你好,我是柳博文。
这节课我们进入理论结合实际应用的环节,如此多的模型理论、数学知识还有公式等,它们是如何结合应用到AI模型的训练和检测过程中的呢?
这节课,我就带你一起探索那些对AI领域至关重要,同时也是前端工程师触达AI技术所必需的数学基础。其中最核心的是矩阵运算、概率论、导数、几何图形和优化理论这五项,它们在目标检测乃至所有的AI模型里都是不可或缺的。
不过你不用担心这些内容太深奥,我们的重点是了解这些数学基础在AI模型训练里如何发挥作用。
知识概览
在几乎所有的AI模型,都绕不开这五部分的知识,它们分别是矩阵运算、概率论、导数、几何图形和优化理论。
而在目标检测的模型训练和预测的过程中,这五部分也必不可少。
-
矩阵运算可以理解为输入数据的结构。
-
概率论体现在模型预测的准确率方面。
-
导数可能相对晦涩,它和用于训练模型的优化理论密切相关,我们后面慢慢展开。
-
最后因为课程涉及的AI数据图像,自然就会涉及图形学(具体指几何图形)。
那接下来我们就来展开看看这五个方面的具体作用。这里想说明,几何图形我会与矩阵运算进行结合讲解,导数会与优化理论进行结合讲解,因为它们是相辅相成的。
因为AI与数学知识密切相关,往往枯燥乏味,如果你想更加深入的学习AI,深入到AI的底层架构,就需要学习到具体的数学知识。为此我准备了选学课程,这个课程中我将上面提及的五个方面的数学知识进行了整理并补充了一些基于JavaScript的实例,可以尝试选学。
图像与矩阵运算的联系
首先我们来看看几何图形和矩阵运算是如何作用在AI模型上的。
因为课程涉及的AI模型是视觉相关,输入的数据会是整张的图像,我们先结合例子来看一下图像构成。
这里有一张极客时间首页的截图,我把它放在了画图软件中,并打开了网格显示。
你可以看到图像其实是由一个一个的小矩阵构成,而这一个小小的矩阵就是图形学中的像素点,而这个矩阵的颜色又是由GBR三原色加透明度A构成。我相信作为前端工程师的你已经很熟悉这个结构,其实就是我们每天写的CSS颜色属性值RGBA。浏览器会解析这个属性值,再交由GPU进行渲染,最终以图像的形式显示出来。
由此可知,矩阵可以很好地进行一张图像的数学表示,矩阵每一个下标值都代表着图像的一个像素点以及像素点上的数值化。这样我们就可以把用眼睛看到的图像,转换为可以进行数学计算的数值表示了。
那么同样,矩阵运算也就可以用在对图像进行计算的过程中了。在模型训练过程中,模型具有多层结构,会不断地对输入图像进行卷积运算来提取特征。这个卷积运算的过程本质其实就是矩阵的乘法。
在这个运算过程中会有一个输入,这个输入是上一层的输出,往往就是一张经过卷积运算过后的图像的矩阵表示,其次会有一个具有固定大小的卷积核,本质也是一个矩阵。将代表图像的矩阵与代表卷积核的矩阵做乘法运算得到一个运算后的图像矩阵表示,这个矩阵就拥有了更加明显的图像特征。
这里我用一张图片来展示矩阵运算是如何作用在图像上的,这样更加形象,方便你理解。
