你好,我是产品二姐。
今天我们帮助那些AI落地迷茫期的企业(老板)找到落地场景。我会聚焦于一家能源行业某细分赛道的企业,构建出一个《文本数据提取小助手》。
这个产品会带给你三个方向的启示。
-
场景扫描:如何在企业场景中,套用一个框架构建企业AI化全景图,合理挑选“小而美”场景切入。
-
场景聚焦:从“小而美”场景切入,构建出“产品小样”。这部分内容我们会利用提示词工程中的思维链和少量样本技巧,实现从海量文本中提取数据,构建出《能源行业数据提取》的产品小样。
-
场景深入:以“小样”入手,向客户直观展示AI的能力,然后把“小样”扩展、规模化,形成了一个完整的《文本数据提取小助手》产品。
在这三步之后,我们就成功地“从解决一个问题”升华为“解决一类问题”,实现从“场景”到“产品”的跃迁。其中前两部分会在这一节讲述,第三部分在下一节课讲述。
场景扫描:面对“迷茫”的客户如何做?
故事从我辞职创业的第9个月说起,那时我借助公众号、口碑的传播力量,吸引到一家能源领域某细分赛道的头部企业合作。CEO见到我们就噼里啪啦问了很多问题,比如:
- “二姐呀,感觉这个AI很厉害,可就是不知道我们能用在哪?”
- “对企业来说,我们的要求可是非常精确的,大模型的幻觉会是个问题吗?”
- “今年两会把人工智能提上日程,倒逼着我们找场景,但这些场景该怎么找呢?”
其实这种情况在技术变革初期很常见。因为社会每跨越一个时代,都要克服上一个时代的惯性,人们往往在这个时候有点不知所措。而在这样的时代,一名优秀的产品经理,就是要成为第一批主动抛弃惯性、拥抱变化的人。
带着这样的心态,我历经几个月的调研、探索和实践,到现在抽象出一份“原创”的企业AI场景框架。当大家迷茫的时候,可以把这个框架作为手册和你自己的具体场景比对:找到那些适合你们自己公司的场景。我用下面这张图来表示这个框架。
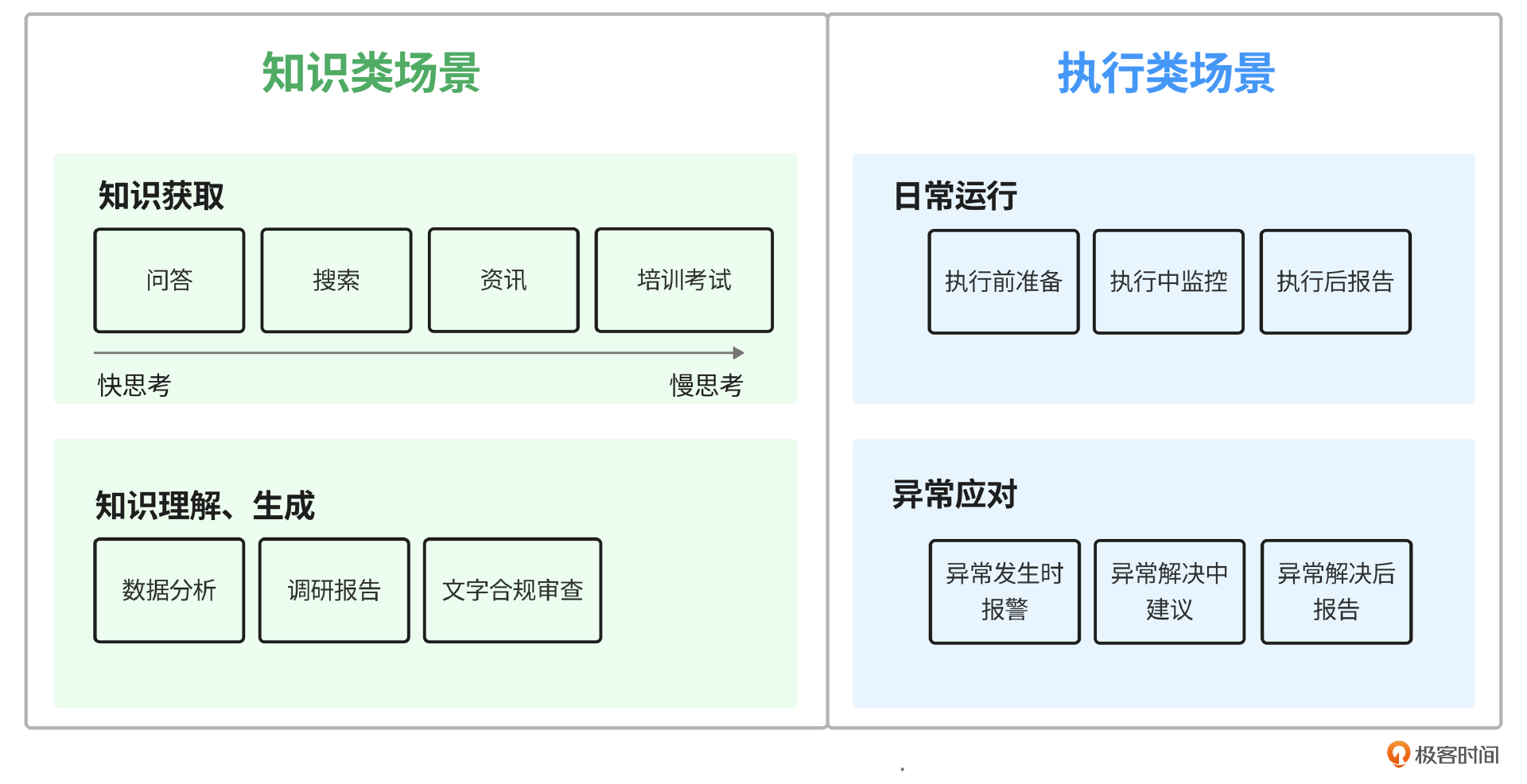
我把企业AI可落地场景分为知识类场景和执行类场景,它们分别用于提升企业大脑的“认知力”和企业机器的“执行力”。
知识类的场景按照认知的步骤依次是:知识获取 -> 知识理解 -> 知识生产。
-
知识获取包括:信息搜索、知识问答、资讯推送、培训考试。
-
知识理解主要指数据分析、调研等。
-
知识生产指的根据已知的搜索结果、调研、资讯,加上自己的习得、体会生产出新的知识。
以上三个环节构成了知识的闭环,它们都可以被AI不同程度地改进。我们拿知识生成中的调研报告举例。
在大语言模型来临之前,我们的调研报告需要通过阅读大量各类文献,再结合自身的理解和问题,人工生成。
在大语言模型出来之后,我们利用提示词工程和Agent技术就可以将文献和自身需求加上提示词,输入给大语言模型,模型可能在几分钟内就能生成一份调研报告。斯坦福大学就有一个叫Storm -风暴的项目,用户只需要输入一个简单的话题,就能生成一篇类似维基百科的长文[课后参考1]。这样的技术在企业中就可以有很多的应用,比如给某一个潜在客户生成一个长篇报告,帮助销售人员来拿下订单。
对于执行类场景,我将它划分为日常运行和异常应对两种场景,然后参考市场上众多Copilot的设计,把这两种场景的AI落地思路按照事前、事中、事后三个阶段给到用户建议。比如Github copilot官方给到的feature是:
-
Elevating developer workflows,即coding前评估开发者的工作流。
-
Get AI-based suggestions in real time,编码过程中给出实时建议。
-
Pull requests that tell a story,编码后生成提交代码的备注信息。
我再拿销售的日常运行来举例,一个企业的销售人员,核心是成交订单,但是作为企业组织中的一员,销售人员同时也要遵守公司的流程,将客户以及和客户沟通的过程记录在CRM里,走完一个完整的销售SOP(Standard operating procedure,即标准化流程)。这个SOP包括:
-
事前,第一次和客户沟通前要准备什么材料。
-
事中,客户沟通中什么样的问题该如何解答。
-
事后,客户沟通结束后该如何记录。
