你好,我是柳博文。欢迎和我一起学习前端工程师的AI实战课。
从这节课开始,我们就正式进入这门课程的学习了,正如开篇词说的那样,课程整体更加注重实践。我将和你一起学习AI结合前端的创新实践,并动手完成最小化的可运行实例,让你切身感受到AI在前端领域的魅力和巨大潜力。
在后续的实践过程中,我们不仅要用AI的原理知识和技术,为了完成工程链路的部分,还需要选择出恰当的前端框架和工程链路开发工具,课程里会用到 React(^18.0.0) 以及 NodeJS(^20.15.1)。因为课程的核心主题是AI+前端,所以,今天我们先来了解一下后续会用到的相关知识和技术算法。
课前准备/框架选择
课程中我选择了React-18作为实践部分的前端框架。众所周知,React和Vue是国内使用占比较高的框架。
同时,课程实践部分涉及到代码的自动生成。因此,文件的操作是必不可少的,需要用到具有服务器开发功能的库或者框架。那么,选择NodeJS就再合适不过了。
至于前端框架和实现工程链路的库,你可以使用自己更合熟悉和擅长的框架,不必拘泥于React和NodeJS,课程讲解的是一些创新的想法和解决方案的实践。但使用和课程同样的技术框架和库会更加省心和方便。
那么,接下来我们一起来复习一下React和NodeJS的必要知识点,以及课程中我们会使用到的技术原理和库。
前端基础库 React
React由脸书开发并开源,是一个能够高效构建动态的用户界面的JavaScript库,注意React是一个库,而不是一个框架。
脸书团队的设计理念是将React作为一个核心的Core来进行开源,使得大家都能够在这个核心core的基础上,自行定制一些特性功能。
我们这就来看看React的一些基础设计及原理,首先是React的重要设计。
React的重要设计
在我们第三章讲AI布局助手的实践时,我们将会充分使用React的单向数据流、虚拟Dom等特性来自动完成代码的生成和实时预览。我们一起来看看React的一些重要细节。
首先是声明式编程,React采用声明式编程范式,使得构建交互式UI变得更加直观。开发者只需描述应用在各种状态下应该如何呈现,React就会自动管理所有UI更新。在实践章节中,我们通过借助React的这个特性就能节约不少精力,只需要关注生成的数据,以及通过数据自动构造出来的代码。
其次是组件化,React会通过通过组件化的方式来构建UI,每个组件代表了页面上的一部分UI。这使得代码更加模块化,易于维护和复用。第三章的实践就是围绕组件识别来展开。
然后是虚拟DOM概念,这是一个编程概念,通过这个概念,React在内存中创建了一个DOM树的副本。每当应用的状态变化时,React都会在虚拟DOM上进行操作,而不是直接操作浏览器的DOM。然后,React会计算出虚拟DOM与当前DOM之间的最小差异,并仅将这些差异应用于真实的DOM上,这让开发变得更加高效,同时也提高了页面性能。
最后是单向数据流,React强调单向数据流的概念。在React中的数据以及状态的变化只能影响子组件,不直接影响父组件,这使得数据流向清晰,易于理解和调试。
React的重要组成部分
复习并理解了React的重要设计,我们一起来看看React18的重要组成部分以及各部分是如何协同工作的。这里有一张简化的架构流程图,这里不会完全展开讲,只会提及几个和课程有关的点。
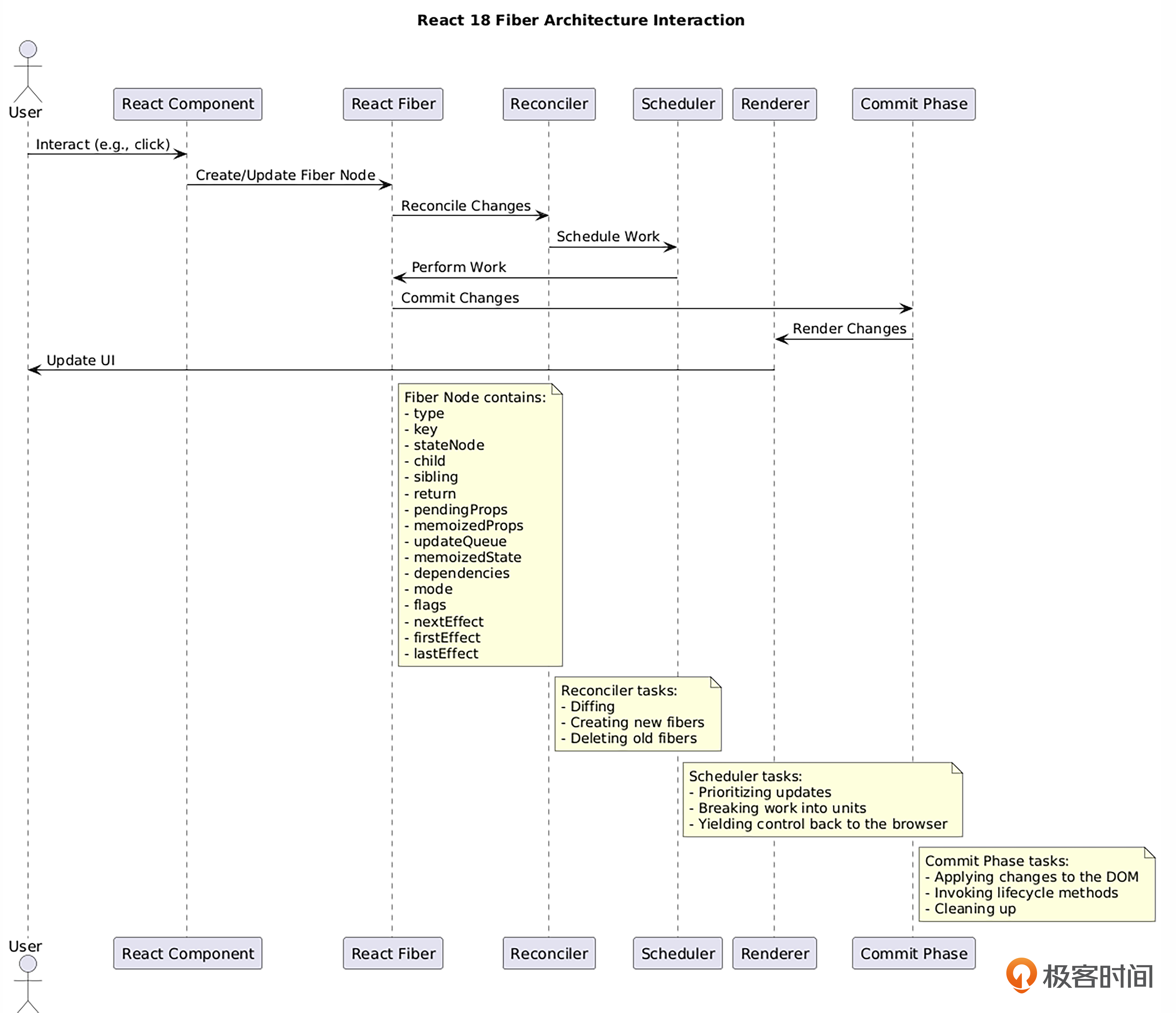
首先是React元素和组件,React元素是React应用的最小单位,是对一个UI单位的轻量级描述。React元素通常通过JSX语法创建,然后使用React.createElement()方法进行返回。组件则是构建React应用的基础构成,可以是类组件或函数组件。组件接收props作为输入,并返回用于描述UI部分的React元素。
