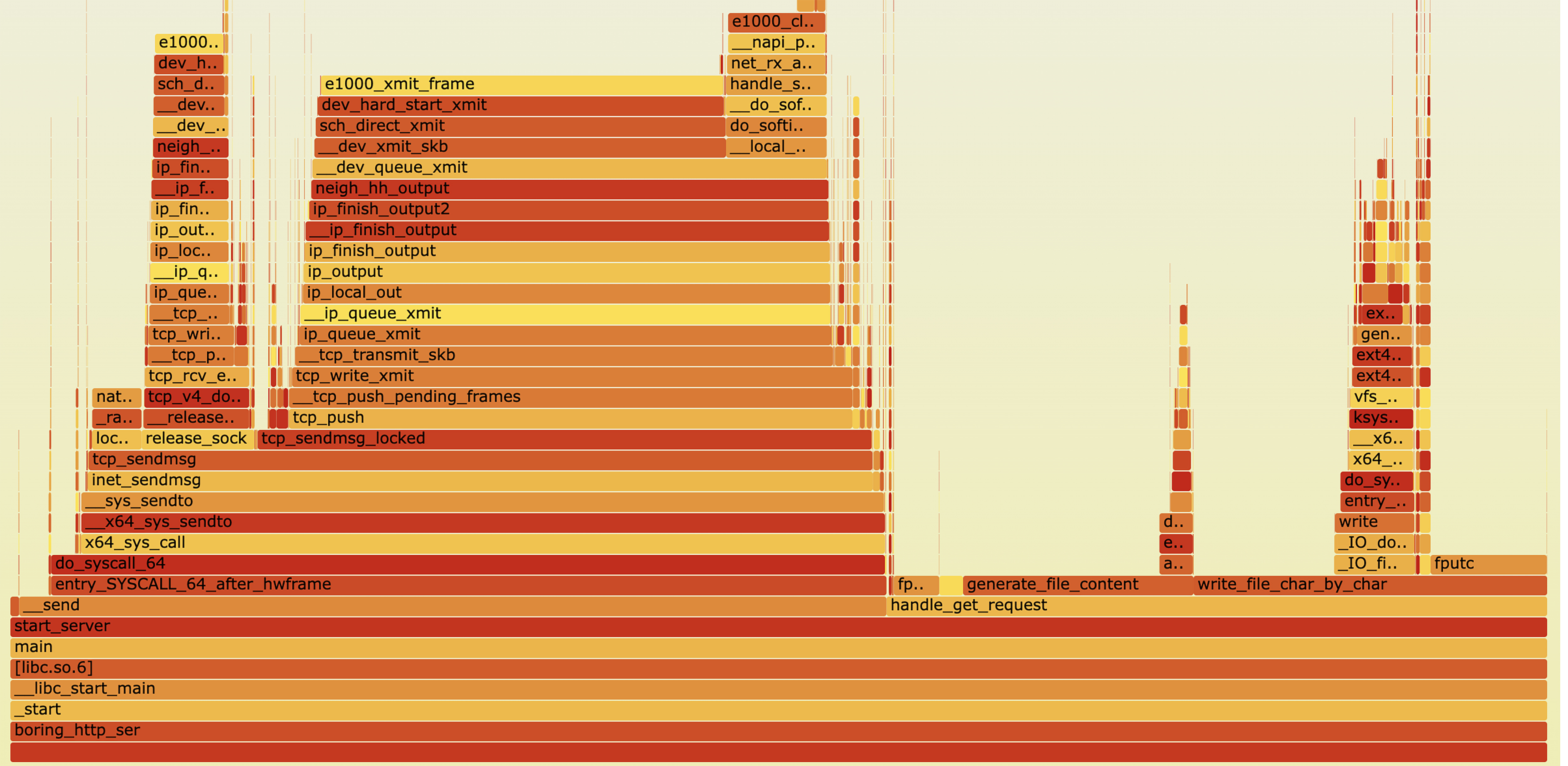
从前面的火焰图我们可以看到,generate_file_content和write_file_char_by_char函数出现频率有些高,另外发送数据的函数占用较多。围绕这三个函数梳理代码可以发现以下可优化点:
-
write_file_char_by_char写法本身效率较低,每次只写1个字符到文件,既用了大量变量,又多了非常多次系统调用。
-
generate_file_content是一个非常耗时的操作,本不应该出现在请求处理流程中,而是提前生成好,每次请求直接使用数据。
-
对于大文件应该进行流式处理,而不是等拿到所以数据再返回给客户端。
再次优化
优化后的文件为after_optimization/boring_http_server.c,再次测试可以发现,经过这次优化后,请求处理阶段的 CPU 使用率不再飙升至 100%。
不过你可能会有新的疑问——这是否是一种“作弊”行为?因为在系统启动时,依然需要执行generate_and_write_file_content,这会导致启动阶段的 CPU 使用率仍然较高。
这是因为网络系统的启动阶段和请求处理阶段是完全不同的概念。启动阶段只有一次,即使有性能问题,也可以通过关闭流量来规避,待系统启动完成后再逐步切入流量即可。而请求处理阶段则属于系统的工作状态,必须确保流程高效,以稳定地应对实际的业务需求。
