今天我来带你进行EM的实战。上节课,我讲了EM算法的原理,EM算法相当于一个聚类框架,里面有不同的聚类模型,比如GMM高斯混合模型,或者HMM隐马尔科夫模型。其中你需要理解的是EM的两个步骤,E步和M步:E步相当于通过初始化的参数来估计隐含变量,M步是通过隐含变量来反推优化参数。最后通过EM步骤的迭代得到最终的模型参数。
今天我们进行EM算法的实战,你需要思考的是:
-
如何使用EM算法工具完成聚类?
-
什么情况下使用聚类算法?我们用聚类算法的任务目标是什么?
-
面对王者荣耀的英雄数据,EM算法能帮助我们分析出什么?
如何使用EM工具包
在Python中有第三方的EM算法工具包。由于EM算法是一个聚类框架,所以你需要明确你要用的具体算法,比如是采用GMM高斯混合模型,还是HMM隐马尔科夫模型。
这节课我们主要讲解GMM的使用,在使用前你需要引入工具包:
from sklearn.mixture import GaussianMixture
我们看下如何在sklearn中创建GMM聚类。
首先我们使用gmm = GaussianMixture(n_components=1, covariance_type=‘full’, max_iter=100)来创建GMM聚类,其中有几个比较主要的参数(GMM类的构造参数比较多,我筛选了一些主要的进行讲解),我分别来讲解下:
1.n_components:即高斯混合模型的个数,也就是我们要聚类的个数,默认值为1。如果你不指定n_components,最终的聚类结果都会为同一个值。
2.covariance_type:代表协方差类型。一个高斯混合模型的分布是由均值向量和协方差矩阵决定的,所以协方差的类型也代表了不同的高斯混合模型的特征。协方差类型有4种取值:
-
covariance_type=full,代表完全协方差,也就是元素都不为0;
-
covariance_type=tied,代表相同的完全协方差;
-
covariance_type=diag,代表对角协方差,也就是对角不为0,其余为0;
-
covariance_type=spherical,代表球面协方差,非对角为0,对角完全相同,呈现球面的特性。
3.max_iter:代表最大迭代次数,EM算法是由E步和M步迭代求得最终的模型参数,这里可以指定最大迭代次数,默认值为100。
创建完GMM聚类器之后,我们就可以传入数据让它进行迭代拟合。
我们使用fit函数,传入样本特征矩阵,模型会自动生成聚类器,然后使用prediction=gmm.predict(data)来对数据进行聚类,传入你想进行聚类的数据,可以得到聚类结果prediction。
你能看出来拟合训练和预测可以传入相同的特征矩阵,这是因为聚类是无监督学习,你不需要事先指定聚类的结果,也无法基于先验的结果经验来进行学习。只要在训练过程中传入特征值矩阵,机器就会按照特征值矩阵生成聚类器,然后就可以使用这个聚类器进行聚类了。
如何用EM算法对王者荣耀数据进行聚类
了解了GMM聚类工具之后,我们看下如何对王者荣耀的英雄数据进行聚类。
首先我们知道聚类的原理是“人以群分,物以类聚”。通过聚类算法把特征值相近的数据归为一类,不同类之间的差异较大,这样就可以对原始数据进行降维。通过分成几个组(簇),来研究每个组之间的特性。或者我们也可以把组(簇)的数量适当提升,这样就可以找到可以互相替换的英雄,比如你的对手选择了你擅长的英雄之后,你可以选择另一个英雄作为备选。
我们先看下数据长什么样子:

这里我们收集了69名英雄的20个特征属性,这些属性分别是最大生命、生命成长、初始生命、最大法力、法力成长、初始法力、最高物攻、物攻成长、初始物攻、最大物防、物防成长、初始物防、最大每5秒回血、每5秒回血成长、初始每5秒回血、最大每5秒回蓝、每5秒回蓝成长、初始每5秒回蓝、最大攻速和攻击范围等。
具体的数据集你可以在GitHub上下载:https://github.com/cystanford/EM_data。
现在我们需要对王者荣耀的英雄数据进行聚类,我们先设定项目的执行流程:
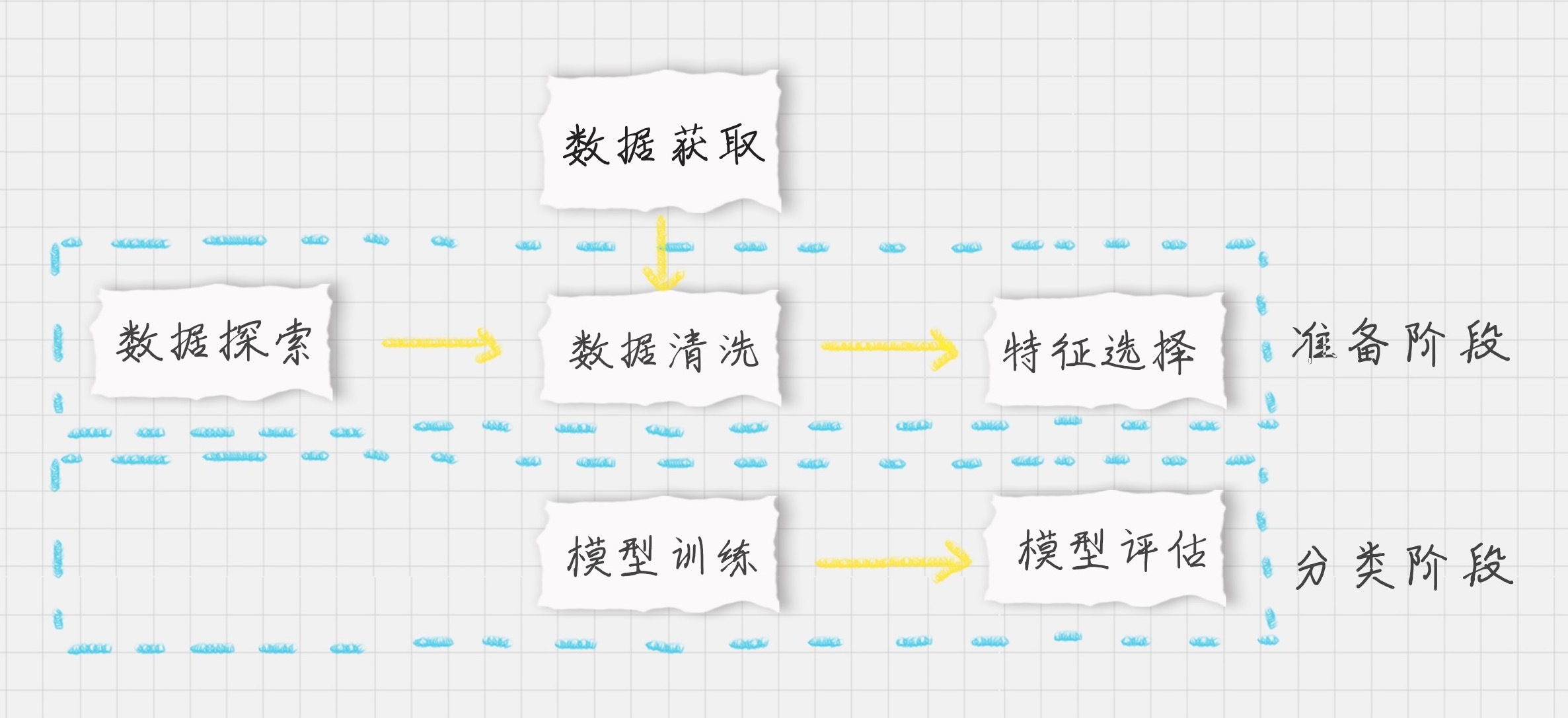