其次是虚拟DOM,它是React元素的内存表示。React使用虚拟DOM来优化UI的更新过程。通过比较新旧虚拟DOM树的差异(称为“diffing”),React可以找到实际DOM需要进行的最小更新,再以最快的速度和最低的开销完成DOM的更新。
然后是Reconciler,它是React的核心算法,负责协调或对比新旧虚拟DOM树的差异,并计算出实际DOM需要进行的更新。Reconciler的工作方式可以是同步的,也可以是异步的(在React 16中引入的Fiber架构下)。这里开始涉及React的部分核心源码设计,感兴趣的同学可以阅读React16及以后版本的React源码。
React的源码是一个复杂且高度优化的代码库,它包含了许多重要的部分,每个部分都承担着特定的职责,并且相互之间紧密协作,来提供React的核心功能。
然后我们再简单了解一下Fiber架构。Fiber是React 16版本开始引入的一种新的内部架构,为了提高React的性能(特别是在动画、布局和手势等需要高响应性的应用中)。Fiber架构使得React可以将渲染工作分割成小的单位,实现任务的中断、重用和优先级排序。Fiber的实现原理可以参考协程原理。
React实现了一套自己的事件处理系统,它在React元素上定义的事件处理器会被统一管理。React的事件系统确保了跨浏览器的一致性,并且通过事件委托机制提高了性能。
Hooks是React 16.8引入的新特性,它允许在函数组件中使用状态和其他React特性(如生命周期钩子)。Hooks提供了一种更简洁直观的方式来编写组件,同时保持了组件逻辑的可复用性。
接下来,我们看一下这些重要组成部分是如何相互联系、协同工作的。
组件通过返回React元素来描述UI,而React元素构成了虚拟DOM树。当组件状态变化时,Reconciler负责比较新旧虚拟DOM树的差异,并计算出需要对实际DOM进行的最小更新。
Fiber架构改进了Reconciler的工作方式,使其能够更高效地处理UI更新,特别是在大型应用和动画等场景下。
事件系统为React组件提供了一种处理用户交互的方式,组件可以通过定义事件处理函数来响应用户的操作。
工程链路NodeJS
Node.js是一个开源且跨平台的JavaScript运行时环境,它允许开发者在服务器端运行JavaScript代码。
Node.js是基于Google的V8 JavaScript引擎构建的。V8引擎负责编译JavaScript代码到本地机器代码,这使得Node.js能够以接近原生的速度执行代码。Node.js的标准库提供了一系列的异步I/O原语,这些都是非阻塞的,确保了Node.js在处理网络请求、文件操作等I/O密集型任务时足够高效。此外,Node.js通过模块系统支持CommonJS规范,使得组织和复用代码变得更简单。
Node.js的出现极大地丰富了JavaScript的应用场景,除了用在客户端开发,服务器端编程时用起来也很高效,可以满足我们课程实践部分的需要。
使用FS模块实现文件变化更新
Node.js在服务端的编程应用中,监听文件内容的变化是一项常见的任务,尤其在开发需要实时更新或响应文件变化的应用时。Node.js的fs模块提供了几种方法来实现这一功能,其中fs.watchFile和fs.watch是最常用的两种。
首先是fs.watchFile方法,通过轮询的方式来检查文件的变化。这意味着它会在一定的时间间隔内读取文件的元数据(如修改时间),并比较其变化。虽然这种方法在不同操作系统上表现相对一致,但因其轮询机制,可能会导致较高的CPU和内存占用,尤其是在监听大量文件时。
