我们在上一节中讲了数据采集,以及相关的工具使用,但做完数据采集就可以直接进行挖掘了吗?肯定不是的。
就拿做饭打个比方吧,对于很多人来说,热油下锅、掌勺翻炒一定是做饭中最过瘾的环节,但实际上炒菜这个过程只占做饭时间的20%,剩下80%的时间都是在做准备,比如买菜、择菜、洗菜等等。
在数据挖掘中,数据清洗就是这样的前期准备工作。对于数据科学家来说,我们会遇到各种各样的数据,在分析前,要投入大量的时间和精力把数据“整理裁剪”成自己想要或需要的样子。
为什么呢?因为我们采集到的数据往往有很多问题。
我们先看一个例子,假设老板给你以下的数据,让你做数据分析,你看到这个数据后有什么感觉呢?

你刚看到这些数据可能会比较懵,因为这些数据缺少标注。
我们在收集整理数据的时候,一定要对数据做标注,数据表头很重要。比如这份数据表,就缺少列名的标注,这样一来我们就不知道每列数据所代表的含义,无法从业务中理解这些数值的作用,以及这些数值是否正确。但在实际工作中,也可能像这个案例一样,数据是缺少标注的。
我简单解释下这些数据代表的含义。
这是一家服装店统计的会员数据。最上面的一行是列坐标,最左侧一列是行坐标。
列坐标中,第0列代表的是序号,第1列代表的会员的姓名,第2列代表年龄,第3列代表体重,第4~6列代表男性会员的三围尺寸,第7~9列代表女性会员的三围尺寸。
了解含义以后,我们再看下中间部分具体的数据,你可能会想,这些数据怎么这么“脏乱差”啊,有很多值是空的(NaN),还有空行的情况。
是的,这还仅仅是一家商店的部分会员数据,我们一眼看过去就能发现一些问题。日常工作中的数据业务会复杂很多,通常我们要统计更多的数据维度,比如100个指标,数据量通常都是超过TB、EB级别的,所以整个数据分析的处理难度是呈指数级增加的。这个时候,仅仅通过肉眼就很难找到问题所在了。
我举了这样一个简单的例子,带你理解在数据分析之前为什么要有数据清洗这个重要的准备工作。有经验的数据分析师都知道,好的数据分析师必定是一名数据清洗高手,要知道在整个数据分析过程中,不论是在时间还是功夫上,数据清洗大概都占到了80%。
数据质量的准则
在上面这个服装店会员数据的案例中,一看到这些数据,你肯定能发现几个问题。你是不是想知道,有没有一些准则来规范这些数据的质量呢?
准则肯定是有的。不过如果数据存在七八种甚至更多的问题,我们很难将这些规则都记住。有研究说一个人的短期记忆,最多可以记住7条内容或信息,超过7条就记不住了。而数据清洗要解决的问题,远不止7条,我们万一漏掉一项该怎么办呢?有没有一种方法,我们既可以很方便地记住,又能保证我们的数据得到很好的清洗,提升数据质量呢?