-
首先我们需要加载数据源;
-
在准备阶段,我们需要对数据进行探索,包括采用数据可视化技术,让我们对英雄属性以及这些属性之间的关系理解更加深刻,然后对数据质量进行评估,是否进行数据清洗,最后进行特征选择方便后续的聚类算法;
-
聚类阶段:选择适合的聚类模型,这里我们采用GMM高斯混合模型进行聚类,并输出聚类结果,对结果进行分析。
按照上面的步骤,我们来编写下代码。完整的代码如下:
# -*- coding: utf-8 -*-
import pandas as pd
import csv
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.mixture import GaussianMixture
from sklearn.preprocessing import StandardScaler
# 数据加载,避免中文乱码问题
data_ori = pd.read_csv('./heros7.csv', encoding = 'gb18030')
features = [u'最大生命',u'生命成长',u'初始生命',u'最大法力', u'法力成长',u'初始法力',u'最高物攻',u'物攻成长',u'初始物攻',u'最大物防',u'物防成长',u'初始物防', u'最大每5秒回血', u'每5秒回血成长', u'初始每5秒回血', u'最大每5秒回蓝', u'每5秒回蓝成长', u'初始每5秒回蓝', u'最大攻速', u'攻击范围']
data = data_ori[features]
# 对英雄属性之间的关系进行可视化分析
# 设置plt正确显示中文
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
# 用热力图呈现features_mean字段之间的相关性
corr = data[features].corr()
plt.figure(figsize=(14,14))
# annot=True显示每个方格的数据
sns.heatmap(corr, annot=True)
plt.show()
# 相关性大的属性保留一个,因此可以对属性进行降维
features_remain = [u'最大生命', u'初始生命', u'最大法力', u'最高物攻', u'初始物攻', u'最大物防', u'初始物防', u'最大每5秒回血', u'最大每5秒回蓝', u'初始每5秒回蓝', u'最大攻速', u'攻击范围']
data = data_ori[features_remain]
data[u'最大攻速'] = data[u'最大攻速'].apply(lambda x: float(x.strip('%'))/100)
data[u'攻击范围']=data[u'攻击范围'].map({'远程':1,'近战':0})
# 采用Z-Score规范化数据,保证每个特征维度的数据均值为0,方差为1
ss = StandardScaler()
data = ss.fit_transform(data)
# 构造GMM聚类
gmm = GaussianMixture(n_components=30, covariance_type='full')
gmm.fit(data)
# 训练数据
prediction = gmm.predict(data)
print(prediction)
# 将分组结果输出到CSV文件中
data_ori.insert(0, '分组', prediction)
data_ori.to_csv('./hero_out.csv', index=False, sep=',')
运行结果如下:

[28 14 8 9 5 5 15 8 3 14 18 14 9 7 16 18 13 3 5 4 19 12 4 12
12 12 4 17 24 2 7 2 2 24 2 2 24 6 20 22 22 24 24 2 2 22 14 20
14 24 26 29 27 25 25 28 11 1 23 5 11 0 10 28 21 29 29 29 17]