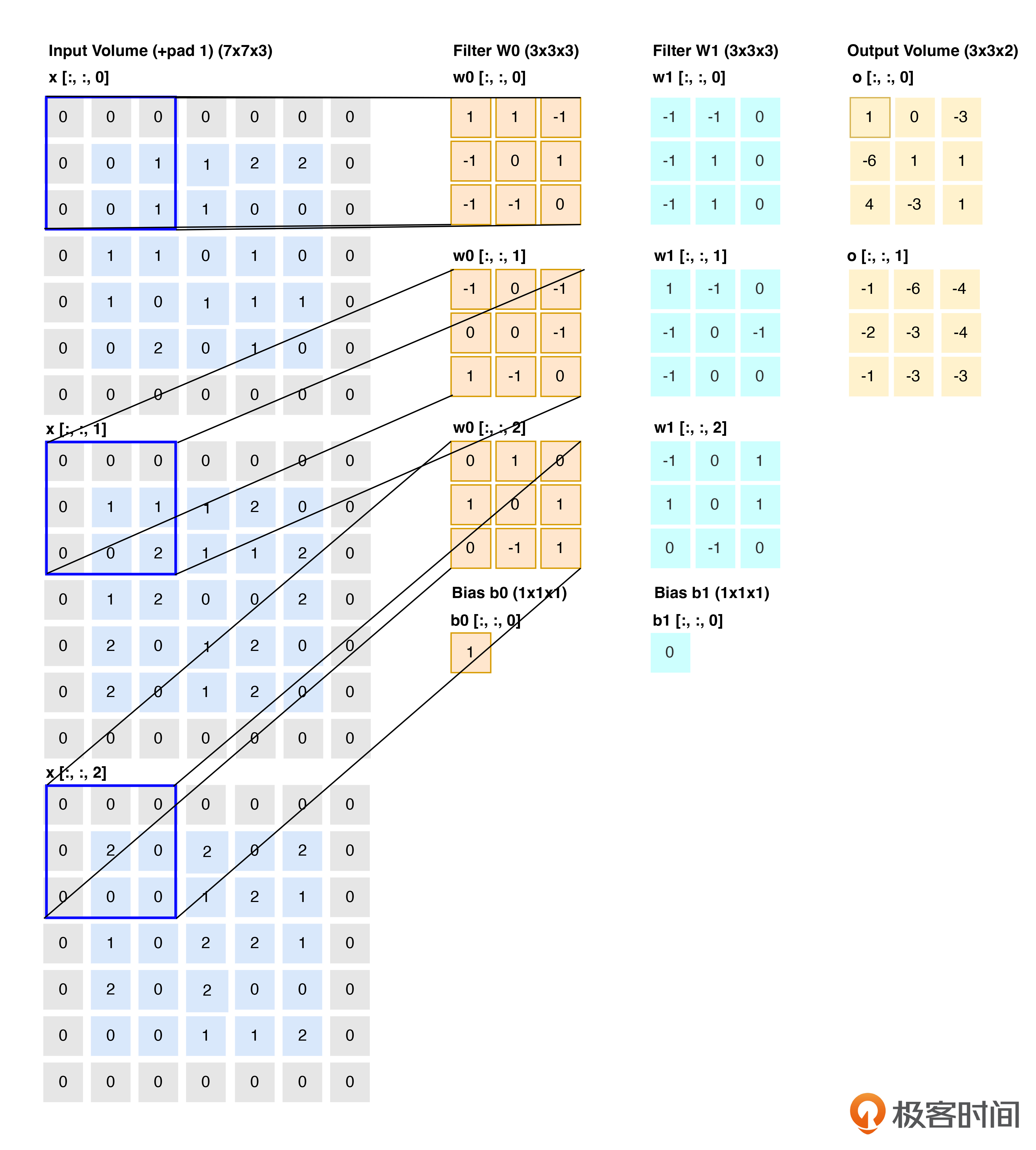
最左边Input value列是一张图像的矩阵数值表示,因为图像具有RGB三个通道(这里不引入A透明度),对应的最左上角的像素点就是RGB(0,0,0),那么我们知道这个像素点的颜就是黑色。
第二列及第三列Filter就是上面我们说到的卷积核,对每一个通道都使用一个卷积核进行卷积运算。最终我们就可以得到右侧的Output列。这个过程就展示了矩阵运算在模型训练过程中的使用。
模型训练到底做了什么
其次是概率论和导数,同样我们来看看它们是如何作用在AI模型上的,不过讨论这点之前,我们需要先了解模型训练到底在做什么样的工作。
我们知道计算机是十分擅长做重复且大量的工作的,在这个方面会比人的效率高很多。但相对而言,要让计算机做出一些类人的思考又是十分困难的。AI模型的本质就是让计算机能够在一定范围内能够像人脑一样思考。
人脑每天都在不断接收来自各种各样来源的信息输入,借此提升我们的认识、理解能力。同样对于AI,它也需要不断地被动接收信息的输入,其实这个过程就是模型训练的过程。
那么概率论到底是用在哪里呢?我想你一定有这样的体感,我们日常的开发都是基于规则的,这个规则会事先确定,并且在一定范围内是完备的。也就是说,对于一个给定的输入,一定会得到一个确定的输出。
但AI往往会对一个给定的输入,给出多种非确定的结果,并给出每种结果的“中奖”可能性,这其实就是概率,我们会选择中奖概率最高的那个结果。同样模型是否准确,也会对模型有一个评估,给出一个准确率,这也是一个概率值,可以说概率论贯穿在整个模型训练与预测的过程里。
AI模型本质是一个具有很多参数的一个大函数,这个大函数能够根据一定的输入,给出一系列具有概率的输出。这个概率值就是准确率,所以这个值我们希望越高越好。这个概率值需要我们在模型训练中寻找,这就是训练的过程,也就是让模型变得越来越聪明的过程。
那怎么寻找到更高的准确率呢?我们继续往下看。
如何让模型越来越聪明
前面我们讲了,想要提升AI模型的认知和理解能力,离不开模型训练。经过持续的训练和学习,AI模型的准确率就会越来越高,模型会就越来越聪明。你可能会问,那怎么让模型越来越聪明呢?。
我们知道模型不会像人一样具有自主接收信息和思考的能力,需要被动地接收信息,同时需要被动接受这个信息背后的结论。例如,我向模型输入一张小狗的图像,还需要告诉模型这是一张小狗的图像,这样模型在接收到下一张小狗图像的时候,才能预测这是一只小狗并给出一个概率值。
这里有一个真实值和预测值的概念。那么如何让模型越来聪明,从数学角度(或者说概率论层面)看,就是让预测值和真实值不断接近。
通常我们会设计一个合理的目标函数,这个目标函数一般会参考过往模型或论文上相似任务的目标函数原型,再加以修改。然后,在更改后的目标函数基础上,采取优化方法不断进行循环计算,来优化预测值和实际值之间的差距。因此,这个目标函数的值越小越好。其中每一轮计算过程中用到的运算就是求导。