在这里,我将数据清洗规则总结为以下4个关键点,统一起来叫“完全合一”,下面我来解释下。
-
完整性:单条数据是否存在空值,统计的字段是否完善。
-
全面性:观察某一列的全部数值,比如在Excel表中,我们选中一列,可以看到该列的平均值、最大值、最小值。我们可以通过常识来判断该列是否有问题,比如:数据定义、单位标识、数值本身。
-
合法性:数据的类型、内容、大小的合法性。比如数据中存在非ASCII字符,性别存在了未知,年龄超过了150岁等。
-
唯一性:数据是否存在重复记录,因为数据通常来自不同渠道的汇总,重复的情况是常见的。行数据、列数据都需要是唯一的,比如一个人不能重复记录多次,且一个人的体重也不能在列指标中重复记录多次。
在很多数据挖掘的教学中,数据准则通常会列出来7~8项,在这里我们归类成了“完全合一”4项准则,按照以上的原则,我们能解决数据清理中遇到的大部分问题,使得数据标准、干净、连续,为后续数据统计、数据挖掘做好准备。如果想要进一步优化数据质量,还需要在实际案例中灵活使用。
清洗数据,一一击破
了解了数据质量准则之后,我们针对上面服装店会员数据案例中的问题进行一一击破。
这里你就需要Python的Pandas工具了。这个工具我们之前介绍过。它是基于NumPy的工具,专门为解决数据分析任务而创建。Pandas 纳入了大量库,我们可以利用这些库高效地进行数据清理工作。
这里我补充说明一下,如果你对Python还不是很熟悉,但是很想从事数据挖掘、数据分析相关的工作,那么花一些时间和精力来学习一下Python是很有必要的。Python拥有丰富的库,堪称数据挖掘利器。当然了,数据清洗的工具也还有很多,这里我们只是以Pandas为例,帮你应用数据清洗准则,带你更加直观地了解数据清洗到底是怎么回事儿。
下面,我们就依照“完全合一”的准则,使用Pandas来进行清洗。
1. 完整性
问题1:缺失值
在数据中有些年龄、体重数值是缺失的,这往往是因为数据量较大,在过程中,有些数值没有采集到。通常我们可以采用以下三种方法:
-
删除:删除数据缺失的记录;
-
均值:使用当前列的均值;
-
高频:使用当前列出现频率最高的数据。
比如我们想对df[‘Age’]中缺失的数值用平均年龄进行填充,可以这样写:
df['Age'].fillna(df['Age'].mean(), inplace=True)
如果我们用最高频的数据进行填充,可以先通过value_counts获取Age字段最高频次age_maxf,然后再对Age字段中缺失的数据用age_maxf进行填充:
age_maxf = train_features['Age'].value_counts().index[0]
train_features['Age'].fillna(age_maxf, inplace=True)
问题2:空行
我们发现数据中有一个空行,除了 index 之外,全部的值都是 NaN。Pandas 的 read_csv() 并没有可选参数来忽略空行,这样,我们就需要在数据被读入之后再使用 dropna() 进行处理,删除空行。
# 删除全空的行
df.dropna(how='all',inplace=True)
2. 全面性
问题:列数据的单位不统一
观察weight列的数值,我们能发现weight 列的单位不统一。有的单位是千克(kgs),有的单位是磅(lbs)。
这里我使用千克作为统一的度量单位,将磅(lbs)转化为千克(kgs):
# 获取 weight 数据列中单位为 lbs 的数据
rows_with_lbs = df['weight'].str.contains('lbs').fillna(False)
print df[rows_with_lbs]
# 将 lbs转换为 kgs, 2.2lbs=1kgs
for i,lbs_row in df[rows_with_lbs].iterrows():
# 截取从头开始到倒数第三个字符之前,即去掉lbs。
weight = int(float(lbs_row['weight'][:-3])/2.2)
df.at[i,'weight'] = '{}kgs'.format(weight)
3. 合理性
问题:非ASCII字符
我们可以看到在数据集中 Firstname 和 Lastname 有一些非 ASCII 的字符。我们可以采用删除或者替换的方式来解决非ASCII问题,这里我们使用删除方法:
# 删除非 ASCII 字符
df['first_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True)
df['last_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True)
4. 唯一性
问题1:一列有多个参数
在数据中不难发现,姓名列(Name)包含了两个参数 Firstname 和 Lastname。为了达到数据整洁目的,我们将 Name 列拆分成 Firstname 和 Lastname两个字段。我们使用Python的split方法,str.split(expand=True),将列表拆成新的列,再将原来的 Name 列删除。
# 切分名字,删除源数据列
df[['first_name','last_name']] = df['name'].str.split(expand=True)
df.drop('name', axis=1, inplace=True)
问题2:重复数据
我们校验一下数据中是否存在重复记录。如果存在重复记录,就使用 Pandas 提供的 drop_duplicates() 来删除重复数据。
# 删除重复数据行
df.drop_duplicates(['first_name','last_name'],inplace=True)
这样,我们就将上面案例中的会员数据进行了清理,来看看清理之后的数据结果。怎么样?是不是又干净又标准?