同时你也能看到输出的聚类结果文件hero_out.csv(它保存在你本地运行的文件夹里,程序会自动输出这个文件,你可以自己看下)。
我来简单讲解下程序的几个模块。
关于引用包
首先我们会用DataFrame数据结构来保存读取的数据,最后的聚类结果会写入到CSV文件中,因此会用到pandas和CSV工具包。另外我们需要对数据进行可视化,采用热力图展现属性之间的相关性,这里会用到matplotlib.pyplot和seaborn工具包。在数据规范化中我们使用到了Z-Score规范化,用到了StandardScaler类,最后我们还会用到sklearn中的GaussianMixture类进行聚类。
数据可视化的探索
你能看到我们将20个英雄属性之间的关系用热力图呈现了出来,中间的数字代表两个属性之间的关系系数,最大值为1,代表完全正相关,关系系数越大代表相关性越大。从图中你能看出来“最大生命”“生命成长”和“初始生命”这三个属性的相关性大,我们只需要保留一个属性即可。同理我们也可以对其他相关性大的属性进行筛选,保留一个。你在代码中可以看到,我用features_remain数组保留了特征选择的属性,这样就将原本的20个属性降维到了13个属性。
关于数据规范化
我们能看到“最大攻速”这个属性值是百分数,不适合做矩阵运算,因此我们需要将百分数转化为小数。我们也看到“攻击范围”这个字段的取值为远程或者近战,也不适合矩阵运算,我们将取值做个映射,用1代表远程,0代表近战。然后采用Z-Score规范化,对特征矩阵进行规范化。
在聚类阶段
我们采用了GMM高斯混合模型,并将结果输出到CSV文件中。
这里我将输出的结果截取了一段(设置聚类个数为30):

第一列代表的是分组(簇),我们能看到张飞、程咬金分到了一组,牛魔、白起是一组,老夫子自己是一组,达摩、典韦是一组。聚类的特点是相同类别之间的属性值相近,不同类别的属性值差异大。因此如果你擅长用典韦这个英雄,不防试试达摩这个英雄。同样你也可以在张飞和程咬金中进行切换。这样就算你的英雄被别人选中了,你依然可以有备选的英雄可以使用。
总结
今天我带你一起做了EM聚类的实战,具体使用的是GMM高斯混合模型。从整个流程中可以看出,我们需要经过数据加载、数据探索、数据可视化、特征选择、GMM聚类和结果分析等环节。
聚类和分类不一样,聚类是无监督的学习方式,也就是我们没有实际的结果可以进行比对,所以聚类的结果评估不像分类准确率一样直观,那么有没有聚类结果的评估方式呢?这里我们可以采用Calinski-Harabaz指标,代码如下:
from sklearn.metrics import calinski_harabaz_score
print(calinski_harabaz_score(data, prediction))
指标分数越高,代表聚类效果越好,也就是相同类中的差异性小,不同类之间的差异性大。当然具体聚类的结果含义,我们需要人工来分析,也就是当这些数据被分成不同的类别之后,具体每个类表代表的含义。
另外聚类算法也可以作为其他数据挖掘算法的预处理阶段,这样我们就可以将数据进行降维了。

最后依然是两道思考题。针对王者荣耀的英雄数据集,我进行了特征选择,实际上王者荣耀的英雄数量并不多,我们可以省略特征选择这个阶段,你不妨用全部的特征值矩阵进行聚类训练,来看下聚类得到的结果。第二个问题是,依然用王者荣耀英雄数据集,在聚类个数为3以及聚类个数为30的情况下,请你使用GMM高斯混合模型对数据集进行聚类,并得出Calinski_Harabaz分数。
欢迎在评论区与我分享你的答案,也欢迎点击“请朋友读”,把这篇文章分享给你的朋友或者同事。
精选留言
2019-02-24 11:39:31
请问在数据规范化时,何时用Z-Score进行规范化,何时是Min-Max
2019-02-18 14:46:22
2019-03-20 11:31:34
2019-03-27 22:23:41
```
data[u'最大攻速'] = data[u'最大攻速'].apply(lambda x: float(x.strip('%'))/100)
