你好,我是程远。
在上一讲里,我们学习了Linux capabilities的概念,也知道了对于非privileged的容器,容器中root用户的capabilities是有限制的,因此容器中的root用户无法像宿主机上的root用户一样,拿到完全掌控系统的特权。
那么是不是让非privileged的容器以root用户来运行程序,这样就能保证安全了呢?这一讲,我们就来聊一聊容器中的root用户与安全相关的问题。
问题再现
说到容器中的用户(user),你可能会想到,在Linux Namespace中有一项隔离技术,也就是User Namespace。
不过在容器云平台Kubernetes上目前还不支持User Namespace,所以我们先来看看在没有User Namespace的情况下,容器中用root用户运行,会发生什么情况。
首先,我们可以用下面的命令启动一个容器,在这里,我们把宿主机上/etc目录以volume的形式挂载到了容器中的/mnt目录下面。
# docker run -d --name root_example -v /etc:/mnt centos sleep 3600
然后,我们可以看一下容器中的进程"sleep 3600",它在容器中和宿主机上的用户都是root,也就是说,容器中用户的uid/gid和宿主机上的完全一样。
# docker exec -it root_example bash -c "ps -ef | grep sleep"
root 1 0 0 01:14 ? 00:00:00 /usr/bin/coreutils --coreutils-prog-shebang=sleep /usr/bin/sleep 3600
# ps -ef | grep sleep
root 5473 5443 0 18:14 ? 00:00:00 /usr/bin/coreutils --coreutils-prog-shebang=sleep /usr/bin/sleep 3600
虽然容器里root用户的capabilities被限制了一些,但是在容器中,对于被挂载上来的/etc目录下的文件,比如说shadow文件,以这个root用户的权限还是可以做修改的。
# docker exec -it root_example bash
[root@9c7b76232c19 /]# ls /mnt/shadow -l
---------- 1 root root 586 Nov 26 13:47 /mnt/shadow
[root@9c7b76232c19 /]# echo "hello" >> /mnt/shadow
接着我们看看后面这段命令输出,可以确认在宿主机上文件被修改了。
# tail -n 3 /etc/shadow
grafana:!!:18437::::::
tcpdump:!!:18592::::::
hello
这个例子说明容器中的root用户也有权限修改宿主机上的关键文件。
当然在云平台上,比如说在Kubernetes里,我们是可以限制容器去挂载宿主机的目录的。
不过,由于容器和宿主机是共享Linux内核的,一旦软件有漏洞,那么容器中以root用户运行的进程就有机会去修改宿主机上的文件了。比如2019年发现的一个RunC的漏洞 CVE-2019-5736, 这导致容器中root用户有机会修改宿主机上的RunC程序,并且容器中的root用户还会得到宿主机上的运行权限。
问题分析
对于前面的问题,接下来我们就来讨论一下解决办法,在讨论问题的过程中,也会涉及一些新的概念,主要有三个。
方法一:Run as non-root user(给容器指定一个普通用户)
我们如果不想让容器以root用户运行,最直接的办法就是给容器指定一个普通用户uid。这个方法很简单,比如可以在docker启动容器的时候加上"-u"参数,在参数中指定uid/gid。
具体的操作代码如下:
# docker run -ti --name root_example -u 6667:6667 -v /etc:/mnt centos bash
bash-4.4$ id
uid=6667 gid=6667 groups=6667
bash-4.4$ ps -ef
UID PID PPID C STIME TTY TIME CMD
6667 1 0 1 01:27 pts/0 00:00:00 bash
6667 8 1 0 01:27 pts/0 00:00:00 ps -ef
还有另外一个办法,就是我们在创建容器镜像的时候,用Dockerfile为容器镜像里建立一个用户。
为了方便你理解,我还是举例说明。就像下面例子中的nonroot,它是一个用户名,我们用USER关键字来指定这个nonroot用户,这样操作以后,容器里缺省的进程都会以这个用户启动。
