你好,我是柳博文,欢迎和我一起学习前端工程师的AI实战课。
上一章我们深入了解了AI和计算机视觉的基本概念,以及计算机视觉在AI领域中的应用。现在,你已经对AI有了基本的认知,并且对计算机视觉的运行原理有了深入的理解。
虽然基础理论可能稍显枯燥,但这是我们实战环节绕不开的功课。这一章我们就来学以致用,一起完成一个“AI布局助手”的工具,它可以帮助前端工程师更高效地进行页面组件识别及布局。
这节课,我们主要一起解决两个核心问题。
1.在应用实践层面,我们将通过数据增广的方式扩充训练集,解决数据量不足和数据收集困难的问题。
2.在模型理论层面,我们将通过增强数据的泛化性质,解决训练过程中可能出现的过拟合问题。
学完今天的内容,你将深入理解AI组件的划分粒度,掌握如何收集数据集,以及如何进行有效的数据增广处理等关键技能。
为什么要划分组件粒度?
当你接到一个页面需求时,是否对如何划分组件的粒度感到困扰?这对于我们前端开发同学实现页面需求,乃至做好整个项目的后期维护至关重要。
同样的道理,想要训练一个AI布局助手,它也需要先“学会”组件划分的逻辑。为了让AI能够准确地识别页面布局和组件,我们需要提供足够精确且适合AI的组件划分粒度,并基于此进行数据集的收集和制作。
这个过程中,我们需要向AI提供正确且贴合实际应用场景的数据来进行训练。这就像上一章中提到的,我们需要将正确的数据投喂到AI的大脑中,使其能够进行训练和学习。通过数据的拟合,AI将逐渐学会如何进行组件的识别和布局。
如果你对上一章的内容还有印象,那么你应该知道如何训练AI。如果你需要复习,可以回顾上一章。现在,让我们继续深入这节课的内容。