小结
今天的内容就是这些,我给你准备了一个思维导图回顾要点。
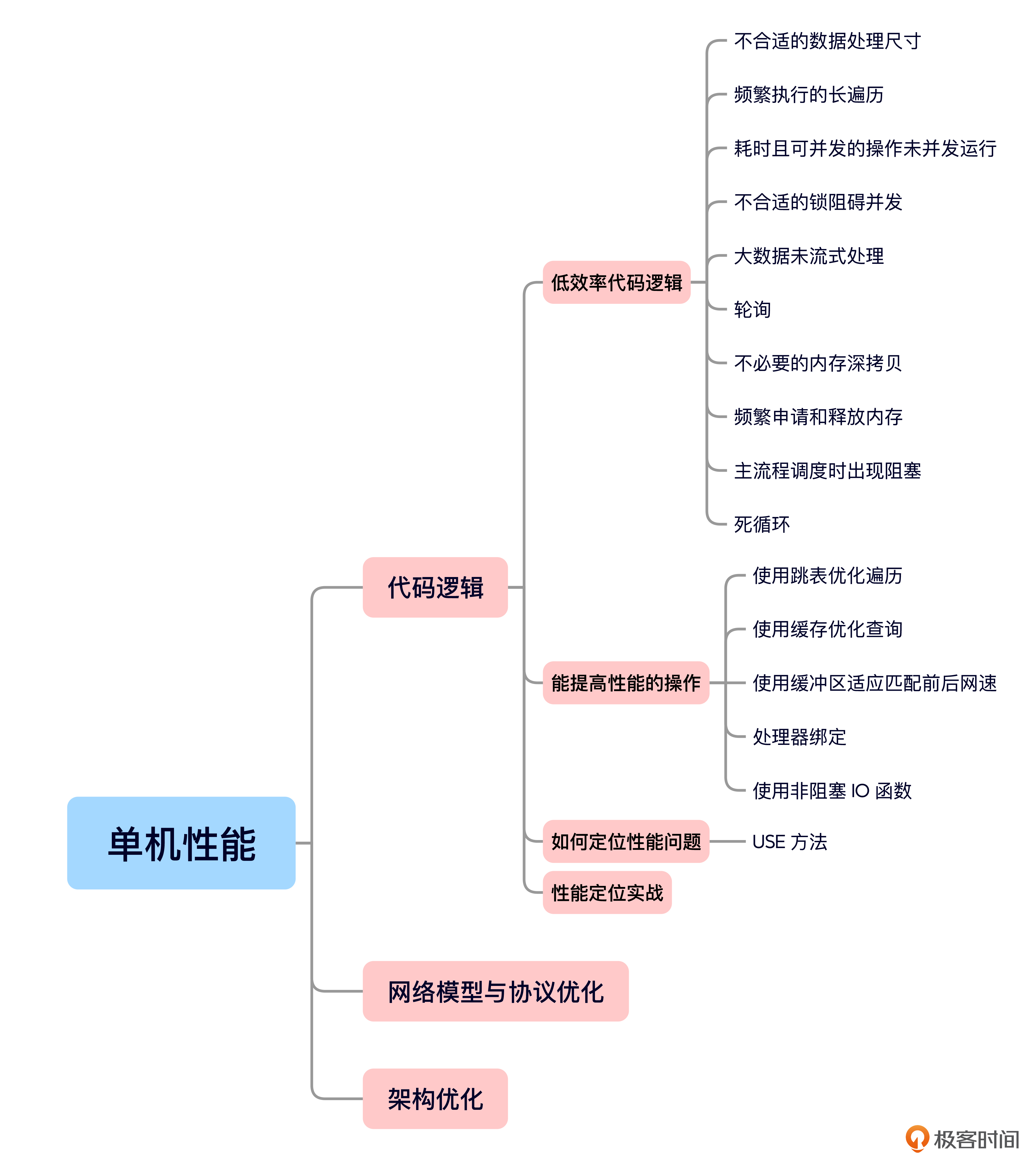
单机性能优化可以从三个层次进行——代码逻辑优化、网络模型与协议优化,以及架构优化。今天的课程主要聚焦于代码逻辑的性能优化。
关于性能问题,我认为预防比解决更重要,期望我们可以防患于未然,这远比成为救火队员好得多。
为了培养你的性能优化意识,我们今天学习了一些常见的低效代码和性能提升技巧。
接着,我们还掌握了“USE”问题定位方法。对于性能问题,我们可以通过分析资源使用率、饱和度和错误来定位系统性能瓶颈,并结合 strace、pstack、perf 等工具进行深入诊断。
最后,通过一个性能定位实验,我们进行了实际操作,巩固所学内容。
关于性能优化,我最后还想给出两点建议:第一,应用二八原则,在系统中可能存在众多性能问题时,优先解决最关键的问题;第二,在定位问题时,要尽量收集全面的信息,确保在做出假设之前进行充分评估,避免方向偏离。
下节课,我们将探讨“网络模型与协议优化”在单机性能提升中的作用,欢迎继续学习。
思考题
- 实验中send函数的单次传入的数据量越大,效率一定越高吗?
- 此次实验你还能想到什么继续优化的地方?
拓展阅读
关于性能,推荐一本书《性能之巅》以及该作者的技术博客。
精选留言
2025-05-20 11:30:02
2025-03-07 09:17:37