这样在运行Docker命令的时候就不用加"-u"参数来指定用户了。
# cat Dockerfile
FROM centos
RUN adduser -u 6667 nonroot
USER nonroot
# docker build -t registry/nonroot:v1 .
…
# docker run -d --name root_example -v /etc:/mnt registry/nonroot:v1 sleep 3600
050809a716ab0a9481a6dfe711b332f74800eff5fea8b4c483fa370b62b4b9b3
# docker exec -it root_example bash
[nonroot@050809a716ab /]$ id
uid=6667(nonroot) gid=6667(nonroot) groups=6667(nonroot)
[nonroot@050809a716ab /]$ ps -ef
UID PID PPID C STIME TTY TIME CMD
nonroot 1 0 0 01:43 ? 00:00:00 /usr/bin/coreutils --coreutils-prog-shebang=sleep /usr/bin/sleep 3600
好,在容器中使用普通用户运行之后,我们再看看,现在能否修改被挂载上来的/etc目录下的文件? 显然,现在不可以修改了。
[nonroot@050809a716ab /]$ echo "hello" >> /mnt/shadow
bash: /mnt/shadow: Permission denied
那么是不是只要给容器中指定了一个普通用户,这个问题就圆满解决了呢?其实在云平台上,这么做还是会带来别的问题,我们一起来看看。
由于用户uid是整个节点中共享的,那么在容器中定义的uid,也就是宿主机上的uid,这样就很容易引起uid的冲突。
比如说,多个客户在建立自己的容器镜像的时候都选择了同一个uid 6667。那么当多个客户的容器在同一个节点上运行的时候,其实就都使用了宿主机上uid 6667。
我们都知道,在一台Linux系统上,每个用户下的资源是有限制的,比如打开文件数目(open files)、最大进程数目(max user processes)等等。一旦有很多个容器共享一个uid,这些容器就很可能很快消耗掉这个uid下的资源,这样很容易导致这些容器都不能再正常工作。
要解决这个问题,必须要有一个云平台级别的uid管理和分配,但选择这个方法也要付出代价。因为这样做是可以解决问题,但是用户在定义自己容器中的uid的时候,他们就需要有额外的操作,而且平台也需要新开发对uid平台级别的管理模块,完成这些事情需要的工作量也不少。
方法二:User Namespace(用户隔离技术的支持)
那么在没有使用User Namespace的情况,对于容器平台上的用户管理还是存在问题。你可能会想到,我们是不是应该去尝试一下User Namespace?
好的,我们就一起来看看使用User Namespace对解决用户管理问题有没有帮助。首先,我们简单了解一下User Namespace的概念。
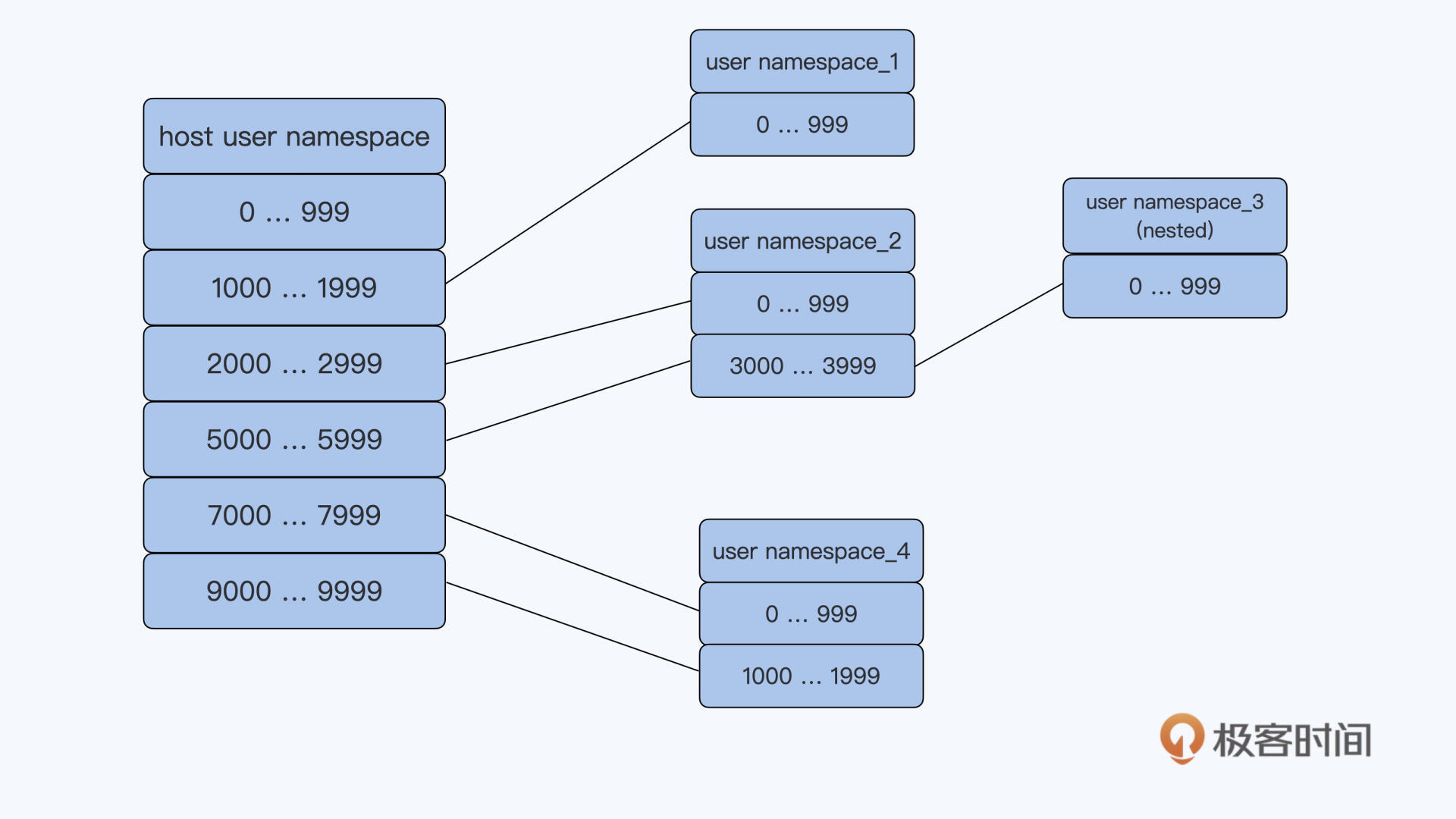
User Namespace隔离了一台Linux节点上的User ID(uid)和Group ID(gid),它给Namespace中的uid/gid的值与宿主机上的uid/gid值建立了一个映射关系。经过User Namespace的隔离,我们在Namespace中看到的进程的uid/gid,就和宿主机Namespace中看到的uid和gid不一样了。