组件粒度定义
那么接下来,我们就来分析一个真实的前端页面案例,讨论并选择一个合适的组件划分粒度。
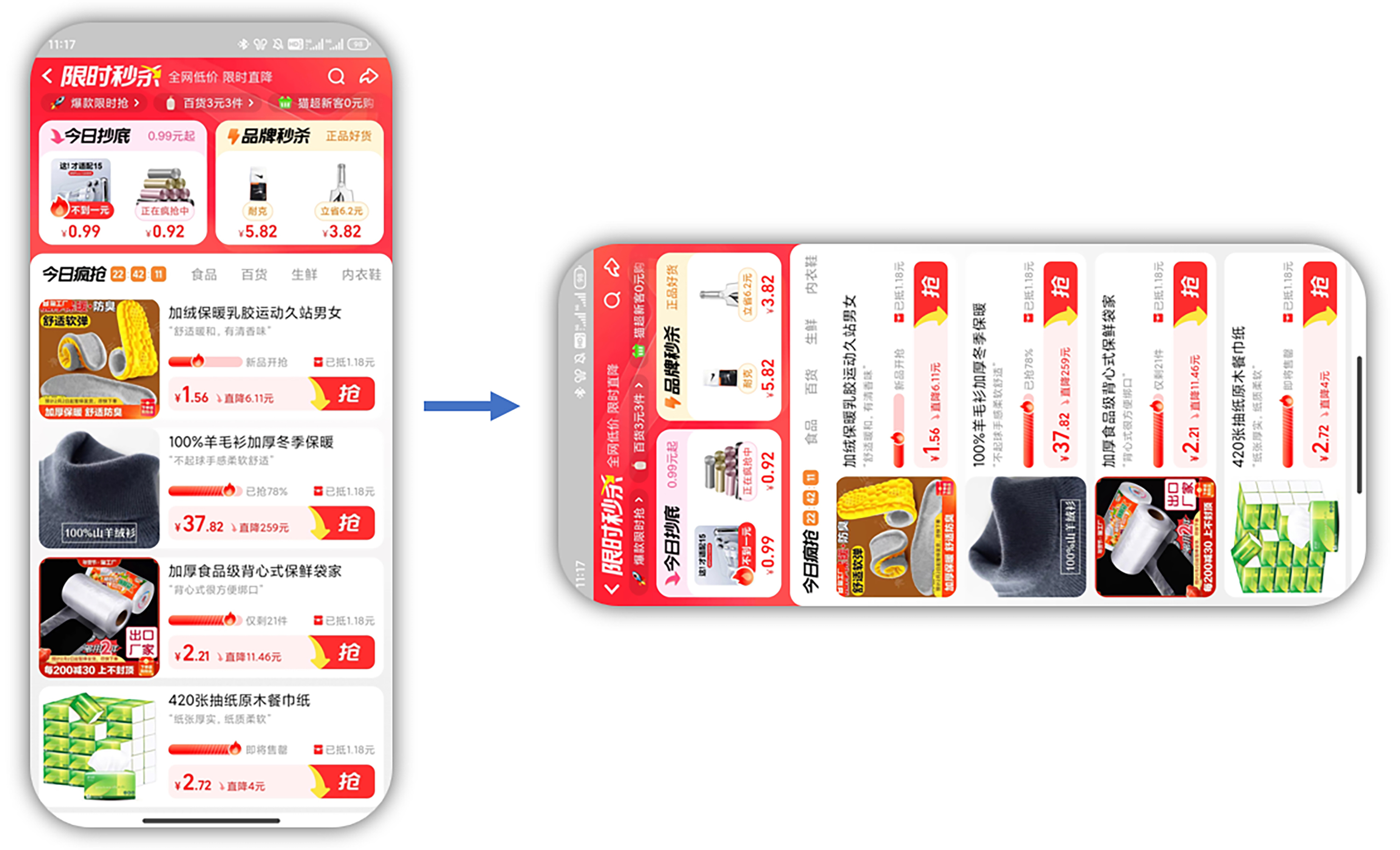
首先,我们先仔细观察一下后面这张截图,它来自手机淘宝中淘宝百亿补贴H5界面。从开发者的角度来看,这张图片展现了丰富的信息和技术。
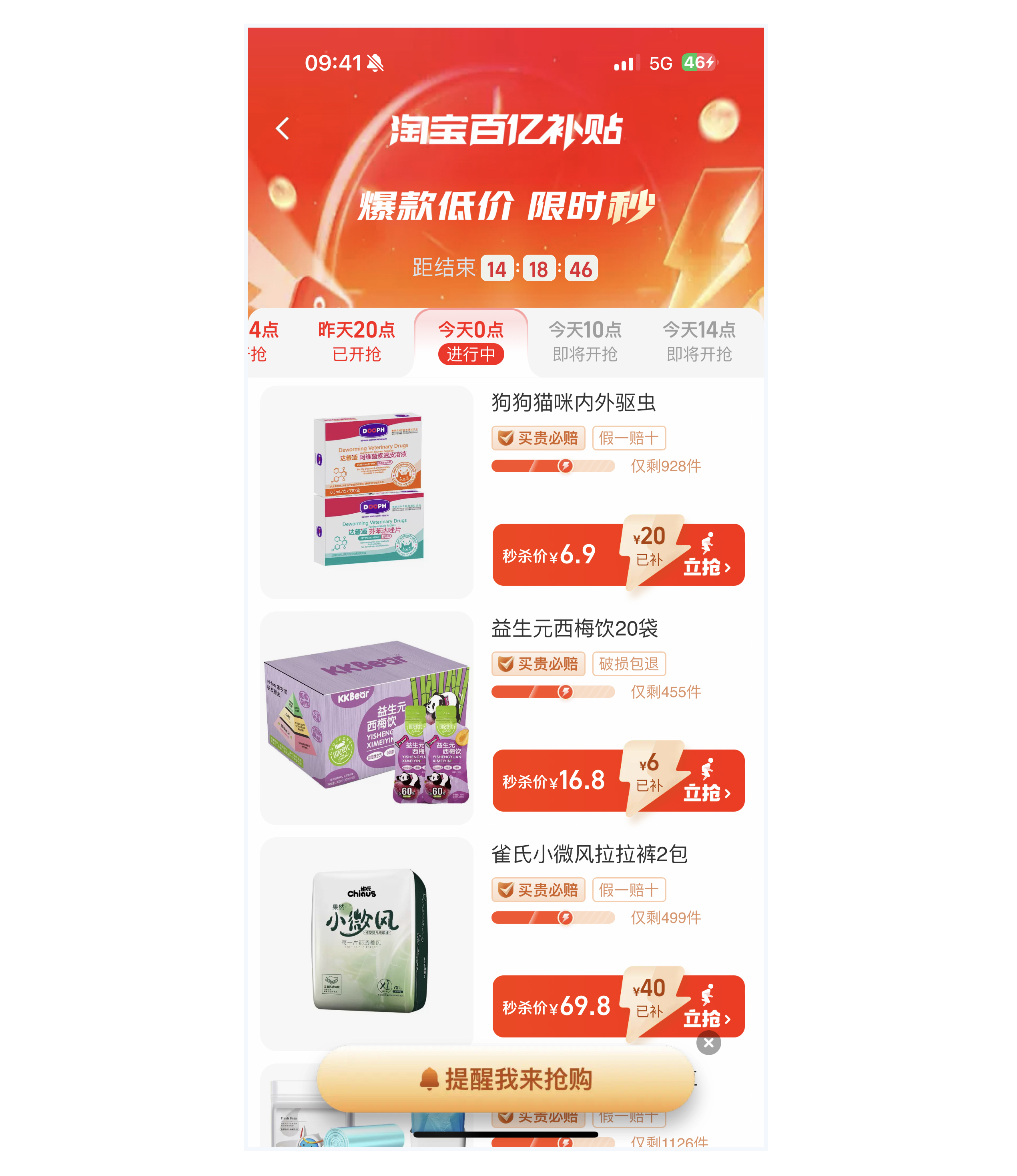
在商业应用层面,这个界面可以看作是手机淘宝的一个频道。粗浅理解的话,它就类似于实体商场中的货架。
说得更深入一些,它是基于淘宝用户特征进行人货匹配的一种方式,目的是让用户更快、更好、更便宜地找到并购买他们想要的商品。这种模式也有助于平台实现人群的精细化运营,同时提高转化率和GMV(Gross Merchandise Volume 的缩写,中文通常翻译为“总商品交易额”。它指的是在一定时间内通过电商平台进行交易的所有商品的总价值),实现双赢局面。
从页面结构上看,这是一个典型的H5的Feeds流页面,主要分为三个部分。顶部是一个搜索框,用户可以通过它直接进入主搜索页面。中部是限时秒杀等模块区域,引导用户跳转到其他频道。最下方则是主Feeds流,一个多类目切换的多tab的商品展示区域。
从组件层面来分析,这个页面包含多种组件:
- 基础组件:如输入框、按钮、图片和文字等,这些都是构成页面内容的基本元素。
- 技术组件:如搜索框、跑马灯、倒计时和tab切换等,这些组件增强了页面的功能性和用户体验。