在这个示例中,每当example.txt文件的修改时间发生变化时,就会打印出“文件已修改”的消息,并读取文件的新内容。
const fs = require('fs');
const filePath = './example.txt';
// 使用 fs.watchFile 监听文件变化
fs.watchFile(filePath, { interval: 1000 }, (curr, prev) => {
// 检查文件的修改时间是否发生了变化
if (curr.mtime !== prev.mtime) {
console.log('文件已修改');
// 读取文件内容
fs.readFile(filePath, 'utf8', (err, data) => {
if (err) {
console.error('读取文件时发生错误:', err);
return;
}
console.log('文件新内容:', data);
});
}
});
相比fs.watchFile,fs.watch方法更加高效,因为它依赖于底层操作系统的文件变化通知机制(如果可用)。这通常意味着更低的CPU和内存占用,并且能更及时地响应文件变化。然而,需要注意的是,fs.watch在某些操作系统或特定情况下可能不可用或表现不一致。
const fs = require('fs');
const filePath = './example.txt';
// 监听文件变化
fs.watch(filePath, (eventType, filename) => {
if (eventType === 'change') {
console.log('文件已更改:', filename);
// 读取文件内容
fs.readFile(filePath, 'utf8', (err, data) => {
if (err) {
console.error('读取文件时发生错误:', err);
return;
}
console.log('文件新内容:', data);
});
}
});
console.log('正在监听', filePath);
在这个示例中,每当 example.txt 文件发生变化时(如内容被修改),就会触发回调函数,并打印出“文件已更改”的消息和文件的新内容。
两者都可以用来实现实践部分的文件内容变化监听,我们对比一下它们的不同和适用环境。
-
fs.watch的性能通常优于fs.watchFile,但在某些操作系统上可能不可用或表现不一致。 -
在使用
fs.watch时,确保监听路径存在且文件或目录的权限设置正确。 -
监听大量文件或目录时,可能会遇到性能问题,尤其是使用
fs.watchFile。 -
监听文件内容变化时,如果需要精确控制(如仅当文件内容实际变化时才触发),可能需要结合文件内容比较(如 MD5校验)来实现。
通过上面的学习和示例演示,我们就能够使用Node.js的 fs 模块来监听文件内容的变化,并在实践部分的应用程序中根据需要进行相应的处理。
为什么要引入 MD5
我们先来看一段第三章实践部分用于监听文件内容变化的部分实现代码:
const fs = require('fs')
const md5 = require('md5');
const path = require('path');
const process = require("child_process");
let preveMd5 = null;
let fsWait = false;
const filePath = path.join(__dirname, '/AILayout/');