你可以看下面的这张示意图,应该就能很快知道User Namespace大概是什么意思了。比如namespace_1里的uid值是0到999,但其实它在宿主机上对应的uid值是1000到1999。
还有一点你要注意的是,User Namespace是可以嵌套的,比如下面图里的namespace_2里可以再建立一个namespace_3,这个嵌套的特性是其他Namespace没有的。
我们可以启动一个带User Namespace的容器来感受一下。这次启动容器,我们用一下podman这个工具,而不是Docker。
跟Docker相比,podman不再有守护进程dockerd,而是直接通过fork/execve的方式来启动一个新的容器。这种方式启动容器更加简单,也更容易维护。
Podman的命令参数兼容了绝大部分的docker命令行参数,用过Docker的同学也很容易上手podman。你感兴趣的话,可以跟着这个手册在你自己的Linux系统上装一下podman。
那接下来,我们就用下面的命令来启动一个容器:
# podman run -ti -v /etc:/mnt --uidmap 0:2000:1000 centos bash
我们可以看到,其他参数和前面的Docker命令是一样的。
这里我们在命令里增加一个参数,"--uidmap 0:2000:1000",这个是标准的User Namespace中uid的映射格式:"ns_uid:host_uid:amount"。
那这个例子里的"0:2000:1000"是什么意思呢?我给你解释一下。
第一个0是指在新的Namespace里uid从0开始,中间的那个2000指的是Host Namespace里被映射的uid从2000开始,最后一个1000是指总共需要连续映射1000个uid。
所以,我们可以得出,这个容器里的uid 0是被映射到宿主机上的uid 2000的。这一点我们可以验证一下。
首先,我们先在容器中以用户uid 0运行一下 sleep 这个命令:
# id
uid=0(root) gid=0(root) groups=0(root)
# sleep 3600
然后就是第二步,到宿主机上查看一下这个进程的uid。这里我们可以看到,进程uid的确是2000了。
# ps -ef |grep sleep
2000 27021 26957 0 01:32 pts/0 00:00:00 /usr/bin/coreutils --coreutils-prog-shebang=sleep /usr/bin/sleep 3600
第三步,我们可以再回到容器中,仍然以容器中的root对被挂载上来的/etc目录下的文件做操作,这时可以看到操作是不被允许的。
# echo "hello" >> /mnt/shadow
bash: /mnt/shadow: Permission denied
# id
uid=0(root) gid=0(root) groups=0(root)
好了,通过这些操作以及和前面User Namespace的概念的解释,我们可以总结出容器使用User Namespace有两个好处。
第一,它把容器中root用户(uid 0)映射成宿主机上的普通用户。
作为容器中的root,它还是可以有一些Linux capabilities,那么在容器中还是可以执行一些特权的操作。而在宿主机上uid是普通用户,那么即使这个用户逃逸出容器Namespace,它的执行权限还是有限的。
第二,对于用户在容器中自己定义普通用户uid的情况,我们只要为每个容器在节点上分配一个uid范围,就不会出现在宿主机上uid冲突的问题了。
因为在这个时候,我们只要在节点上分配容器的uid范围就可以了,所以从实现上说,相比在整个平台层面给容器分配uid,使用User Namespace这个办法要方便得多。