- 业务组件:如秒杀、百亿补贴、一元专区以及主商品Feeds流等模块,这些是与业务逻辑紧密相关的组件,包含了商品信息如商品图、商品标题以及用户心智标签等。
这些组件都是AI需要识别的对象。一般来说,商业层面一个模型的好坏,很大程度上取决于数据集的优劣,因为模型原理结构已经由学术界的大咖打磨得足够好了。
基础数据集收集
确定了AI需要识别的组件粒度,我们就可以开始收集基础数据集了。
为了节约你的学习时间,让你把精力放在更核心的技术学习上,初始数据我已经为你准备好了。通过访问后面的 GitHub链接即可获取,其包含了25张各大电商APP的截图。
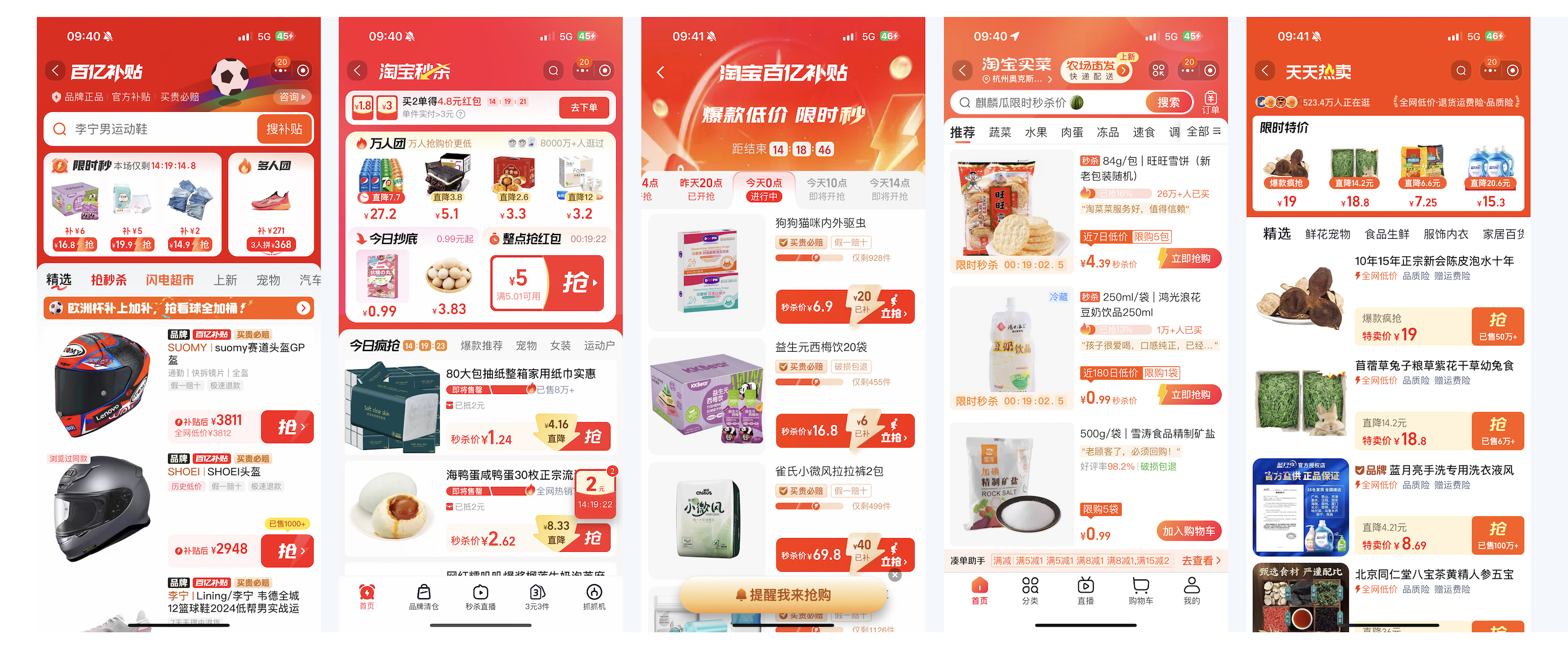
从AI的原理层面来看,数据量越大越好。更多的数据意味着AI可以学习到更多的特征,从而提高模型的泛化能力。当然,数据量的增加也会带来工作量和模型训练资源消耗的增加,对训练模型的工程师要求也更高,还会伴随类似“梯度消失”等原理问题。
要想解决此类问题,最常规的办法就是进行数据增广来提升数据的泛性。
在这里,我们将会通过数据增广技术来扩展到200+张图片。这样既充分利用了有限的数据,又可以避免过度拟合的问题。
更为重要的是,我希望教会你解决问题的方法,而不是仅仅提供答案。因此,我们鼓励你在动手实践时加入更多的原始图片,或者根据自己想要实现的更多场景进行拓展。通过这种方式,你才能更好地掌握如何运用AI技术,而不仅仅是依赖我给你提供的数据集。
数据集增广处理