而这三者其实都可以由AI辅助来解决。类似这样的例子还有很多。当我利用这样的框架来一起梳理用户的场景时,看似毫无头绪的场景,就变得清晰起来。
最后,我按照这个框架又梳理出了适合这位能源领域细分赛道客户的细分场景,并为每个场景定义出了产品形态和需准备的数据支撑。
【注】所有数据均已脱敏、简要处理,且执行类场景因为保密原因只列出少量场景。
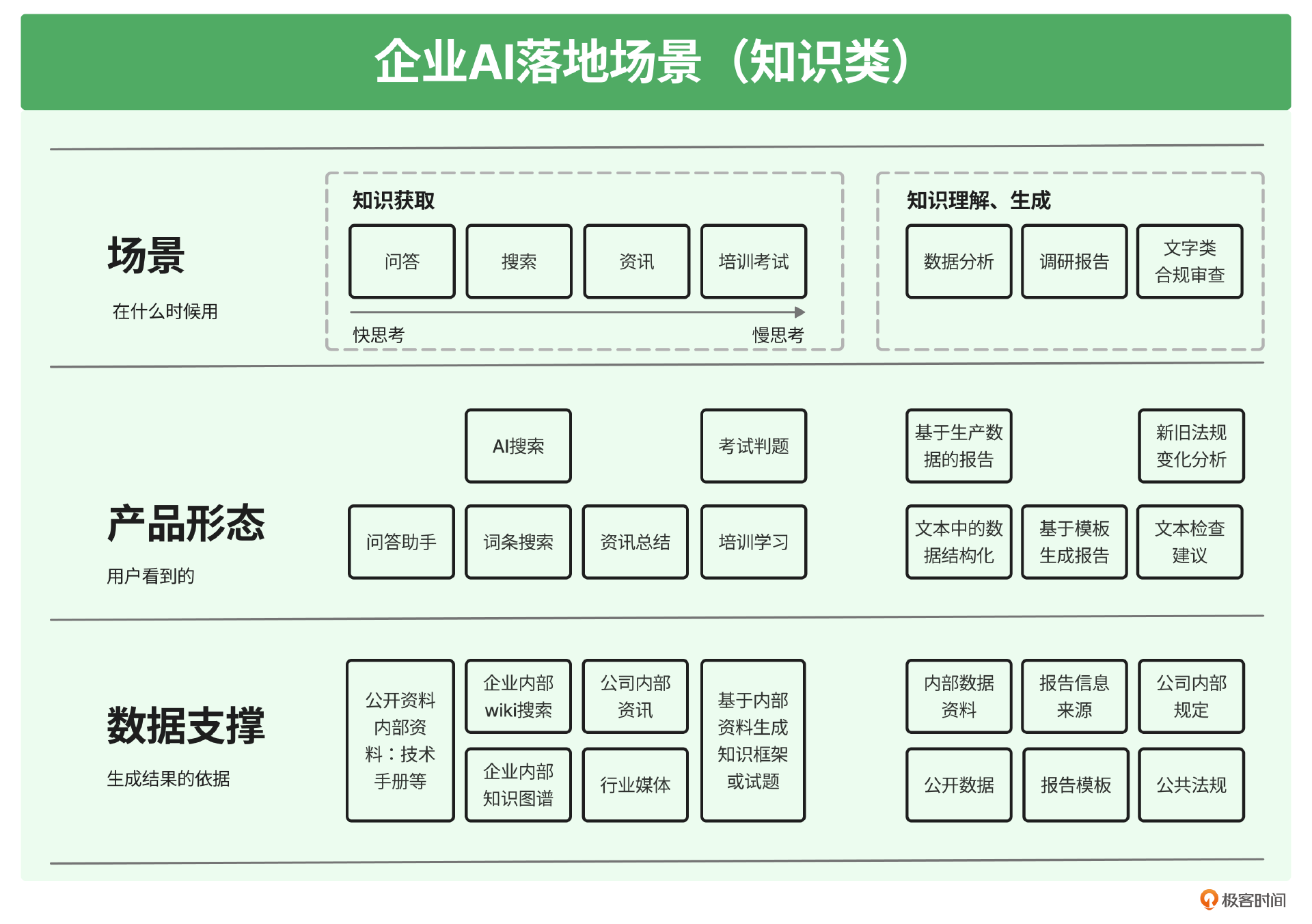
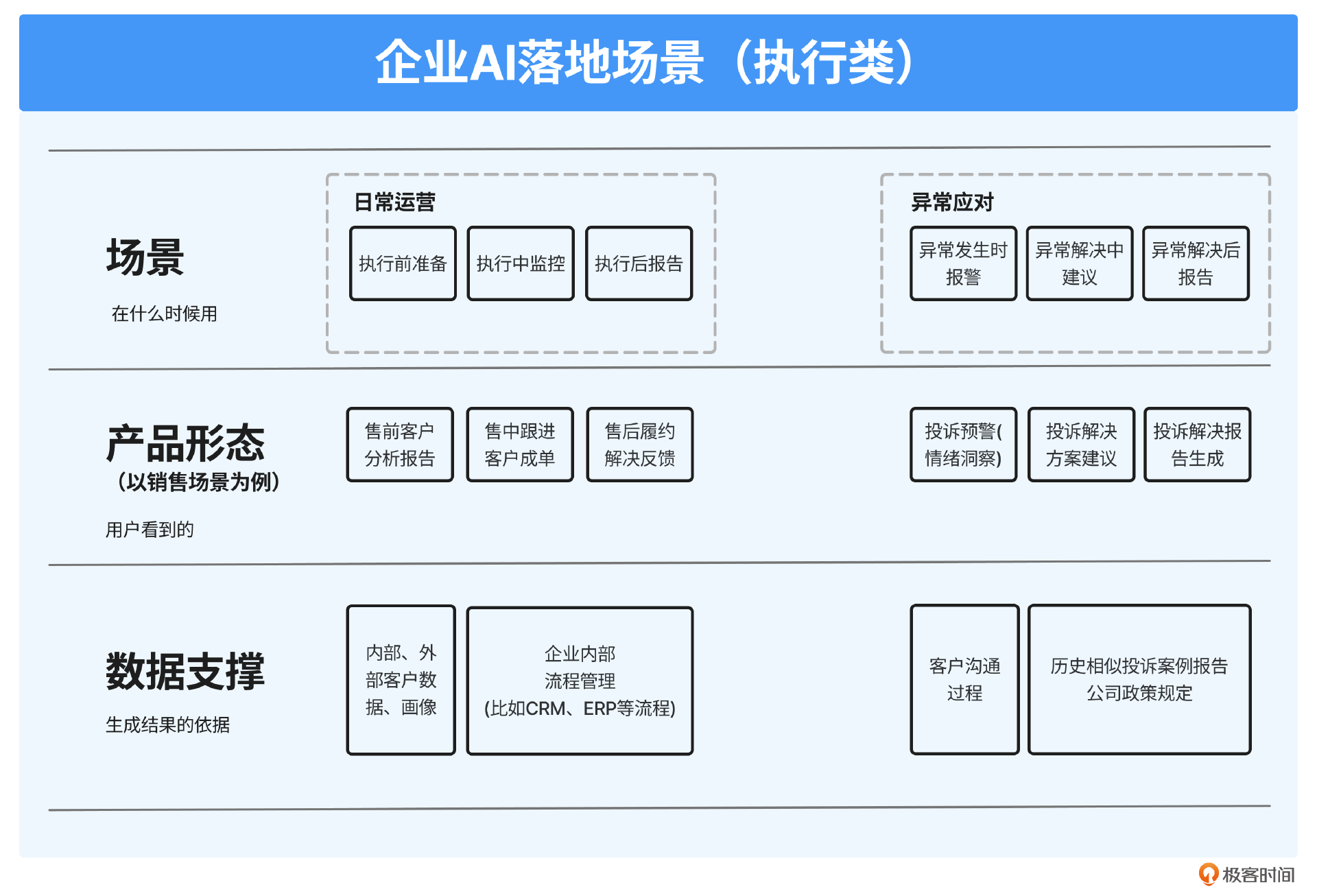
依照这样的框架,我们就完成了场景扫描。接下来,就可以将这些场景按照价值大小、难易程度来排序,从最有性价比的场景入手。对于这个客户,我们选择了调研报告生成这样一个场景。接下来和大家详细讲述这个过程。
场景聚焦:使用提示词工程构建出产品“小样”
当我们聚焦调研报告生成这样一个场景时,客户给了我们大量的报告信息来源和以往工作中人工生成的调研报告。大多数产品经理在这个时候,会以咨询者的身份给客户“如何进行AI改造”的建议,但其实此刻的你,更要“化身”为生产报告的人本身,这一点非常重要,因为只有这样,你才能做到两点。
-
不断拆解生成报告的过程,找到那个最小的、可被AI改造的任务构建“产品小样”,及时发给客户快速获得反馈。
-
对大语言模型生成的报告质量有辨别能力,从而更好地调整提示词。
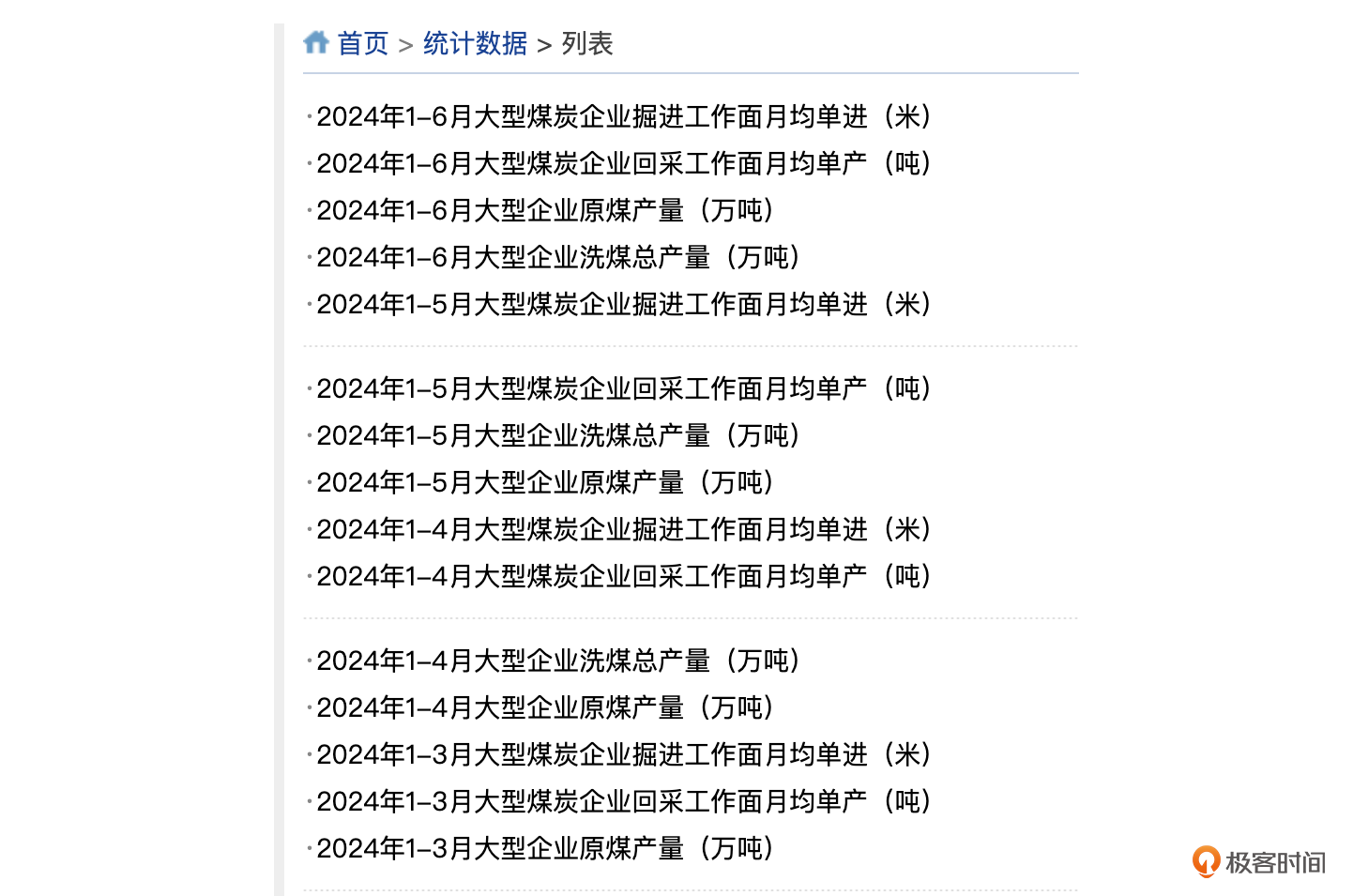
在“化身”为调研报告的专家深入这个场景后,我发现不少报告中会出现几个关键的煤炭行业指标,这些指标的来源是中国煤炭工业协会网站的统计数据板块(如下图),网站每月都会公布这些指数的值。
而在人工生成的报告中,专家会将这些数据收集起来,制作成表格,生成下面这样一张趋势图。
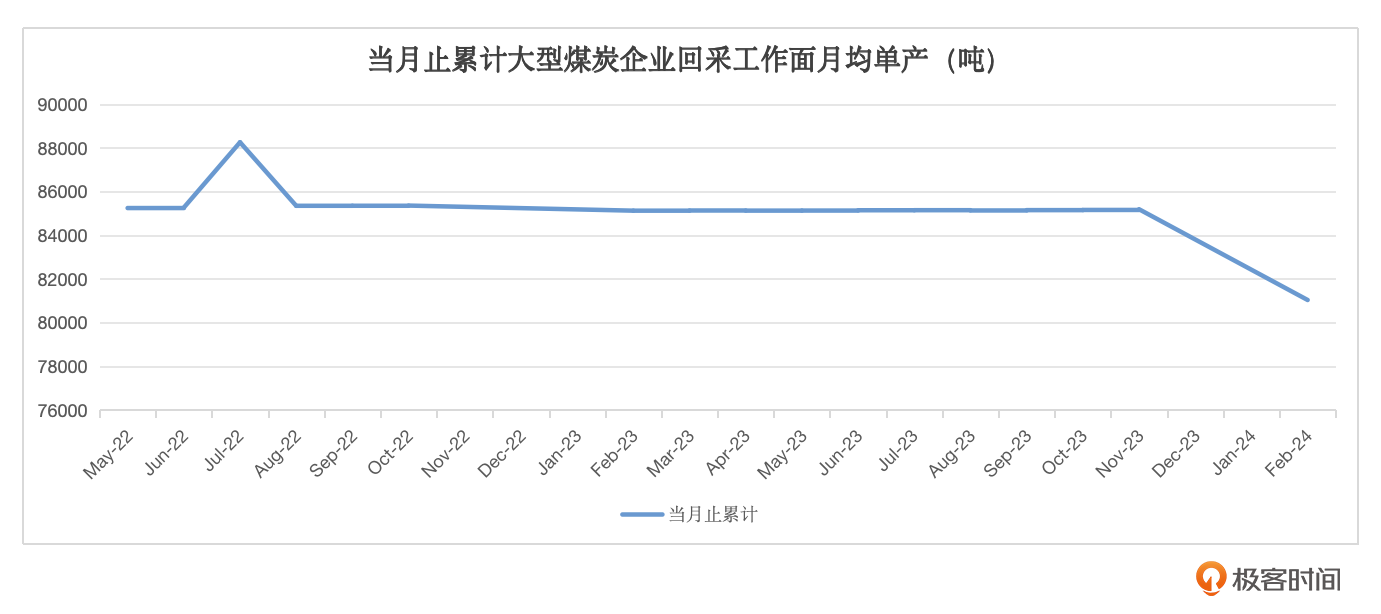
和客户沟通后,发现这些图中的数字都是一个个人工手“抠”出来的。他们也曾想过用爬虫、文本解析的方式解决,但由于这些数据本身是以新闻稿文字方式发布的,格式也会不一样(如下图),所以爬虫、解析也比较困难。而且这个数据从2012年起就开始公布,有十几年的数据了,一直没有人去梳理。
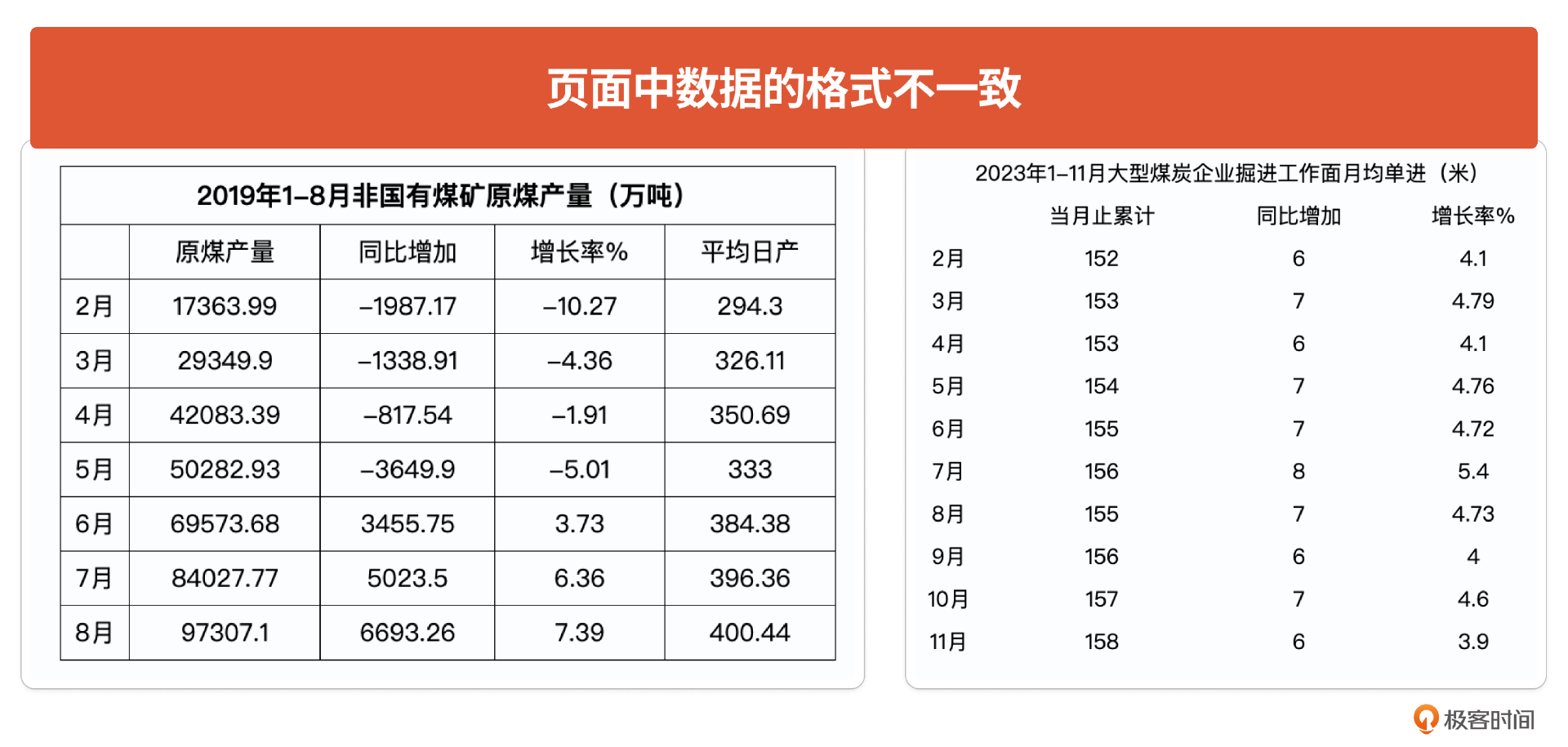
其实这个问题用产品思维抽象一下,就是将非结构化数据(新闻稿文字方式)中的关键信息抽取出来形成结构化数据。更重要的是,他们还有很多类似场景。我们可以看到:这个小样足够小,不会花很多精力,但同时又有潜力成长为一个细分赛道产品解决一大类问题。
这就是我们经常说的产品洞察力:对小问题足够敏感,同时又能看到更长远的发展空间。
于是我们就定义好这样一个“产品小样”作为目标:从中国煤炭工业协会网站的统计数据板块提取出近几年的关键行业指标。
这里我的讲述会很细,但并不难。确定目标以后,就可以开始构建思路。经过观察,我们发现这个统计数据板块的内容中有以下几个规律:
- 规律1:总共有4个行业指标,每个指标发布在不同的文稿里。

- 规律2:每个指标在同一个自然年中,最新公布的数据会包含本个自然年份所有的数据,因此数据会重合。比如2024年1月到6月数据会和2024年1月到5月的数据重合。

- 规律3:跨越自然年的数据是不会重合的,比如2024年的数据和2023年的数据不会出现在同一个新闻稿里。

根据以上三个规律,我们想象人工完成这件事的步骤。
-
爬取到页面中的标题,这一步采用爬虫即可完成。
-
将所选择的新闻稿按照行业指标分类。这一步中,也需要理解标题含义,我们借助大语言模型完成。
-
在标题中,针对某一个自然年选出覆盖时间范围最广的标题。比如《2024年1-4月……》和《2024年1-6月……》中,应该选择《2024年1-6月……》的这个新闻稿。这一步中,需要理解标题含义,因此要借助大语言模型来完成。
-
分指标去查看步骤3选出来网页。这一步实际上就是完成网页爬取,无需借助大语言模型。
-
从网页内容中“抠”出相应的数据(包括列名和数值)。这个抠的过程也需要理解语义后才能完成,也需要借助AI来完成。
-