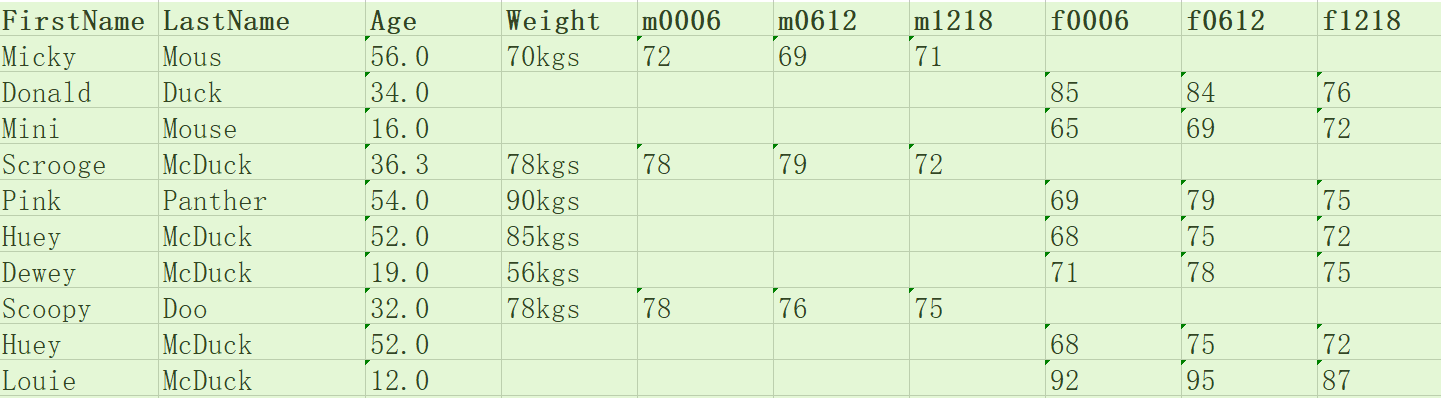
养成数据审核的习惯
现在,你是不是能感受到数据问题不是小事,上面这个简单的例子里都有6处错误。所以我们常说,现实世界的数据是“肮脏的”,需要清洗。
第三方的数据要清洗,自有产品的数据,也需要数据清洗。比如美团自身做数据挖掘的时候,也需要去除爬虫抓取,作弊数据等。可以说没有高质量的数据,就没有高质量的数据挖掘,而数据清洗是高质量数据的一道保障。
当你从事这方面工作的时候,你会发现养成数据审核的习惯非常重要。而且越是优秀的数据挖掘人员,越会有“数据审核”的“职业病”。这就好比编辑非常在意文章中的错别字、语法一样。
数据的规范性,就像是你的作品一样,通过清洗之后,会变得非常干净、标准。当然了,这也是一门需要不断修炼的功夫。终有一天,你会进入这样一种境界:看一眼数据,差不多7秒钟的时间,就能知道这个数据是否存在问题。为了这一眼的功力,我们要做很多练习。
刚开始接触数据科学工作的时候,一定会觉得数据挖掘是件很酷、很有价值的事。确实如此,不过今天我还要告诉你,再酷炫的事也离不开基础性的工作,就像我们今天讲的数据清洗工作。对于这些基础性的工作,我们需要耐下性子,一个坑一个坑地去解决。
好了,最后我们来总结下今天的内容,你都收获了什么?

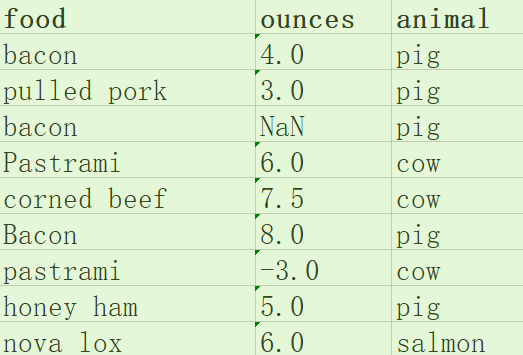
学习完今天的内容后,给你留个小作业吧。下面是一个美食数据,如果你拿到下面的数据,按照我们今天讲的准则,你能找到几点问题?如果你来清洗这些数据,你打算怎样清洗呢?