data[u'攻击范围']=data[u'攻击范围'].map({'远程':1,'近战':0})
```
2019-03-10 17:39:05
2019-02-20 02:31:50
总样本过少,分成的类越多,每个类的所拥有的个体相对越少,类中个体差异变大,导致指标分数变低
为3个
[2 2 1 2 1 1 1 1 2 2 2 2 2 0 2 2 2 2 1 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 2 0 2 0 1 0 1 0 0 2 2 0 0 1 2 1 1 2 1 0 0 0 0]
34.74970397246901
为30
[ 1 20 5 13 26 15 14 5 8 20 16 20 13 0 22 16 19 22 26 10 6 4 10 4
4 4 10 12 3 27 0 27 29 3 27 3 3 24 27 18 29 3 3 27 3 18 20 27
20 3 21 11 2 23 23 1 28 11 25 26 28 2 17 1 9 11 11 7 12]
24.220124542171177
2019-02-19 13:03:03
2020-02-14 11:45:36
2019-02-18 11:28:18
2019-02-18 08:09:27
2019-05-14 22:29:16
2019-04-27 15:16:05
2.聚类个数为3的时候 Calinski_Harabaz 分数 大约是 22.9119297953 。聚类个数为30的时候 Calinski_Harabaz 分数 大约是 21.2142191471
2019-03-01 10:54:10
SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
data[u'最大攻速'] = data[u'最大攻速'].apply(lambda x: float(x.strip('%')) / 100)
E:\DevelopTool\Python\Python27\lib\site-packages\pandas\core\indexes\base.py:3259: UnicodeWarning: Unicode equal comparison failed to convert both arguments to Unicode - interpreting them as being unequal
indexer = self._engine.get_indexer(target._ndarray_values)
G:/Program/python/Geekbang/DataAnalysis/Part01/Lesson29/01_GMM.py:31: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
data[u'攻击范围'] = data[u'攻击范围'].map({'远程': 1, '近战': 0})
E:\DevelopTool\Python\Python27\lib\site-packages\sklearn\preprocessing\data.py:625: DataConversionWarning: Data with input dtype int64, float64 were all converted to float64 by StandardScaler.
return self.partial_fit(X, y)
E:\DevelopTool\Python\Python27\lib\site-packages\sklearn\utils\extmath.py:776: RuntimeWarning: invalid value encountered in true_divide
updated_mean = (last_sum + new_sum) / updated_sample_count
...