最后将这些数据保存为csv文件,并转换成折线图展示。这一步是简单的数据保存和分析,采用传统方式即可解决。
我们将上述步骤整理为一个工作流。
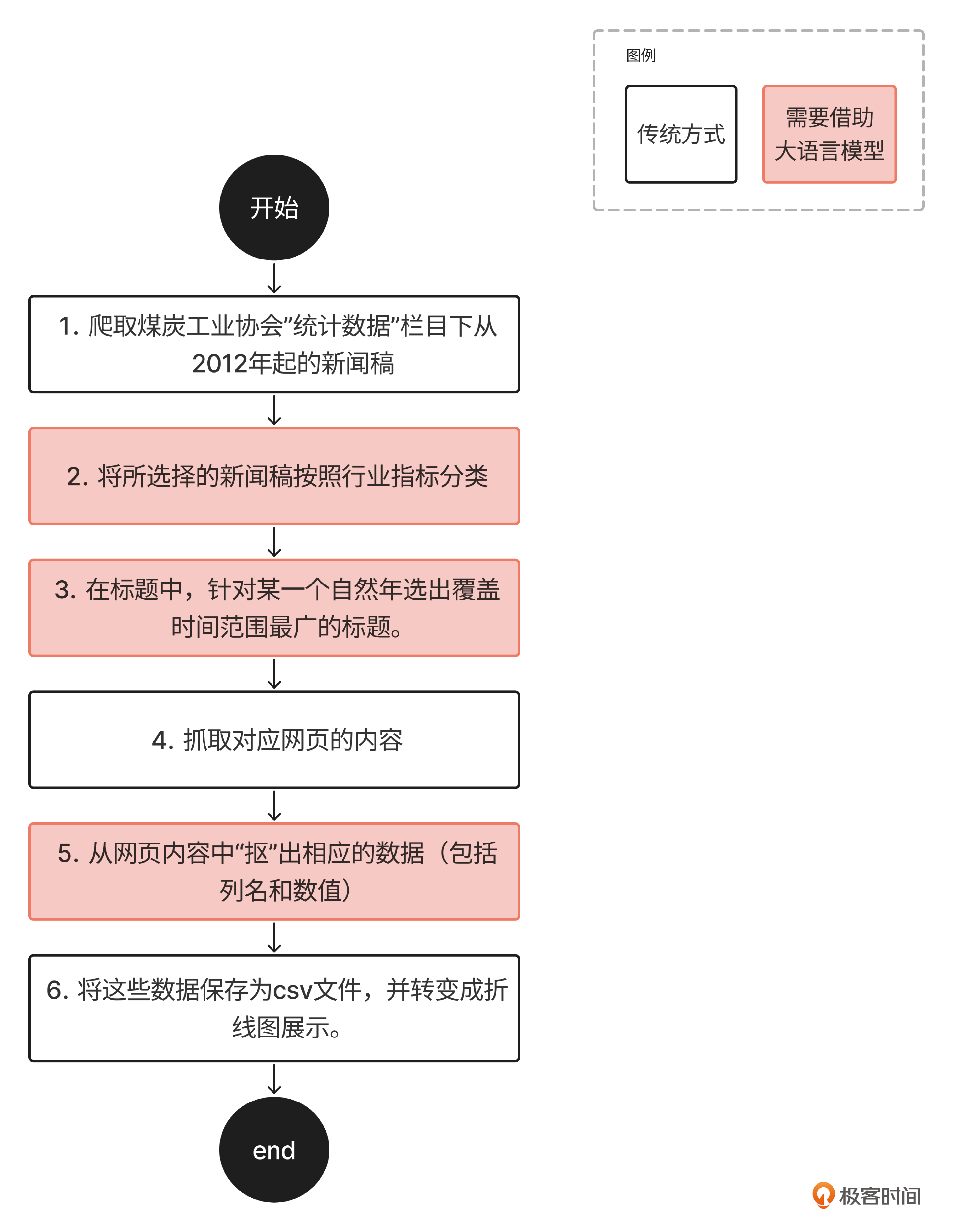
【注】类似的工作流图在AI产品的设计中很常见,这个案例中是一个单向、单分支的流程图,且是由产品经理人工设计的,可以说是最简单的工作流设计。在后面的案例中我们还会包含由Agent 自发执行的工作流。
接下来,对于需要借助大语言模型的第2、3、5步撰写提示词,我们会用到在03节提示词工程知识中的“一个框架和两个技巧”,即RTF框架(或者其他框架)、Few shots(少量样本)、COT(思维链)。
- 提示词设计示例1:将含有相似指标的标题分组输出(对应步骤2)。
在这组提示词中,我们首先按照RTF框架给出基本角色、任务、输出格式;其次在 “Attention” 中给出注意事项;然后给出在Few shots中给出两个例子;最后在 “Request” 部分给出用户提供的标题列表。大家需要注意:
- 输出格式部分,大家可以借助大语言模型给出输出格式建议。

- Fewshots部分,需要将各种情况分类,每种类别举一个例子说明,按照之前的论文建议,结合实际情况分类数量控制在2-10个其中必要的地方。在这一步提示词中的第二个例子就是给出了一个相对异常的情况,出现了一个调查制度而非统计指标相关的文稿,我们需要将这个标题噪音去掉,所以特别给出示例说明。
## Role:<!--这是注释,不必出现在提示词中:以上是RTF框架,实际中可以采用其他框架。-->
文章标题分组整理能手。
## Task:
给你一组文章标题列表,将含有以下指标的标题进行分组,并输出。
- 大型煤炭企业掘进工作面月均单进(米)
- 大型煤炭企业回采工作面月均单产(吨)
- 大型企业原煤产量(万吨)
- 大型企业洗煤总产量(万吨)
## Format:<!--这是注释,指定格式是为了提取出下一步所需输入:具备同一指标的标题-->
必须使用如下格式输出,不需要对结果进行解释,
[
{
"指标": "大型煤炭企业掘进工作面月均单进(米)",
"标题列表": [
"2020年1-10月大型煤炭企业掘进工作面月均单进(米)",
"2020年1-11月大型煤炭类企业掘进工作面月均单进(米)",
"2021年1-2月大型煤炭企业掘进工作面月均单进(米)"
]
},
{
"指标": "大型煤炭企业回采工作面月均单产(吨)",
"标题列表": [
"2020年1-3月大型煤炭企业回采工作面月均单产(吨)",
"2021年1-2月大型煤炭的企业回采工作面月均单产(吨)",
"2021年1-2月大型煤炭企业回采工作面月均单产(吨)"
]
}
]
## Attention
1. 在输出标题时候必须使用原有标题。<!--这是注释,必须使用原标题是为了在第四步中找到对应网页-->
2. 对于没有指定指标含义的标题,则不必输出。
## Few shots
<!--这是注释。Fewshots,将各种情况分类,每种类别举一个例子说明,按照之前的论文建议,结合实际情况分类数量控制在2-10个-->
**示例1:** <!--这是注释。这个例子给出仅有两个标题的情况-->
<<标题列表>>
"2020年1-3月大型煤炭企业掘进工作面月均单进(米)",
"2020年1-4月大型企业洗煤总产量(万吨)"
<<整理结果>>
[
{
"指标": "大型煤炭企业掘进工作面月均单进(米)",
"标题列表": [
"2020年1-3月大型煤炭企业掘进工作面月均单进(米)"
]
},
{
"指标": "大型企业洗煤总产量(万吨)",
"标题列表": [
"2020年1-4月大型企业洗煤总产量(万吨)"
]
}
]
**示例2**: <!--这是注释。这个例子给出一种相对异常的情况,出现了一个调查制度而非统计指标相关的文稿-->
<<标题列表>>
"2024年1-2月大型煤炭企业掘进工作面月均单进(米)",
"2024年1-2月大型企业洗煤总产量(万吨)",
"2023年1-11月大型煤炭企业掘进工作面月均单进(米)",
"2023年1-11月大型企业洗煤总产量(万吨)",