欢迎在留言区写下你的思考,如果你对今天“数据清洗”的内容还有疑问,也欢迎留言和我讨论。也欢迎点击“请朋友读”,把这篇文章分享给你的朋友或者同事。
精选留言
2019-02-05 18:07:51
数据.csv格式
链接:https://pan.baidu.com/s/1jNnUpntrlxFSubmna3HtXw
提取码:e9hc
2019-01-10 14:48:34
1."完整性"问题:数据有缺失,在ounces列的第三行存在缺失值
处理办法:可以用该列的平均值来填充此缺失值
2.“全面性”问题:food列的值大小写不统一
处理办法:统一改为小写
3.“合理性”问题:某一行的ounces值出现负值
处理办法:将该条数据记录删除
4.“唯一性”问题:food列大小写统一后会出现同名现象,
处理办法:需要将food列和animal列值均相同的数据记录进行合并到同一天记录中国
2019-04-11 20:38:01
课后练习原始数据: https://github.com/onlyAngelia/Read-Mark/blob/master/数据分析/geekTime/data/foodInformation.xlsx (点击View Raw下载)
2019-02-19 12:34:50
"""利用Pandas清洗美食数据"""
# 读取csv文件
df = pd.read_csv("c.csv")
df['food'] = df['food'].str.lower() # 统一为小写字母
df.dropna(inplace=True) # 删除数据缺失的记录
df['ounces'] = df['ounces'].apply(lambda a: abs(a)) # 负值不合法,取绝对值
# 查找food重复的记录,分组求其平均值
d_rows = df[df['food'].duplicated(keep=False)]
g_items = d_rows.groupby('food').mean()
g_items['food'] = g_items.index
print(g_items)
# 遍历将重复food的平均值赋值给df
for i, row in g_items.iterrows():
df.loc[df.food == row.food, 'ounces'] = row.ounces
df.drop_duplicates(inplace=True) # 删除重复记录
df.index = range(len(df)) # 重设索引值
print(df)
2019-01-07 08:11:55
2019-01-07 21:44:17
现在只是很少的几十条数据,等你真正去搞那些上亿的数据的时候,就知道核对数据是个多么复杂的事情了……
2019-01-29 13:01:46
2019-01-07 13:33:19
2019-04-11 11:52:30
2019-01-09 07:50:48
import pandas as pd
df = pd.read_csv("D://Data_for_sci/food.csv")
df.index
df
# Data cleaning for lowercase
df['food'] = df['food'].str.lower()
df
# Delet NaN
df = df.dropna()
df.index = range(len(df)) # reset index
df
# Get bacon's mean value and delet second one
df.loc[0,'ounces'] = df[df['food'].isin(['bacon'])].mean()['ounces']
df.drop(df.index[4],inplace=True)
df.index = range(len(df)) # reset index
df
#Get pastrami's mean value and delet second one
df.loc[2,'ounces'] = df[df['food'].isin(['pastrami'])].mean()['ounces']
df.drop(df.index[4],inplace=True)
df.index = range(len(df)) # reset index
df
2019-01-07 11:28:54
2019-01-19 22:25:12
感觉这个地方写复杂了,直接用正则表达式替换就行了
df['Weight'].replace('lbs$', 'kgs', regex=True, inplace=True)
2019-01-12 20:52:15
全面性:food列数据中存在大小写不一致问题
合法性:ounces列数据存在负值
唯一性:food列数据存在重复
# -*- coding: utf-8 -*
import pandas as pd
import numpy as np
from pandas import Series, DataFrame
df = pd.read_csv('./fooddata.csv')
# 把ounces 列中的NaN替换为平均值
df['ounces'].fillna(df['ounces'].mean(), inplace=True)
# 把food列中的大写字母全部转换为小写
df['food'] = df['food'].str.lower()
# 把ounces 列中的负数转化为正数
df['ounces']= df['ounces'].apply(lambda x: abs(x))
#删除food列中的重复值
df.drop_duplicates('food',inplace=True)
print (df)
2019-01-08 16:46:50
老师好,这行代码中[:-3]的作用是什么啊?
2019-02-12 22:31:10
1、重量【‘weight’】一列的数据,如何利用平均值进行填充,因为该列是字符类型,无法求平均。目前采用高频数据填充
2、Pink Panther用户的三围数据如何填充?,我想利用对应性别的平均值填充
3、案例中,后6列不显示‘NaN’,是因为填充列‘空格’吗?