经过上一章的学习,我们知道数据增广是一种技术,通过在原始数据集的基础上增加一系列的图像图形变换,从而生成更多的数据集,提高模型训练的效果。
接下来我们将会结合五个数据集增广实例,帮你轻松扩充数据集。
这里需要特别说明的是,数据集增广处理有很多实现方式,除了编码实现以外,使用Photoshop等工具也是可以的,但那样效率低,所以我并不推荐。
更推荐的图片处理方案是使用基于NodeJS的Jimp处理。相信基于JavaScript和NodeJS的处理方式,对作为前端工程师你十分友好。完整的示例代码请前往 GitHub获取。
数据增广实例1:滤波(模糊)处理
滤波处理主要是让图像变得模糊,提取图像的重要信息。常见的模糊处理有:高斯模糊,中值模糊,均值(椒盐)模糊。卷积核大小一般为奇数:(3,3)、(5,5)、(7,7)。示例代码如下:
const blurImage = (input, output, r) => {
Jimp.read(input)
.then(image => {
image.blur(r);
image.write(output);
})
.catch(err => {
console.error(err);
});
}
执行结果如下图所示。不难看到,该方法会在原图的基础上进行明显的模糊处理。这样做虽然在像素层面降低了图像细节,但是能够增加我们数据集的多样性。

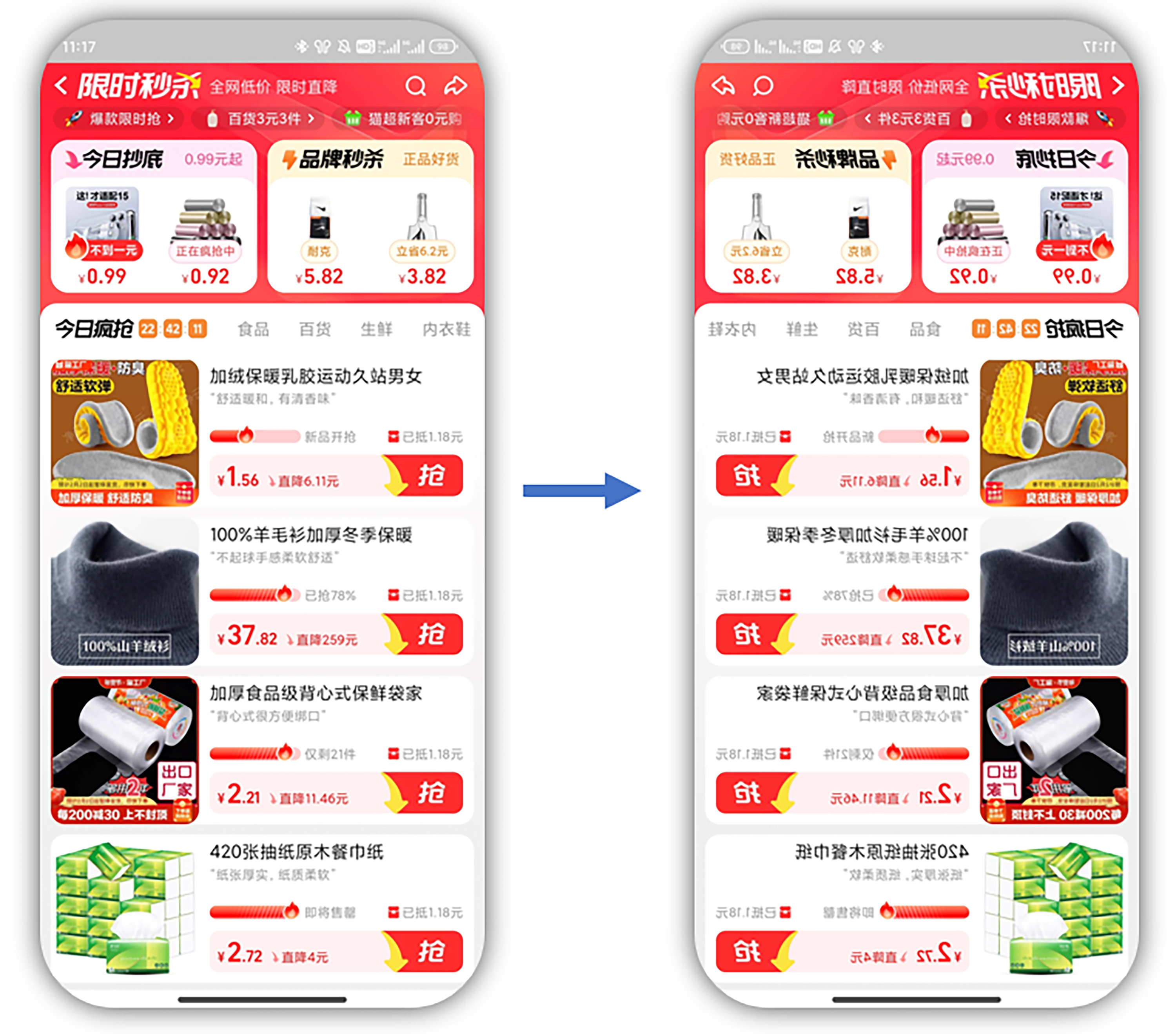
数据增广实例2:翻转处理
翻转处理就是将图像沿水平轴或垂直轴进行翻转,使得图像的左侧变为右侧,右侧变为左侧。示例代码如下:
const flipImage = (input, output, horizontal, vertical) => {
Jimp.read(input)
.then(image => {
image.mirror(horizontal, vertical);
image.write(output);
})
.catch(err => {
console.error(err);
});
}
执行结果如图所示,在原图像的基础上进行了镜像翻转,使得图像结构发生了变化。
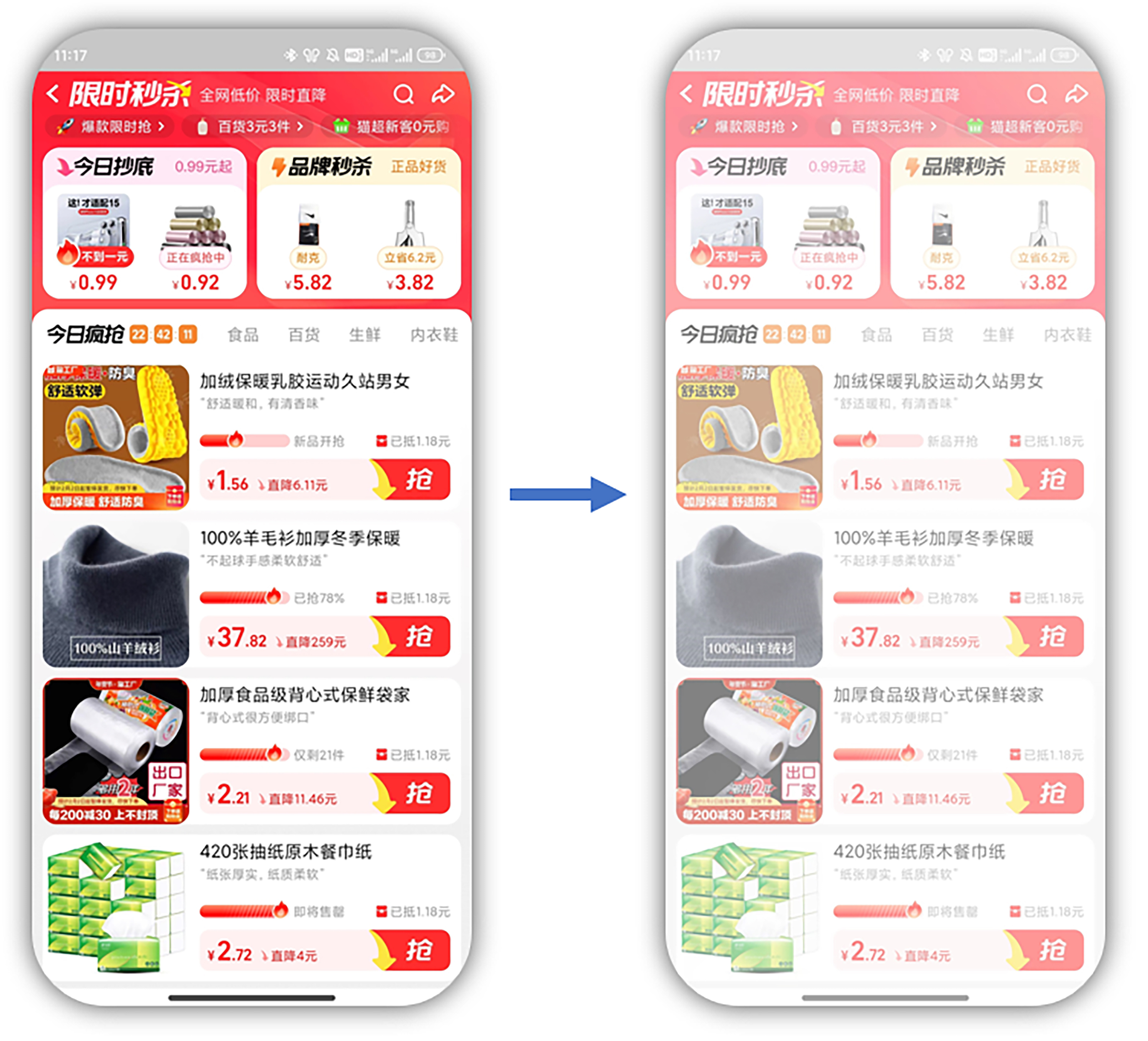
数据增广实例3:亮度调整
亮度的调整也很常见,我们可以模拟不同光照条件下的图像变化。示例代码如下:
const brightnessImage = (input, output, brightness) => {
Jimp.read(input)
.then(image => {
image.brightness(brightness);
image.write(output);
})
.catch(err => {
console.error(err);
});
}
执行结果如图所示,在原图的基础上进行了亮化处理,增强了图像的对比度。
数据增广实例4:裁剪
从原始图像中选择一个特定的区域,并将其作为新的图像。示例代码如下:
const cropImage = (input, output, x, y, w, h) => {
Jimp.read(input)
.then(image => {