"煤炭工业统计调查制度(2022-2024)"
<<整理结果>>
[
{
"指标": "大型煤炭企业掘进工作面月均单进(米)",
"标题列表": [
"2024年1-2月大型煤炭企业掘进工作面月均单进(米)",
"2023年1-11月大型煤炭企业掘进工作面月均单进(米)"
]
},
{
"指标": "大型企业洗煤总产量(万吨)",
"标题列表": [
"2024年1-2月大型企业洗煤总产量(万吨)",
"2023年1-11月大型企业洗煤总产量(万吨)"
]
}
]
## Request
<<标题列表>>
{这里输入标题列表}
<<整理结果>>
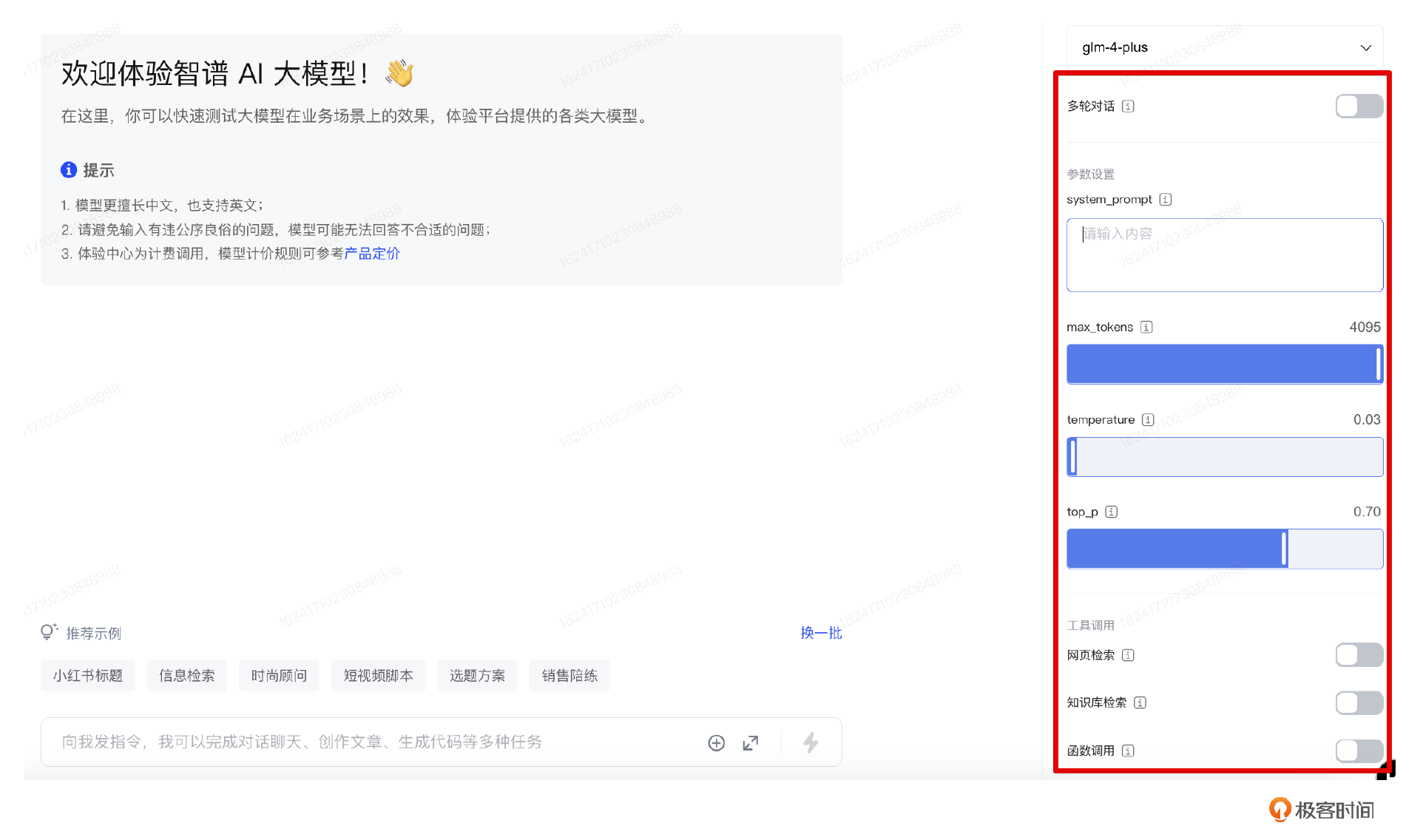
写好提示词后,就可以手动捏造标题列表,输入各大平台的API Playground中进行测试了。之前我们使用Open AI Playground的示例比较多,这次我们采用智谱的API Playground尝试。这里右侧API Playground的设置和默认值不一样,大家务必记得设置一下。
在这个例子中:
-
我们关闭了多轮对话,因为每次输出和上一次对话并无关系。多轮对话一般用于问答类产品与用户会有自然语言对话,或者某些Agent中需要结合短期记忆进行决策的情况。
-
System_prompt是指每次固定要输入的提示词,相当于一个全局变量,这里我们暂时不使用。
-
Max_tokens:这里标题列表可能会很长,因此设为最大值4096个token,每个模型支持的最长token数也不一样。
-
Temperature:这里我们不需要创造性,因此设为较低的0.01。
-
Top_p:我们采用默认值即可。
-
关闭网页检索、知识库检索、函数调用。
然后在左侧输入提示词,进行测试。在这个案例中,这个提示词能很好地满足需求。

- 提示词设计示例2:针对某一个自然年选出覆盖时间范围最广的标题(步骤3)。
这一步的提示词的输入项就是同一指标的一组标题,和上一步提示词不同的是,这一步需要做数学推理:判断1-11月的范围包含1-10月,所以需要引入COT(思维链)技巧。
## Role:
文章标题提取能手
## Task:
给你一组包含同一指标的文章标题列表,标题中含有日期范围,日期范围会有重合,请你提取出具有最大日期范围的标题。
## Format:
1.必须使用如下格式输出,不需要对结果进行解释
[
"标题1",
"标题2"
]
## COT:<!--这是注释。这就是COT过程-->
对于以下三个标题:
1. 2020年1-4月大型企业原煤产量(万吨)
2. 2020年1-10月大型企业原煤产量(万吨)
3. 2020年1-6月大型企业原煤产量(万吨)
4. 2021年1-3月大型企业原煤产量(万吨)
让我们一步步来,
1. 标题2中的2020年1-10月涵盖了标题1中的日期范围2020年1-4月,因此保留标题2"2020年1-10月大型企业原煤产量(万吨)"。
2. 标题3中的2020年1-6月,已经在标题2中的范围"2020年1-10月",因此保留标题2"2020年1-10月大型企业原煤产量(万吨)"
3. 标题4中的2021年1-3月和标题2中的范围"2020年1-10月"相比,二者互不包含,因此保留这两个标题。
4. 因此标题4"2021年1-3月大型企业原煤产量(万吨)"和标题2"2020年1-10月大型企业原煤产量(万吨)"保留
## Few shots
**示例1**
<<标题列表>>
[
"2020年1-4月全国大型企业原煤产量(万吨)",
"2020年1-4月大型企业原煤产量(万吨)",
"2020年1-3月大型企业原煤生产量(万吨)",
"2020年1-2月大型企业全国原煤产量(万吨)",
"2019年1-11月大型企业原煤产量(万吨)"
]
<<提取结果>>
[
"2020年1-4月全国大型企业原煤产量(万吨)",
"2019年1-11月大型企业原煤产量(万吨)"
]
**示例2**
<<标题列表>>
[
"2024年1-3月大型煤炭企业掘进工作面月均单进(米)",
"2024年1-2月大型煤炭企业掘进工作面月均单进(米)",