_____________________
import pandas as pd
## 导入数据
df=pd.read_csv('第11节数据.csv')
## 重命名列名columns
df.rename(columns={'0':'Number','1':'Name','2':'Age','3':'Weight','4':'m0006','5':'m0612','6':'m1218'
,'7':'f0006','8':'f0612','9':'f1218'},inplace=True)
#2.全面性
#列数据统一单位
# 获取weight 数据列中单位为lbs的数据
rows_with_lbs=df['Weight'].str.contains('lbs').fillna(False)
print(df[rows_with_lbs])
# 将lbs转换为kgs,2.2lbs=1kgs
for i,lbs_row in df[rows_with_lbs].iterrows():
# 截取从头开始到倒数第三个字符之前,即去掉lbs
weight=int(float(lbs_row['Weight'][:-3])/2.2)
df.at[i,'Weight']='{}kgs'.format(weight)
#1.完整性
# 删除全空的行
df.dropna(how='all',inplace=True)
##缺失值补充方式一
## df[‘Age’] 中缺失的数值用平均年龄进行填充
#df['Age'].fillna(df['Age'].mean(),inplace=True)
## 缺失值补充方式二
## 使用Age一列高频数据进行填充
age_maxf=df['Age'].value_counts().index[0]
df['Age'].fillna(age_maxf,inplace=True)
## 使用Weight一列高频数据进行填充
weight_maxf=df['Weight'].value_counts().index[0]
df['Weight'].fillna(weight_maxf,inplace=True)
#4.唯一性
#Name拆分为firstname和lastname
#切分名字,删除源数据列
df[['first_name','last_name']]=df['Name'].str.split(expand=True)
df.drop('Name',axis=1,inplace=True)
# 移动first_name和last_name这俩列
first_name=df.pop('first_name')
df.insert(1,'first_name',first_name)
last_name=df.pop('last_name')
df.insert(2,'last_name',last_name)
#删除重复数据行
df.drop_duplicates(['first_name','last_name'],inplace=True)
#3.合理性
# 删除非ASCII字符
df['first_name'].replace({r'[^\x00-\x7F]+':''},regex=True,inplace=True)
df['last_name'].replace({r'[^\x00-\x7F]+':''},regex=True,inplace=True)
df
2019-01-11 16:27:00
# -*- coding:utf8 -*-
# __author__ = '北方姆Q'
# __datetime__ = 2019/1/11 15:53
import pandas as pd
# 导入
df = pd.read_csv("./s11.csv")
# 去除完全的空行
df.dropna(how='all', inplace=True)
# 食物名切分并去掉原本列
df[["first_name", "last_name"]] = df["food"].str.split(expand=True)
df.drop("food", axis=1, inplace=True)
# 名称首字母大写
df["first_name"] = df["first_name"].str.capitalize()
df["last_name"] = df["last_name"].str.capitalize()
# 以食物名为标准去重
df.drop_duplicates(["first_name", "last_name"], inplace=True)
print(df)
2019-11-08 03:34:00
import pandas as pd
# 读取数据
data_init = pd.read_csv("./11_clothingStoreMembers.csv")
# 清洗数据
# 删除 '\t' 列, 读取 csv 文件多了一列
data_init.drop(columns='\t', inplace=True)
# 重命名列名
data_init.rename(
columns={"0": "SEQ", "1": "NAME", "2": "AGE", "3": "WEIGHT", "4": "BUST_M", "5": "WAIST_M", "6": "HIP_M",
"7": "BUST_F", "8": "WAIST_F", "9": "HIP_F"}, inplace=True)
print(data_init)
# 1、完整性
# 删除空行
data_init.dropna(how='all', inplace=True)
# 4、唯一性
# 一列多个参数切分
data_init[["FIRST_NAME", "LAST_NAME"]] = data_init["NAME"].str.split(expand=True)
data_init.drop("NAME", axis=1, inplace=True)
# 删除重复数据
data_init.drop_duplicates(["FIRST_NAME", "LAST_NAME"], inplace=True)