fs.watch(filePath, (event, filename) => {
if (filename) {
if (fsWait) return;
fsWait = setTimeout(() => {
fsWait = false;
}, 100)
var currentMd5 = md5(fs.readFileSync(filePath + filename))
if (currentMd5 == preveMd5) {
return
}
preveMd5 = currentMd5
console.log(`${filePath}${filename} updated`);
process.exec('npm run codegen', (error, stdout, stderr) => {
if (!error) {
// 成功
} else {
// 失败
}
});
}
})
可以看到使用了FS模块的watch方法,对比文件内容前后变化时,比较的是经过MD5进行hash计算后的hash串,而不是直接对比的内容。这是为什么呢?
想弄明白这个问题,就不得不了解一下Hash和基于Hash原理的MD5算法。
首先是 Hash,通常被称为“哈希”或“散列”,是一种将任意长度的输入(如字符串、文件内容等)通过特定的算法转换为固定长度(如128位、256位等)的输出值的过程。这个输出值就是所谓的“哈希值”或“摘要”。Hash算法的设计目标是使得不同的输入产生不同的哈希值,并且从哈希值几乎无法反推出原始输入(即“单向性”)。
MD5(Message-Digest Algorithm 5)是一种广泛使用的哈希函数,它产生一个128位(16字节)的哈希值,通常用32位的十六进制数表示。MD5算法由Ronald Rivest在1991年设计,最初是为了与RSA加密技术一起使用,但后来由于其高效性和易用性,被广泛应用于文件校验、数字签名等领域。
其实,在文件内容变化的监听过程中,直接比较文件内容可能会非常耗时、占用大量资源,特别是当文件很大时。而使用Hash算法,我们可以将文件内容转换为一个相对较小的哈希值,然后只比较这些哈希值。如果哈希值不同,那么文件内容一定不同;如果哈希值相同,则文件内容在很大程度上是相同的(尽管存在极小的哈希碰撞概率,但在实际应用中几乎可以忽略不计)。
因此,通过引入Hash算法,我们可以高效、快速地检测文件内容的变化,而无需对文件本身进行全面的读取和比较。这对于需要实时响应文件变化的应用来说尤为重要,如代码编辑器、版本控制系统、文件同步工具等。
总结
React作为一个流行的现代前端库,它拥有单向数据流、虚拟Dom、Diff算法、事件系统等设计,使得React能够快速高效第实现高性能的前端页面,尤其是庞大的SPA(single page application)应用。同时,得益于Fiber算法的出现,将渲染工作分割成小的单位,实现任务的中断、重用和优先级排序,再一次极大提高了React应用的运行时性能。
NodeJS作为以JavaScript为基础编程语言的服务端平台,对前端工程师十分友好。在其提供的核心模块中FS的功能强大,使用频率高。使用FS.watchFile可以很好地监听文件内容的变化。MD5是一类hash算法,可以将不定长的字符串编码为定长字符串,这样可以更加高效、快速地检测文件内容的变化,而无需对文件本身进行全面的读取和比较。
思考题
MD5算法在今天这节课里的作用是什么,你还知道它的哪些应用呢?
欢迎你在留言区和我交流互动,如果这节课对你有启发,也推荐分享给身边更多朋友。
精选留言
2024-10-30 19:37:11
2024-10-12 11:45:59