"2023年1-11月大型煤炭企业的掘进工作面月均单进(米)",
"2023年1-10月大型煤炭企业掘进工作面 月均单进(米)",
"2022年1-11月大型煤炭企业的掘进工作面月均单进(米)"
]
<<提取结果>>
[
"2024年1-3月大型煤炭企业掘进工作面月均单进(米)",
"2023年1-11月大型煤炭企业掘进工作面月均单进(米)",
"2022年1-11月大型煤炭企业掘进工作面月均单进(米)"
]
## initialize
<<标题列表>>
{input}
<<提取结果>>
- 提示词设计示例3:将不同新闻稿中的同一指标数据汇总
这一部分的提示词输入项是同一指标的几篇文章内容原文,输出是一段csv格式的文本。和前两个示例相比,没有新的技巧,就当作你的课后作业来完成吧。
通过这么三组提示词,加上传统的网页内容抓取,我们就完成了一个文本数据提取的“产品小样”。这个小样的输入项是中国煤炭工业协会官网统计数据板块的网址,输出就是煤炭行业近几年四大指标的数据变化趋势。
我们仅仅花了1天的时间把这个“小样”完成,并展示给了客户。当他们看到这样的结果时,终于揭开了AI在他们心中的神秘面纱,“哦~原来AI不止是能问答,还能当做工具。”这个“小样”激发了更多的文本数据提取诉求,而解决方法也变得更加复杂,也是我们下一节课的内容。
阶段复盘
在企业类场景中,AI落地一直有两大难题,一是场景难找,二是AI的天生幻觉难以构建起高可靠性的企业级应用。
针对找场景的问题,我在这节课给你提供了一个参考方法,即先构建一个全景图,不断拆解场景后深入一个细分领域。我们只需要记住一个企业场景框架,一个“化身”用户的方法,结合提示词工程中的“一个框架,两个技巧”,就能找到适合切入的小微落地场景,以此为起点逐步开启企业级AI应用的进化过程。
而第二个问题,AI模型幻觉从原理上来说是很难避免的。但别忘了,AI应用不等于AI模型,而是以AI模型为内核,以各种工程手段为外围设备的严密组合,通过这些外围就可以提高AI应用的可靠性。其中有一个外围手段就是在合适的时机插入人机交互,这也是AI产品设计中的重要方法,我们在下节课一起学习。
课后题
观察中国煤炭行业协会官网的统计数据,利用提示词工程中的少量样本和COT技巧,撰写这个案例中的第三个提示词:将不同新闻稿中的同一指标数据汇总,并在智谱AI的开放平台进行测试。
提示:这个题目里输入项是几个网页的内容,输出项是一段csv格式的文字。比如将2024年1-6月和2023年1-11月的大型煤炭企业掘进工作面月均单进(米)两篇网页中的数据输出为一个csv格式的文字。
参考
参考1:斯坦福大学的storm项目
精选留言
2024-10-10 14:01:50
2024-10-05 21:48:45
2025-01-20 16:48:43
##Task:给你一个网页内容,将网页中关键数据提取出来,并用CSV格式输出。
##Format:必须使用以下格式输出,不需要对结果进行解释,不能输出网页中没有的内容。
[ 当月止累计 同比增加 增长率%
2月 145 -7 -4.6
3月 147 -6 -4.2]
##Few shots
**示例1:**
<<网页内容>>
"2024年1-9月大型煤炭企业掘进工作面月均单进(米)
字号:[ 大 中 小 ] 发布时间:2024-11-26 16:46:43 来源:中国煤炭工业协会 发布人:郭勇
2024年1-9月大型煤炭企业掘进工作面月均单进(米)
当月止累计 同比增加 增长率%
2月 145 -7 -4.6
3月 147 -6 -4.2
4月 146 -5 -3.55
5月 145 -5 -3.57
6月 146 -5 -3.54
7月 149 -5 -3.49
8月 150 -4 -2.73
9月 152 -3 -2.01"
<<关键数据提取结果>>
[当月止累计 同比增加 增长率%
2月 145 -7 -4.6
3月 147 -6 -4.2
4月 146 -5 -3.55
5月 145 -5 -3.57
6月 146 -5 -3.54
7月 149 -5 -3.49
8月 150 -4 -2.73
9月 152 -3 -2.01
]
##Request