image.crop(x, y, w, h);
image.write(output);
})
.catch(err => {
console.error(err);
});
}
执行结果如图所示,在原图的基础上进行了裁剪处理,降低计算复杂度的用时,增强了数据集的多样性。

数据增广实例5:旋转
此外,将原始图像按照一定角度进行旋转,也能生成新的图像。示例代码如下:
const rotateImage = (input, output, deg) => {
Jimp.read(input)
.then(image => {
image.rotate(deg);
image.write(output);
})
.catch(err => {
console.error(err);
});
}
执行结果如图所示,在原图的基础上进行水平旋转,增强了不同角度的数据集多样性。
到这里或许你会有疑惑,使用标准的数据增广方法,却产生了一些反常规的“不良”图像数据,例如,真实场景下不会存在水平旋转后的页面,为什么要产生并使用这样的数据呢?
其实,这些“不良”数据对于AI模型的训练和泛化能力的提升至关重要。
正如人类学习一样,仅仅学习好的经验并不足以让我们全面认识事物。同样地,AI模型也需要接触各种不良情况(bad case)来提高其泛化能力。通过数据增广生成这些不良数据,AI模型可以更好地应对各种复杂和异常的情况,提高其在真实世界中的表现。
因此,在数据增广的过程中,我们不仅应该关注生成与原始数据相似的新数据,还应该注重引入一些异常和不良的数据样本。这样,AI模型在训练过程中能够更好地学习和适应各种不同的数据分布和特征,从而提高其泛化能力和鲁棒性。