这里我额外补充一下,前面我们说了Kubernetes目前还不支持User Namespace,如果你想了解相关工作的进展,可以看一下社区的这个PR。
方法三:rootless container(以非root用户启动和管理容器)
前面我们已经讨论了,在容器中以非root用户运行进程可以降低容器的安全风险。除了在容器中使用非root用户,社区还有一个rootless container的概念。
这里rootless container中的"rootless"不仅仅指容器中以非root用户来运行进程,还指以非root用户来创建容器,管理容器。也就是说,启动容器的时候,Docker或者podman是以非root用户来执行的。
这样一来,就能进一步提升容器中的安全性,我们不用再担心因为containerd或者RunC里的代码漏洞,导致容器获得宿主机上的权限。
我们可以参考redhat blog里的这篇文档, 在宿主机上用redhat这个用户通过podman来启动一个容器。在这个容器中也使用了User Namespace,并且把容器中的uid 0映射为宿主机上的redhat用户了。
$ id
uid=1001(redhat) gid=1001(redhat) groups=1001(redhat)
$ podman run -it ubi7/ubi bash ### 在宿主机上以redhat用户启动容器
[root@206f6d5cb033 /]# id ### 容器中的用户是root
uid=0(root) gid=0(root) groups=0(root)
[root@206f6d5cb033 /]# sleep 3600 ### 在容器中启动一个sleep 进程
# ps -ef |grep sleep ###在宿主机上查看容器sleep进程对应的用户
redhat 29433 29410 0 05:14 pts/0 00:00:00 sleep 3600
目前Docker和podman都支持了rootless container,Kubernetes对rootless container支持的工作也在进行中。
重点小结
我们今天讨论的内容是root用户与容器安全的问题。
尽管容器中root用户的Linux capabilities已经减少了很多,但是在没有User Namespace的情况下,容器中root用户和宿主机上的root用户的uid是完全相同的,一旦有软件的漏洞,容器中的root用户就可以操控整个宿主机。
为了减少安全风险,业界都是建议在容器中以非root用户来运行进程。不过在没有User Namespace的情况下,在容器中使用非root用户,对于容器云平台来说,对uid的管理会比较麻烦。
所以,我们还是要分析一下User Namespace,它带来的好处有两个。一个是把容器中root用户(uid 0)映射成宿主机上的普通用户,另外一个好处是在云平台里对于容器uid的分配要容易些。
除了在容器中以非root用户来运行进程外,Docker和podman都支持了rootless container,也就是说它们都可以以非root用户来启动和管理容器,这样就进一步降低了容器的安全风险。
思考题
我在这一讲里提到了rootless container,不过对于rootless container的支持,还存在着不少的难点,比如容器网络的配置、Cgroup的配置,你可以去查阅一些资料,看看podman是怎么解决这些问题的。
欢迎你在留言区提出你的思考和疑问。如果这一讲对你有帮助,也欢迎转发给你的同事、朋友,一起交流学习。
精选留言
2020-12-31 09:08:39
这样做,就需要有个k8s的 initContainer 容器先以root用户权限去修改存储目录的权限. 否则后面服务的1001号用户可能就没有权限去写文件了.