<<网页内容>>
2024年1-10月大型煤炭企业掘进工作面月均单进(米)
字号:[ 大 中 小 ] 发布时间:2024-12-23 14:23:34 来源:中国煤炭工业协会 发布人:郭勇
2024年1-10月大型煤炭企业掘进工作面月均单进(米)
当月止累计 同比增加 增长率%
2月 145 -7 -4.6
3月 147 -6 -4.2
4月 146 -5 -3.55
5月 145 -5 -3.57
6月 146 -5 -3.54
7月 149 -5 -3.49
8月 150 -4 -2.73
9月 152 -3 -2.01
10月 155 3 1.97
<<关键数据提取结果>>
[当月止累计 同比增加 增长率%
2月 145 -7 -4.6
3月 147 -6 -4.2
4月 146 -5 -3.55
5月 145 -5 -3.57
6月 146 -5 -3.54
7月 149 -5 -3.49
8月 150 -4 -2.73
9月 152 -3 -2.01
10月 155 3 1.97
]
2025-01-17 17:12:16
网页文字内容提取助手
## Task:
我会给你一组网页内容为同一指标的不同时间的数据对比,含有月份信息,多项分类,请你提取出每一项内容,并且以CSV的格式输出。
## Format:
1.必须使用如下格式输出,不需要对结果进行解释
[2月 145 -7 -4.6%,
3月 147 -6 -4.2%]
## COT:<!--这是注释。这就是COT过程-->
这是文章内容:
字号:[ 大 中 小 ] 发布时间:2024-12-23 14:23:34 来源:中国煤炭工业协会 发布人:郭勇
2024年1-10月大型煤炭企业掘进工作面月均单进(米)
当月止累计 同比增加 增长率%
2月 145 -7 -4.6
3月 147 -6 -4.2
4月 146 -5 -3.55
5月 145 -5 -3.57
6月 146 -5 -3.54
7月 149 -5 -3.49
8月 150 -4 -2.73
9月 152 -3 -2.01
10月 155 3 1.97
让我们一步步来,
1. 先找到月份信息,把每月的信息进行提取
2. 再一行一行读取,提取出每一个月中的数据值。
## Few shots
**示例1**
<<文章内容>>
[字号:[ 大 中 小 ] 发布时间:2024-12-23 14:23:34 来源:中国煤炭工业协会 发布人:郭勇
2024年1-10月大型煤炭企业掘进工作面月均单进(米)
当月止累计 同比增加 增长率%
2月 145 -7 -4.6
3月 147 -6 -4.2
4月 146 -5 -3.55
5月 145 -5 -3.57
6月 146 -5 -3.54
7月 149 -5 -3.49
8月 150 -4 -2.73
9月 152 -3 -2.01
10月 155 3 1.97
]
<<提取结果>>
[2月 145 -7 -4.6
3月 147 -6 -4.2
4月 146 -5 -3.55
5月 145 -5 -3.57
6月 146 -5 -3.54
7月 149 -5 -3.49
8月 150 -4 -2.73
9月 152 -3 -2.01
10月 155 3 1.97]
**示例2**
<<文章内容>>
[字号:[ 大 中 小 ] 发布时间:2024-10-21 14:54:55 来源:中国煤炭工业协会 发布人:郭勇
2024年1-8月大型煤炭企业掘进工作面月均单进(米)
当月止累计 同比增加 增长率%
2月 145 -7 -4.6
3月 147 -6 -4.2
4月 146 -5 -3.55
5月 145 -5 -3.57
6月 146 -5 -3.54
7月 149 -5 -3.49
8月 150 -4 -2.73
]
<<提取结果>>
[
2月 145 -7 -4.6
3月 147 -6 -4.2
4月 146 -5 -3.55
5月 145 -5 -3.57
6月 146 -5 -3.54
7月 149 -5 -3.49
8月 150 -4 -2.73
]
## initialize
<<文章内容>>