数据集标准适配
有了丰富的数据集,我们还要根据目标检测的一些常用标准对数据集进行随机分配。
VOC数据集是目标检测领域中广泛采用的标准数据集,具备一系列标准的规范和要求。按照VOC数据集的标准,训练、测试和验证数据集的分配比例为8:1:1。这种比例确保了数据集的随机性和代表性,有助于提高模型的泛化能力和稳定性。
总结
今天的课程告一段落,我来带你做个总结。
通过这节课的学习,我们掌握了数据集制作中的关键技术和方法,包括组件粒度的划分、数据增广的常用方法和应用,以及VOC数据集的标准和要求。这些知识将为我们进一步探索目标检测领域奠定坚实的基础。
组件的粒度划分在AI的识别能力构建中占据核心地位。我们需要根据特定应用场景和任务的需求深入分析,从技术和业务两方面审慎考虑,才能确定恰当的粒度选择。这种粒度决策直接影响到AI系统对组成元素的理解与识别精度。
而数据增广可以帮助我们以很低的成本,创造出更多的训练样本,这些样本在保持与原始数据集相似性的同时,又引入了一定的变异,从而提升模型的泛化性能、鲁棒性和预测精度。此外,数据增强还能够有效地缓解样本稀缺的问题,降低模型过拟合的风险,使模型能够更好地适应各种实际应用场景。
下一节课,我们将深入探讨数据标签制作的相关细节,敬请期待。
思考题
对图像数据进行数据增广后,图像的像素会怎么变化,同时对于AI做识别任务又有什么影响?
欢迎你在留言区发表你的看法。如果这节课对你有帮助,也推荐你分享给更多的同事、朋友。
精选留言