------------------
最近遇到一个问题,想咨询一下老师:
你们有使用过 容器资源可视化隔离方案(lxcfs) 么, 有没有什么坑?
通俗点就是:让容器中的free, top等命令看到容器的数据,而不是物理机的数据。
------------------
我遇到的问题是在容器内执行类似`go build/test`命令时,默认是根据当前CPU核数来调整构建的并发数.
这就导致了实际只给容器分配了1个核,但是它以为自己有16个核.
然后就开16个link进程,互相之间除了有竞争,导致CPU上下文切换频繁,更要命的是把磁盘IO给弄满了.影响了整台宿主机的性能.
(由于项目比较大,需要构建的文件比较多,所以很容器就让宿主机的IO达到了云服务器SSD磁盘的限制 160MB/s)
我知道在我这个场景下,可以通过指定构建命令`-p`来控制构建的并发数.
(https://golang.org/cmd/go/#hdr-Compile_packages_and_dependencies)
实际也这么尝试过,效果也不错.
但问题是,我的项目会很多,每个人构建命令的写法都完全不一样,如果每个地方都去指定参数,就会比较繁琐,且容易遗漏.
------------------
后来,我看到一篇文章: 容器资源可视化隔离的实现方法
(https://mp.weixin.qq.com/s/SCxD4OiDYsmoIyN5XMk4YA)
之前也在其他专栏中看老师提到过 lxcfs.
我在想,老师在迁移上k8s的过程中,肯定也遇到过类似的问题,不知道老师是如何解决的呢?
2022-11-15 09:53:43
2021-01-09 21:56:01
在宿主机上:
以root用户运行capsh --print
发现Current字段包含许多capabilities
以非root用户运行capsh --print
发现Current 字段包含零个capabilities,说明非root用户启动的进程缺省没有任何capabilities
docker容器内:
root用户运行capsh --print
发现Current 字段包含14个capabilities,比宿主机上少了一些,对宿主机的/etc/shadow有读写权限
非root用户运行capsh --print
发现Current字段仍然包含14个capabilities,对宿主机的/etc/shadow没有读写权限
这就让我感觉有点困惑了,原本预期容器内非root用户运行capsh --print的capabilities应该为空呀,或者知道少于root用户的capabilities吧?
2021-01-07 10:33:55
user limit 是session的?每个容器及时使用相同的user id ,也不会当做累计?
User resource limits dictate the amount of resources that can be used for a particular session. The resources that can be controled are:
maximum size of core files
maximum size of a process's data segment
maximum size of files created
maximum size that may be locked into memory
maximum size of resident memory
maximum number of file descriptors open at one time
maximum size of the stack
maximum amount of cpu time used
maximum number of processes allowed
maximum size of virtual memory available
It is important to note that these settings are per-session. This means that they are only effective for the time that the user is logged in (and for any processes that they run during that period). They are not global settings. In other words, they are only active for the duration of the session and the settings are not cumulative. For example, if you set the maximum number of processes to 11, the user may only have 11 processes running per session. They are not limited to 11 total processes on the machine as they may initiate another session. Each of the settings are per process settings during the session, with the exception of the maximum number of processes.
2021-03-04 11:29:36
2022-09-08 22:30:50
$ yum install slirp4netns podman -y
We will use slirp4netns to connect a network namespace to the internet in a completely rootless (or unprivileged) way.
2022-07-22 19:32:51
2022-04-24 11:39:46
2021-03-04 14:11:51
2021-02-21 12:31:58