{2024年1-5月大型煤炭企业回采工作面月均单产(吨)
当月止累计 同比增加 增长率%
2月 81032 -3892 -4.58
3月 81048 -3526 -4.54
4月 81072 -3529 -4.55
5月 81065 -3485 -4.12
}
<<提取结果>>
[
2月 81032 -3892 -4.58
3月 81048 -3526 -4.54
4月 81072 -3529 -4.55
5月 81065 -3485 -4.12
]
2025-01-16 17:27:02
{
"指标": "大型煤炭企业掘进工作面月均单进(米)",
"标题列表": [
"2024年1-10月大型煤炭企业掘进工作面月均单进(米)",
"2024年1-9月大型煤炭企业掘进工作面月均单进(米)",
.... 省略
"2019年1-2月大型煤炭企业掘进工作面月均单进(米)",
"2018年1-11月大型煤炭企业掘进工作面月均单进(米)",
"2018年1-10月大型煤炭企业掘进工作面月均单进(米)",
"2017年1-4月大型煤炭企业掘进工作面月均单进(米)",
"2017年1-3月大型煤炭企业掘进工作面月均单进(米)",
"2017年1-2月大型煤炭企业掘进工作面月均单进(米)",
"2016年1-11月大型企业原煤产量(万吨)",
"2016年1-10月大型企业原煤产量(万吨)",
"2016年1-9月大型企业原煤产量(万吨)",
"2016年1-7月大型企业原煤产量(万吨)",
...省略
"2012年1-10月大型企业原煤产量(万吨)",
"2012年1-7月大型企业原煤产量(万吨)",
"2012年1-7月大型企业洗精煤产量(万吨)",
"2012年1-6月大型企业洗精煤产量(万吨)",
"2012年1-6月大型企业原煤产量(万吨)",
"2012年1-5月大型企业洗精煤产量",
"2012年1-5月大型企业原煤产量"
]
},
{
"指标": "大型煤炭企业回采工作面月均单产(吨)",
"标题列表": [
"2024年1-10月大型煤炭企业回采工作面月均单产(吨)",
"2024年1-9月大型煤炭企业回采工作面月均单产(吨)",
"2024年1-8月大型煤炭企业回采工作面月均单产(吨)",
....省略
"2019年1-4月大型煤炭企业回采工作面月均单产(吨)",
"2019年1-3月大型煤炭企业回采工作面月均单产(吨)
模型只输出到2019年的
2024-11-01 10:16:14
## Task:给你一组包含同一指标数据的新闻稿,文稿内容中含有相同的数据指标,请你提取出相同的数据指标并按CSV格式输出 。
## 示例:
1.必须使用如下格式输出,不需要对结果进行解释
时间,原钢产量,同比增加,增长率
2月,48051.7,-2382.1,-4.7
3月,4224.2,-3395.8, -4.4
<<内容列表>>
2024年1-8月大型企业原煤产量(万吨)
字号:[ 大 中 小 ] 发布时间:2024-10-21 14:54:26 来源:中国煤炭工业协会 发布人:郭勇
2024年1-8月大型企业原煤产量(万吨)
原煤产量 同比增加 增长率%
2月 48051.7 -2382.1 -4.7
3月 74224.2 -3395.8 -4.4
4月 99581.8 -3526.4 -3.4
5月 125314.1 -3854.9 -3
6月 152583.8 -3350.2 -2.2
7月 180813.4 -1009.9 -0.6
8月 208913.4 1844 0.9
2024-10-09 18:31:44
我发现这个网站最新的数据出现了一个新的问题:标题命名错误。最新的4条文章的标题是如下
2024年1-7月大型煤炭企业掘进工作面月均单进(米)
2024年1-7月大型煤炭企业回采工作面月均单产(吨)
2024年1-7月大型企业洗煤总产量(万吨)
2024年1-7月大型企业洗煤总产量(万吨)
其中第三条的标题错误,应该是2024年1-7月大型企业原煤产量(万吨)。这样爬虫下来的标题列表的数据就有问题了。
请问老师这种case也可以通过大模型的提示词工程来“修复”列表的数据吗?