Traceback (most recent call last):
...
ValueError: Input contains NaN, infinity or a value too large for dtype('float64').
2019-02-18 08:12:26
2024-04-11 09:02:10
一、发生异常: ValueError could not convert string to float: '近战' File "D:\EM_data-master\here_em.py", line 21, in <module> corr = data[features].corr() ^^^^^^^^^^^^^^^^^^^^^ ValueError: could not convert string to float: '近战'
解决:在尝试计算数据帧(DataFrame)中特征之间的相关性时,使用了corr()方法。这个方法默认情况下只能在数值型数据上进行计算,无法处理字符串类型的数据。为了解决这个问题,需要确保所有参与相关性计算的特征都是数值型数据。为此需要在代码中 “ corr = data[features].corr() ” 前,增加两行实现的:
data[u'最大攻速'] = data[u'最大攻速'].apply(lambda x: float(x.strip('%'))/100)
data[u'攻击范围']=data[u'攻击范围'].map({'远程':1,'近战':0})
二、发生异常: ImportError cannot import name 'calinski_harabaz_score' from 'sklearn.metrics' (c:\Python311\Lib\site-packages\sklearn\metrics\__init__.py) File "D:\EM_data-master\here_em1.py", line 49, in <module> from sklearn.metrics import calinski_harabaz_score ImportError: cannot import name 'calinski_harabaz_score' from 'sklearn.metrics' (c:\Python311\Lib\site-packages\sklearn\metrics\__init__.py)
这个问题的原因是在较新版本的scikit-learn中,calinski_harabaz_score已经被重命名为calinski_harabasz_score。因此,正确的导入方式应该是从sklearn.metrics导入calinski_harabasz_score。为了解决这个问题,安装更新最新scikit-learn版本,
将代码:
from sklearn.metrics import calinski_harabaz_score
print(calinski_harabaz_score(data, prediction))
改为:
from sklearn.metrics import calinski_harabasz_score
print(calinski_harabasz_score(data, prediction))
2021-09-30 11:15:51
2021-01-13 15:09:48
1.使用所有特征数,聚类类别为30,得分为33.286020580818494
2.特征数降维处理后,聚类类别为30,得分为27.964658388803077
3.特征数降维处理后,聚类类别为3,得分为19.358008332914284
根据以上结果,可以总结出:当聚类类别数相同时,特征数越多,聚类效果越好;当进行特征数降维处理时,聚类类别数越多,聚类效果越好
2019-02-18 17:03:30
2020-11-24 19:05:12
[25 13 8 5 1 1 21 8 12 13 2 13 5 4 28 2 15 12 1 24 18 9 24 9
9 9 24 22 6 6 4 6 6 6 6 6 6 7 23 0 6 6 6 6 6 0 27 23
13 6 16 26 1 3 3 25 11 26 14 1 11 10 17 25 20 26 19 29 22]
23.507078366657264
2.全部特征 3个聚类
[2 2 1 2 1 1 1 1 2 2 2 2 2 0 2 2 2 2 1 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 2 0 2 0 1 0 1 0 0 2 2 0 0 1 2 1 1 2 1 0 0 0 0]
34.74970397246901
3. 12个特征,30个聚类
[ 9 19 5 12 3 3 23 29 12 1 7 19 12 6 20 7 28 12 3 2 17 2 2 2
2 2 2 0 21 26 6 21 4 21 26 21 21 10 14 11 4 21 21 4 21 11 19 14
19 21 27 13 8 16 16 9 25 19 24 3 25 8 15 9 18 13 13 22 0]
20.931148834796
4.12个特征,3个聚类
[0 0 1 1 1 1 2 1 1 0 1 0 1 0 1 1 0 1 1 2 2 2 2 2 2 2 2 2 2 2 0 2 2 2 2 2 2
2 0 2 2 2 2 2 2 2 0 0 0 2 0 0 0 0 0 0 0 0 2 1 0 0 0 0 0 0 0 0 2]
20.773369734506527
2020-04-16 16:22:55
谢谢!