同时,这里不得不提到优化理论里面的梯度下降了。梯度下降就是这样一个迭代优化算法,用于寻找目标函数(如损失函数)最小值的问题。其核心思想是沿着目标函数梯度(函数在某一点的最陡峭方向)的反方向逐步调整参数,直到找到函数值最小的点。
这个过程是有一定步骤的:
- 初始化参数:给模型参数一个初始值。
- 计算梯度:对当前参数下的损失函数计算梯度,梯度指向损失函数增大的最快方向。
- 更新参数:按照梯度的负方向,以一定的学习率(步长)调整参数。
- 重复迭代:重复步骤2和3,直到满足停止条件。
最后,当达到一定的停止重复条件(如:梯度接近0迭代次数达到预设值,或损失函数变化极小)时,训练停止。这个时候的AI模型就达到了在一定范围内的最聪明程度了,也就是模型的预测准确率会比较高。
那么梯度下降方法有哪些呢?比较常用的两个方法是批梯度下降和随机梯度下降。
批梯度下降(BGD)在每次迭代时,会计算整个训练数据集上的损失函数关于模型参数的梯度,然后根据这个梯度更新参数。这意味着每一步更新都是全局最优的方向,收敛稳定。这种方式计算成本高,但计算效率低,不适合大规模数据集。
随机梯度下降(SGD)在每次迭代时,仅随机选取一个样本来计算梯度并更新参数,因此每一次更新都朝着减小该样本损失的方向。虽然每一步可能不是全局最优方向,但多次迭代后,整体趋向于最小化总体损失,这么做计算速度快,适合大数据集,但收敛过程可能会更加动荡。
BGD通常更准确地估计梯度,但计算成本较高;而SGD则具有较低的计算成本和较快的收敛速度,但优化过程可能不稳定。在实际应用中,我们通常会根据数据集的大小、计算资源和优化需求来选择合适的梯度下降算法或其变体。
在后续实践环节中,模型训练的迭代优化方法会更多地使用到BGD。至于BGD和SGD的更多细节知识和基础实现,有兴趣的话你可以结合选学课程(第8节课)了解更多细节。
总结
这节课程告一段落,让我们一起来做一个总结吧。
在AI模型训练过程中,涉及了五项不可或缺的知识点,分别是矩阵运算、概率论、几何图形、导数和优化理论。
矩阵运算在AI模型训练中通过对图像进行卷积运算提取特征,利用矩阵表示图像和卷积核进行乘法运算,从而得到具有明显特征的图像矩阵,这是模型学习图像特征的关键步骤。
概率论和导数在AI模型训练中至关重要,概率论用于处理非确定性输出和评估模型准确率,导数通过梯度下降法指导模型参数优化,以提高预测准确性。批梯度下降和随机梯度下降则是优化过程中的两种关键方法,分别适用于不同的数据集规模和计算资源情况。
课后问题
为了优化AI模型,让模型具有更高的准确率,模型使用了什么优化方法,除了课程中讲到的方案,你还知道什么其他的优化方法么?
欢迎你在留言区发表你的看法。如果这节课对你有帮助,也推荐你分享给更多的同事、朋友。
精选留言
2025-06-22 22:17:37
2025-03-30 22:29:30
2024-11-06 23:08:58