2024-10-04 09:37:25
## Role:文章标题提取能手
## Task:给你一组包含同一指标数据的新闻稿,文稿内容中含有相同的数据指标,请你提取出相同的数据指标并将他们汇总
## Format:1.必须使用如下格式输出,不需要对结果进行解释
name,age,gender
Tom,25,Male
Jerry,23,Female
<<内容列表>> "然而,河北的一些煤炭企业由于受到深部开采地质条件复杂的影响,尽管在技术装备上也有一定投入,但月均单进相对较低,约为80米,主要面临着高地应力、瓦斯治理等难题", "陕西的一些大型煤炭企业在开采神府 - 东胜煤田等优质煤田时,凭借良好的地质条件和积极引进先进的智能化掘进技术,月均单进取得了较好的成绩,平均达到了150米以上", "新疆地区的部分煤炭企业虽然资源潜力巨大,但由于地理偏远,交通不便,设备运输和技术人才引入存在一定困难,月均单进目前处于60米左右的水平",
<<整理结果>>
河北的煤炭企业,陕西的煤炭企业,新疆的煤炭企业
80,150,60
2025-04-12 16:34:10
2025-04-07 14:43:03
2025-03-12 16:17:55
指标数据汇总能手
## Task:
给你一组包含全部指标数据的标题根据标题将同一指标数据汇总。
## Format:
1.必须使用如下格式输出,不需要对结果进行解释
[
"2024,大型煤炭企业回采工作月均单产",
"2023,大型煤炭企业回采工作月均单产"
]
## COT:<!--这是注释。这就是COT过程-->
对于以下个标题:
1.2024年1-11月大型煤炭企业回采工作面月均单产(吨)
2.2024年1-11月大型煤炭企业掘进工作面月均单进(米)
3.2024年1-11月大型企业洗煤总产量(万吨)
4.2024年1-11月大型企业原煤产量(万吨)
5.2024年1-10月大型煤炭企业掘进工作面月均单进(米)
6.2024年1-10月大型煤炭企业回采工作面月均单产(吨)
7.2024年1-10月大型企业原煤产量(万吨)
8.2024年1-10月大型企业洗煤总产量(万吨)
9.2023年1-9月大型煤炭企业掘进工作面月均单进(米)
10.2023年1-9月大型企业原煤产量(万吨)
让我们一步步来,
1.标题1和标题6都是24年的大型煤炭企业回采工作面月均单产(吨)指标,所以将这两个输出汇总为"2024,大型煤炭企业回采工作月均单产“
2.标题2和标题5都是24年的大型煤炭企业掘进工作面月均单进(米),所以将这两个输出汇总为"2024,大型煤炭企业掘进工作面月均单进(米)“
3.标题3和标题8都是24年的大型企业洗煤总产量(万吨),所以将这两个输出汇总为"2024,大型企业原煤产量(万吨)“
3. 因此标题输出的全部汇总为"2024,大型煤炭企业回采工作月均单产“"2024,大型煤炭企业掘进工作面月均单进(米)“"2024,大型企业原煤产量(万吨)“2024,大型企业洗煤总产量(万吨)”"2023,大型煤炭企业掘进工作面月均单进(米)“"2023,大型企业原煤产量(万吨)“
## Few shots
**示例1**
<<标题列表>>
[
“2024年1-9月大型煤炭企业回采工作面月均单产(吨)”
“2024年1-9月大型企业洗煤总产量(万吨)”
“2024年1-8月大型煤炭企业回采工作面月均单产(吨)”
“2024年1-8月大型煤炭企业掘进工作面月均单进(米)”
“2024年1-8月大型企业原煤产量(万吨)”
“2024年1-8月大型企业洗煤总产量(万吨)”
“2024年1-7月大型煤炭企业回采工作面月均单产(吨)”
]
<<提取结果>>
[
"2024,大型煤炭企业回采工作面月均单产(吨)",
"2024,大型企业洗煤总产量(万吨)"
"2024,大型煤炭企业掘进工作面月均单进(米)"
]
## initialize
<<标题列表>>
{input}
<<提取结果>>
2025-03-06 13:17:25
2025-02-23 15:35:42
2025-01-29 14:39:04
|
## Role文本中数字信息提取助手
## Task
1. 分析整篇文本数据,提取数字信息
2. 结合上下文,理解并归纳出该数字信息所代表的真实含义
3. 按照给定格式,输出数字及其真实含义
## Format
[
"数字1代表的真实含义":数字1
"数字2代表的真实含义":数字2
"数字3代表的真实含义":数字3]
## One shot
<<文本数据>>
2025年1月20日,DeepSeek正式发布了其最新的人工智能模型DeepSeek-R1,并同步开源模型权重。这一模型在后训练阶段大规模使用了强化学习技术,仅用少量标注数据就大幅提升了模型推理能力。DeepSeek-R1在多项基准测试中表现出色,例如在AIME 2024数学测试中得分高达79.8%,超越了OpenAI的同类产品。
<<数字输出>>
["DeepSeek-R1正式发布的时间":2025年1月20日"DeepSeek-R1在AIME 2024数学测试中得分":79.8%]
## Request
<<文本数据>>DeepSeek-V3:开源模型新突破,全球排名登顶2025年1月29日,DeepSeek团队宣布其最新版本的人工智能模型 DeepSeek-V3 在全球开源模型排行榜中跃居第一。这一成就标志着 DeepSeek 在人工智能领域的技术实力得到了国际认可。DeepSeek-V3 在多项关键性能指标上表现出色。例如,在自然语言处理任务中,其准确率达到了 92.5%,比上一代模型提升了 10%。此外,DeepSeek-V3 在推理速度上也取得了显著进步,单次推理时间缩短至 0.02秒,比行业平均水平快了 50%。DeepSeek 团队表示,V3 版本的模型采用了最新的多模态技术,能够同时处理文本、图像和语音数据。这一技术突破使得 DeepSeek-V3 在复杂场景下的应用更加广泛,例如在智能客服、自动驾驶和医疗影像分析等领域。此外,DeepSeek 还宣布将 V3 版本的模型开源,供全球开发者免费使用。这一举措预计将加速人工智能技术在全球范围内的普及和应用。开源后,DeepSeek-V3 的代码在 GitHub 上获得了超过 10万次 的下载量,显示出开发者社区对其的高度关注。DeepSeek 的首席技术官李明表示:“DeepSeek-V3 的成功不仅是技术上的突破,更是我们团队长期努力的结果。我们希望通过开源这一模型,推动全球人工智能技术的发展,让更多企业和开发者受益。”
<<数字输出>>
实际输出
2025-01-17 16:07:52
2024-11-27 16:16:51
"指标": "大型企业原煤产量(万吨)",
"标题列表": [
"2024年1-9月大型企业原煤产量(万吨)",
"2024年1-8月大型企业原煤产量(万吨)",
"2024年1-6月大型企业原煤产量(万吨)",
"2024年1-5月大型企业原煤产量(万吨)",
"2024年1-4月大型企业原煤产量(万吨)"
]
},
{
"指标": "大型企业洗煤总产量(万吨)",
"标题列表": [
"2024年1-9月大型企业洗煤总产量(万吨)",
"2024年1-8月大型企业洗煤总产量(万吨)",
"2024年1-7月大型企业洗煤总产量(万吨)",
"2024年1-7月大型企业洗煤总产量(万吨)",
"2024年1-6月大型企业洗煤总产量(万吨)",
"2024年1-5月大型企业洗煤总产量(万吨)",
"2024年1-4月大型企业洗煤总产量(万吨)"
]
}
2024-11-19 21:04:10
内容提取小能手
##Task
从网页内容中提取信息
##fomart
使用如下格式整理列表,无需对结果进行解释
时间,当月累计,同比增加
2月,81032,-2892
##attention
- 与格式中列项无关的部分不用显示
##one-shot
<<网页内容>>
2024年1-8月大型煤炭企业回采工作面月均单产(吨)
字号:[ 大 中 小 ] 发布时间:2024-10-21 14:57:04 来源:中国煤炭工业协会 发布人:郭勇
2024年1-8月大型煤炭企业回采工作面月均单产(吨)
当月止累计 同比增加 增长率%
2月 81032 -3892 -4.58
3月 81048 -3526 -4.54
<<提取内容>>
时间,当月累计,同比增加
2月,81032,-3892
3月,81048,-3526
##input
<<网页内容>>
2024年1-7月大型煤炭企业回采工作面月均单产(吨)
字号:[ 大 中 小 ] 发布时间:2024-09-24 10:45:27 来源:中国煤炭工业协会 发布人:郭勇
2024年1-7月大型煤炭企业回采工作面月均单产(吨)
当月止累计 同比增加 增长率%
2月 81032 -3892 -4.58
3月 81048 -3526 -4.54
4月 81072 -3529 -4.55
5月 81065 -3485 -4.12
6月 81029 -3025 -3.87
7月 81057 -2965 -3.79
<<提取内容>>
时间,当月累计,同比增加
2月,81032,-3892
3月,81048,-3526
4月,81072,-3529
5月,81065,-3485
6月,81029,-3025
7月,81057,-2965
2024-10-01 20:56:01