# 2、全面性
# 列数据单位统一, 体重 WEIGHT 单位统一(lbs 英镑, kg 千克)
rows_with_lbs = data_init["WEIGHT"].str.contains("lbs").fillna(False)
print(rows_with_lbs)
# lbs 转为 kg
for i, lbs_row in data_init[rows_with_lbs].iterrows():
weight = int(float(lbs_row["WEIGHT"][:-3]) / 2.2)
data_init.at[i, "WEIGHT"] = "{}kgs".format(weight)
print(data_init)
# 3、合理性
# 非 ASCII 字符转换,这里删除处理
data_init["FIRST_NAME"].replace({r'[^\x00-\x7F]+': ''}, regex=True, inplace=True)
data_init["LAST_NAME"].replace({r'[^\x00-\x7F]+': ''}, regex=True, inplace=True)
# 1、完整性
# 补充缺失值-均值补充
data_init["AGE"].fillna(data_init["AGE"].mean(), inplace=True)
# 体重先去掉 kgs 的单位符号
data_init["WEIGHT"].replace('kgs$', '', regex=True, inplace=True) # 不带单位符号 kgs
data_init["WEIGHT"] = data_init["WEIGHT"].astype('float')
data_init["WEIGHT"].fillna(data_init["WEIGHT"].mean(), inplace=True)
data_init.replace('-', 0, regex=True, inplace=True) # 读取的 csv 数据多了'-'
data_init["WAIST_F"] = data_init["WAIST_F"].astype('float')
data_init["WAIST_F"].fillna(data_init["WAIST_F"].mean(), inplace=True)
# 用最高频的数据填充
age_max_freq = data_init["AGE"].value_counts().index[0]
print(age_max_freq)
data_init["AGE"].fillna(age_max_freq, inplace=True)
print(data_init)
2019-05-04 17:58:06
2019-01-17 19:33:01
def wash_data():
data = pd.read_excel("./data/data.xlsx")
data["food"] = data["food"].str.capitalize() # 首字母大写
data.fillna(0, inplace=True)
data.drop_duplicates("food", inplace=True) # 删除重复行
data.to_excel("./data/re_data.xlsx")
if __name__ == '__main__':
wash_data()
是不是清洗得太简单了。。。
2019-01-17 14:46:57
另外感觉这一讲有好多点都没讲深入呀 下面代码是对课程中的样例进行清洗 感觉只能做到几小点了. 特别是在填充nan值的时候 一开始想着遍历每一个nan值 然后再特判列的类型进行填充的. 但是发现三围那里有个大问题 按理说三围应该是int类型 但是因为有- 这个东西的存在 搞的三围是object类型 一开始赋值的时候报错提示需要str 后来想把列的类型转换成int也失败了 还有好多地方都卡着了...
import pandas as pd
import numpy as np
from pandas import Series, DataFrame
data = DataFrame(pd.read_excel('~/Desktop/data.xlsx'))
print(data)
# 更改列名
data.rename(columns={0:'序号',1:'姓名',2:'年龄',3:'体重',4:'男三围1',5:'男三围2',6:'男三围3',7:'女三围1',8:'女三围2',9:'女三围3'},inplace = True)
# 去掉重复行
data = data.drop_duplicates()
# 1.完整性
# 填充缺失值
col = data.columns.values.tolist()
row = data._stat_axis.values.tolist()
# 先把姓名的数据类型改成字符串
data['姓名'] = data['姓名'].astype('str')
# 1.1 先清除空行
data.dropna(how = 'all', inplace = True)
# 1.2 填充缺失值
age_maxf = data['年龄'].value_counts().index[0]
# 以年龄频率最大值来填充
data['年龄'].fillna(age_maxf, inplace=True)
# 2.全面性
# 把体重单位为lbs的转化为kgs 2.2lbs = 1kgs
# 把所有体重单位为lbs的记录存放在一起 (如果体重是nan则不要)
rows_with_lbs = data['体重'].str.contains('lbs').fillna(False)
for i,lbs_row in data[rows_with_lbs].iterrows():
weight = int(float(lbs_row['体重'][:-3]) / 2.2)
# 第一个参数是y坐标(竖) 第二个参数是x坐标(横)
data.at[i,'体重'] = '{}kgs'.format(weight)
print(data)
# 把清洗后的数据输出
data.to_excel('CleanData.xlsx')
# 会报错
# data.to_excel('~/Desktop/CleanData.xlsx')